Generate a robots.txt File
Learning Objectives
After completing this unit, you’ll be able to:
- Describe an external search engine’s primary functions.
- List what’s contained in a robots.txt file.
- Describe two ways to generate a robots.txt file.
- Explain how to verify a robots.txt file.
- Describe how to configure caching when you generate a robots.txt file.
External Search Engines
Brandon Wilson, Cloud Kicks merchandiser, wants to learn about the robots.txt file so he can use it to improve his external search rankings and minimize extraneous hits to his site. He begins with external search engines, which have three primary functions.
-
Crawl: Search the Internet for content, looking at the code/content for each URL they find.
-
Index: Store and organize the content found during the crawling process. Once a page is in the index, Google can display it as a result of relevant queries.
-
Rank: Provide the pieces of content that best answer a searcher’s query with results ordered by most relevant to least relevant.

A crawler looks for a /robots.txt URI on your site, where a site is defined as an HTTP server running on a particular host and port number. There can only be one /robots.txt on a site. From this file, the crawler figures out which pages or files it can or cannot index using the Disallow parameter. Merchandisers like Brandon use this file to limit what’s indexed to the important information and prevent overloading their sites with irrelevant requests.

Let’s go along with Brandon as he explores what’s in a robots.txt file and how to generate and verify them.
What’s in a robots.txt File?
When a crawler visits a website, such as https://www.cloudkicks.com/, it first checks for the robots.txt file located in https://www.cloudkicks.com/robots.txt. If the file exists, it analyzes the contents to see what pages it can index. You can customize the robots.txt file to apply to specific robots, and disallow access to specific directories or files. You can write up to 50,000 characters to this file in Business Manager.
File Format
Here’s the basic format of a robots.txt file.
User-agent: [user-agent name] Disallow: [URL string not to be crawled]
Here’s an example.
User-agent: man-bot Crawl-delay: 120 Disallow: /category/*.xml$ Disallow: /mobile User-agent: Googlebot Disallow: /cloudkicks-test=new-products/
A URI that starts with a specified value is not visited. For example:
Disallow: /help — disallows /help.html and /help/index.html.
Disallow: /help/ — disallows /help/index.html, but allows /help.html.
Search Refinement URLs
If you already have entries in the robots.txt, it’s best practice to add these lines at the bottom to disallow search refinement URLs. External search engines don’t need to index them and could consider these URLs as duplicate content, which hurts SEO.
# Search refinement URL parameters Disallow: /*pmin* Disallow: /*pmax* Disallow: /*prefn1* Disallow: /*prefn2* Disallow: /*prefn3* Disallow: /*prefn4* Disallow: /*prefv1* Disallow: /*prefv2* Disallow: /*prefv3* Disallow: /*prefv4* Disallow: /*srule*
Crawl Rate
Set the Googlebot crawl rate toLow in the Google Search Console, because Google ignores the crawl-delay line in robots.txt. The term crawl rate means how many requests per second Googlebot makes to a site when it’s crawling it, for example, 5 requests per second.
You can’t change how often Google crawls your site, but if you want Google to crawl new or updated content on your site, you can request a recrawl.
Prevent Crawling
When a web crawler visits a website, such as https://www.cloudkicks.com/, it first checks for the robots.txt file and determines if it’s allowed to index the site. In some cases you don’t want it to. For example, Brandon doesn’t want web crawlers looking at his development and staging instances because they aren’t intended for shoppers.
Here’s a sample robots.txt file that prevents web crawlers from indexing the site:
User-agent: *# applies to all robots Disallow: /# disallow indexing of all pages
Storefront Password Protection
Developers on one of the Cloud Kicks sites use the storefront password protection feature as they get ready for site launch. This feature limits storefront access to people involved in the project. This limit also prevents crawlers and search engine robots from indexing this storefront and making it available to search engines. It protects both dynamic content, such as pages, and static content, such as images.
Create a robots.txt File
You can use almost any text editor to create a robots.txt file. For example, Notepad, TextEdit, vi, and emacs can create valid robots.txt files. Don't use a word processor; word processors often save files in a proprietary format and can add unexpected characters, such as curly quotes, which can cause problems for crawlers. Make sure to save the file with UTF-8 encoding if prompted during the save file dialog.
For the robots.txt file to be used by Salesforce B2C Commerce, Brandon must first set up his hostname alias. Then, he can generate his robots.txt file in Business Manager.
When caching is enabled on an instance, he must invalidate the static content cache for a new robots.txt file to be generated or served. When caching is disabled on a staging instance, B2C Commerce immediately detects any changes to the robots.txt file.
Use Business Manager to create a robots.txt file for one or more sites individually. The application server serves the robots.txt file, which is stored as a site preference and can be replicated from one instance to another. Brandon uses this method for existing sites to allow crawling only for the production instance—and not for development or staging.
Here’s how to create a robots.txt file in Business Manager.
- In Business Manager, click App Launcher, and then select Merchant Tools | site | SEO | Robots.
