Prepare Your Data for Profile Unification
Learning Objectives
After completing this unit, you’ll be able to:
- Identify data quality issues that can interfere with customer matching and identity resolution.
- Explain when normalization, filtering, or enrichment is required before profile unification.
In the previous unit, you followed Luna as she determined the need for profile unification and identified fields that can be used in matching. She now needs to prepare her data to ensure effective profile unification.
Identify Data Issues That Can Interfere with Customer Matching
Even when identifier fields such as email address, phone number, or mailing address appear populated and unique, they can still be unreliable for accurate customer matching.
Matching problems often occur when:
- Identifiers are stored in inconsistent formats.
- Placeholder or shared values are used.
- Important identifiers are missing.
- Obsolete or low-quality values remain in the data.
The issues listed above can lead to:
- False negatives, where related records are not connected.
- False positives, where different customers are incorrectly matched together.
Before you configure matching or identity-resolution rules, you should evaluate whether customer identifiers are reliable, standardized, and sufficiently meaningful to support trusted customer recognition.
Inconsistent Formats Within a Single Field
Rachel has interacted with Northern Trail Outfitters (NTO) across ecommerce, loyalty, and customer service experiences for several years. As a result, her loyalty identifier is stored in different formats across systems.
- NTO-00458291
- 458291
- LOYALTY-458291
At first glance, these values might appear different. However, they all represent the same loyalty account. Depending on the profile unification solution being used, inconsistent formatting like this can reduce matching accuracy or require additional preparation before reliable matching can occur.
For example, some solutions rely on exact or near-exact comparisons and can require identifiers to be normalized into a consistent format before matching. Other solutions, such as Data 360 Identity Resolution, can automatically recognize some expected formatting variations.
When organizations understand how identifiers are stored across systems, they can determine whether normalization is required before profile unification begins.
Matching issues generally fall into two categories.
Profile Unification Issue |
Description |
Example |
|---|---|---|
False negative |
The system fails to connect records that belong together. Related records remain separate even though they represent the same customer. |
Rachel’s loyalty number appears as NTO-00458291 in one system and 458291 in another. If the system cannot recognize these values as equivalent, Rachel’s interactions remain disconnected. |
False positive |
The system incorrectly combines records that should remain separate. |
Two different customers have shipped orders to the same resort, a popular destination for NTO customers. Shared contact point causes the system to incorrectly combine their records into a single customer profile. |
At NTO, Luna reviews how identifiers such as loyalty IDs, phone numbers, email addresses, and digital identifiers are captured across systems before configuring matching rules. This helps ensure the organization uses reliable identifiers that support accurate customer recognition rather than introducing incorrect matches or fragmented customer history.
Multiple Fields Storing Similar Contact Information
The previous example focused on inconsistent formatting within a single identifier field. Another common challenge occurs when similar customer information is distributed across multiple fields within the same object.
At NTO, customer contact information is stored across multiple email and phone fields on the Contact object. Over time, different teams, applications, integrations, and business processes introduced additional fields to support specific operational needs.
For example, one Contact record for Samuel Wilson contains:
- samuel.wilson@syntdata.starkenterprises.com in the Email field
- sam.wilson@syntdata.gmail.com in the Personal Email field
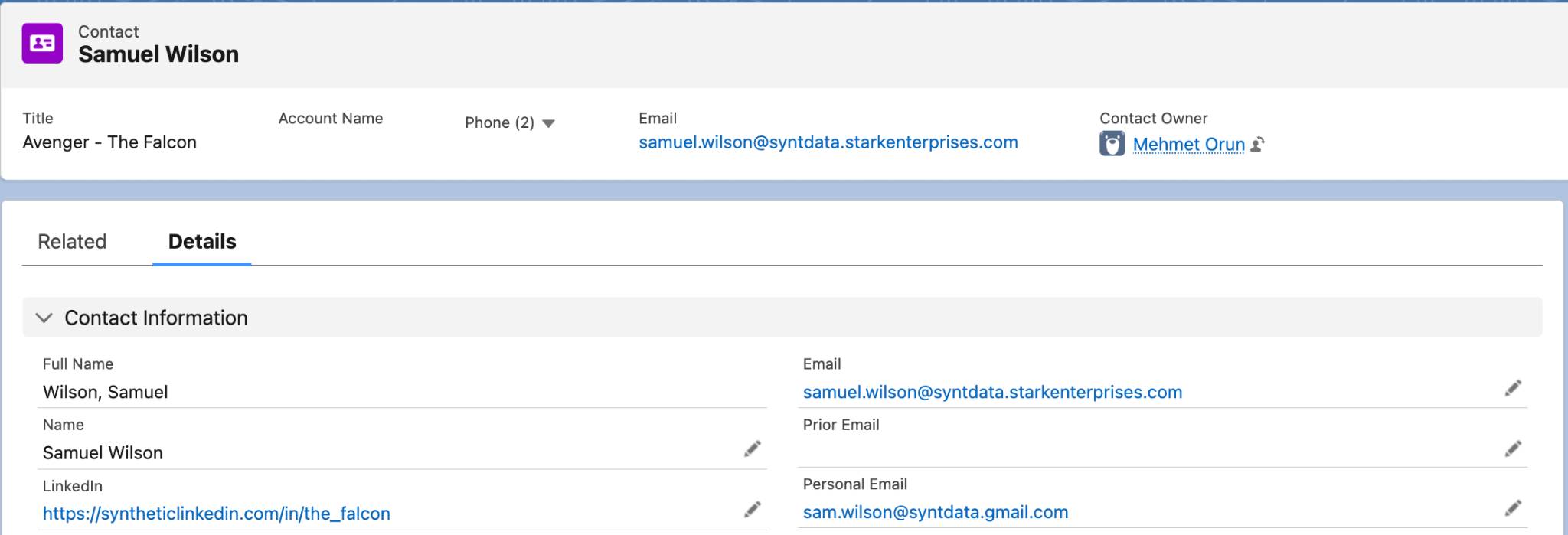
A second Contact record for Sam Wilson contains:
- sam.wilson@syntdata.gmail.com in the Email field
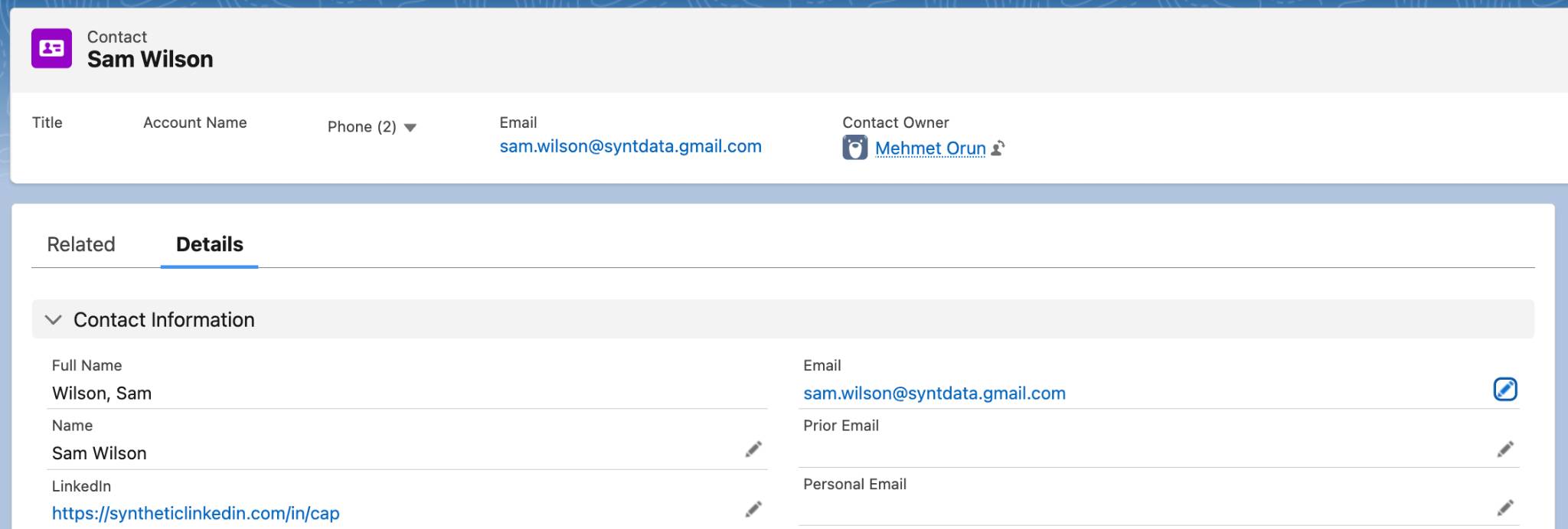
Even though both records share at least one email address, the value appears in different fields in each record. If a matching process compares Email field to Email field, it can miss the relationship between the records. The same issue can affect automated routing, marketing engagement, and customer notifications when different systems rely on different email or phone fields.