- Select the instance: Staging
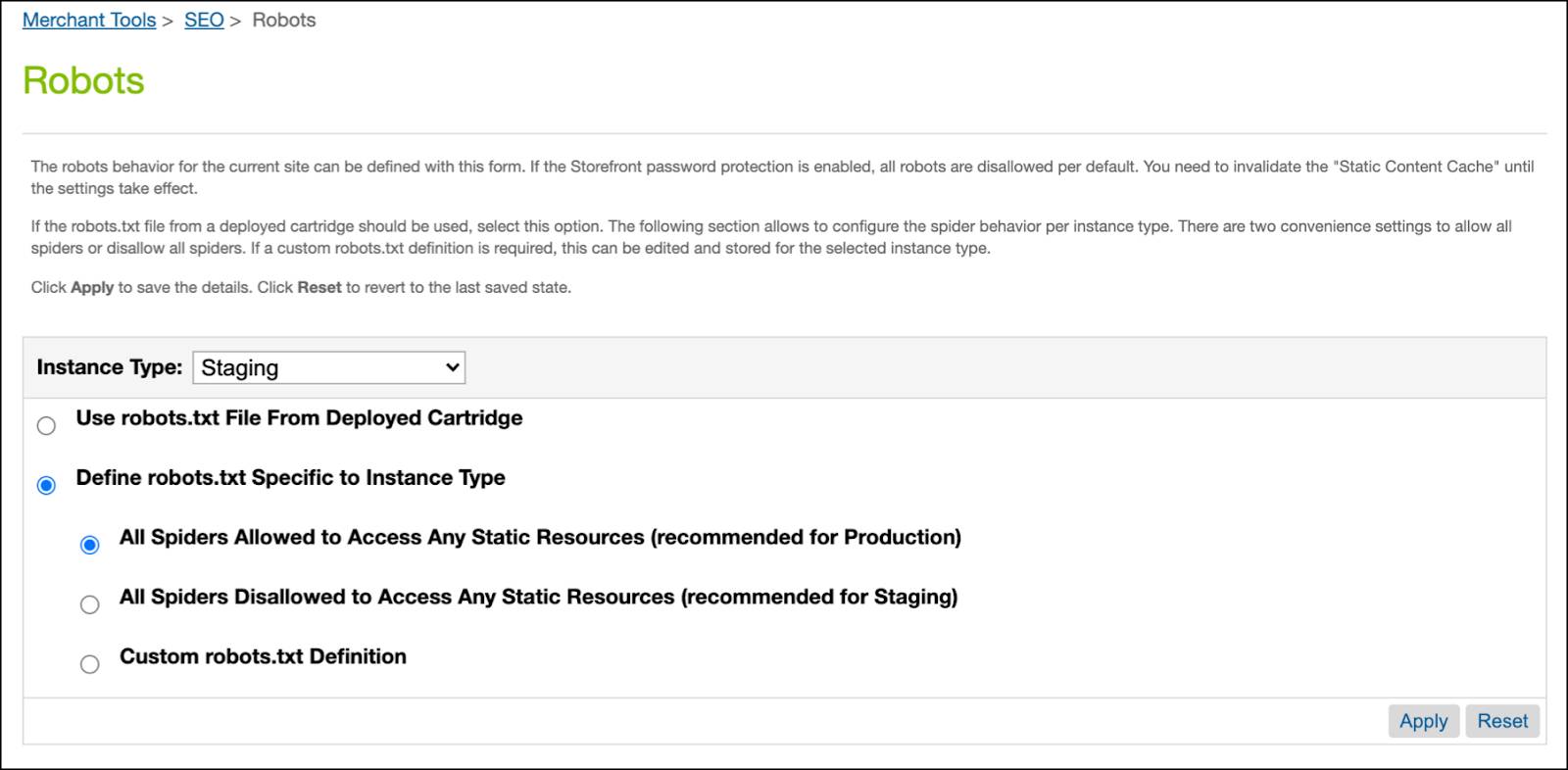
- Select Define robots.txt Specific to Instance Type.
- Select the type of access: All Spiders Allowed to Access Any Static Resources
- Use this setting for a production instance if you want it to be crawled and available to external search engines.
- Click Apply.
- Invalidate cache.
- Select Administration > Sites > Manage Sites > site > Cache tab.
- In the Static Content and Page Caches section, click Invalidate.
- Select Administration > Sites > Manage Sites > site > Cache tab.
For access type, you can also select:
-
All Spiders Disallowed to Access Any Static Resources
Use this setting for a development or staging instance if you do not want them to be crawled and available to external search engines.
-
Custom robots.txt Definition (recommended)
Use this setting if you want to control which parts of your storefront are crawled and available to external search engines.
To use a robots.txt file on a production instance, create it on a staging instance and then replicate site preferences from staging to production.
Upload a robots.txt File
If you create a robots.txt file in an external file, you must upload the file to the cartridge/static/default directory in a custom storefront cartridge on your B2C Commerce server. Use your integrated development environment (IDE), such as NodeJS or Eclipse.
You must replicate the robots.txt file from instance to instance via code replication because the cartridge/static/default is cartridge-specific, not site-specific.
Verify a robots.txt File
To verify the robots.txt file is correctly placed:
- Invalidate the static content page cache (if necessary).
- In your browser, enter the hostname of the instance, a slash, and then
robots.txt. For example:http://www.cloudkicks.com/robots.txt - If you get a blank page, the file isn’t there.
Let’s Wrap It Up
In this unit, you learned what’s in a robots.txt file and how to generate, upload, and verify it. You also learned how to prevent crawling. Earlier in this module, you explored XML sitemaps and how to notify search engines about them. Now take the final quiz and earn a new badge.
References
-
Salesforce Help: Generate a Robots.txt File
-
External Site: Create a robots.txt file
-
External Site: Google Help: Ask Google to recrawl your URLs
-
Salesforce Help: Storefront Password Protection and Login
-
Salesforce Help: Salesforce B2C Commerce Hostname Aliases