Normalization helps reduce this risk by making similar information available through a common access point. For example:
- Email values from multiple fields can be organized as email contact points.
- Phone values from multiple fields can be organized as phone contact points.
- Contact points can include context, such as type, source, status, and last verified date.

In a Data 360 implementation, this means mapping fields suitable for matching to the appropriate objects in the Individual and Contact Point data models. This lets identity resolution, segmentation, routing, and engagement processes evaluate contact information consistently, instead of relying on whichever field happened to store the value in the source system.
In this example, the customer profile is separated into standardized contact-point objects rather than storing all information directly on the Individual record.
The Individual object stores core customer identity information, while related contact-point objects store reusable communication details, such as email addresses and phone numbers. Each contact point is connected back to the individual through a shared Contact Id.
This structure associates multiple email addresses or phone numbers with the same customer without requiring additional fields on the main profile record. It also standardizes how contact information is stored across systems, making it easier to compare, match, validate, and manage customer contact points consistently. This approach supports identity resolution and engagement processes.

Normalization does not mean every value must be formatted the same way before matching. The amount of standardization required depends on the solution. For example, Data 360 Identity Resolution can recognize expected formatting differences, such as variations in phone number formats. However, teams still need to decide which fields to use, how to represent similar information, and which values to exclude as unreliable.
The goal is not to use every available field. The goal is to make trusted contact information available in a consistent structure so that matching, routing, and engagement processes can use the right identifiers for the right purpose.
Values That Can Negatively Impact Matching
Even when organizations select the correct fields for matching, the values within those fields can still reduce matching accuracy.
Some values appear frequently but do not represent meaningful customer identifiers, such as shared or placeholder values.
For example, Luna reviews the most frequently occurring values in NTO’s Email field and discovers entries such as na@na.com and none@none.com. These values do not help identify or distinguish one customer from another. When placeholders or shared values appear frequently in identifier fields, they can also cause false positives by incorrectly matching unrelated customers together.

Luna uses profiling insights such as top value frequency, found in the Populated Values column when sorted in descending order, to identify outliers and determine whether data needs to be cleansed at the source, or at a minimum, excluded or filtered prior to matching.
Determine Whether Enrichment Is Required
In some cases, customer identifiers alone might not provide enough information to confidently connect related records. Additional reference points from data enrichment—such as change-of-address data, company hierarchy information, or validated contact-point data—can help improve matching accuracy and customer recognition outcomes.
Let’s Recap
With a clear understanding of how customer data can become fragmented—and how profiling helps identify trusted identifiers, unreliable values, and normalization needs—NTO is ready to evaluate different approaches to profile unification.
In the next unit, you explore how organizations use CRM duplicate management, Data 360 profile unification, and master data management (MDM) solutions to create more complete and contextual customer understanding.