了解 Data 360 中的搜索索引类型
学习目标
完成本单元后,您将能够:
- 描述 Data 360 支持的搜索索引。
- 确定要为您的用例构建哪个搜索索引。
在 Data 360 中使用搜索对 AI 进行落地训练
基于特定于客户的数据对 AI 进行落地训练,可提升 Salesforce Platform 中各类应用程序、分析与自动化工具中生成式 AI 的价值。AI 落地训练可通过非结构化、半结构化或结构化数据实现。通过使用用户查询检索相关的 CRM 数据,以对 AI 模型进行落地训练,Agentforce、Tableau 以及 Flow Builder 等应用程序可确保根据用户意图对输出进行微调。在 Data 360 中使用搜索可确保为您的团队和客户提供准确和相关的 AI 生成的内容、更深入的分析见解以及更高效的自动化工作流程。
Data 360 支持为您知识库中的所有数据(包括非结构化数据)构建搜索索引。Data 360 支持以下搜索索引类型。
- 向量搜索索引
- 混合搜索索引
- 丰富搜索索引
要在 Data 360 中构建搜索索引,您需要将数据导入 Data 360。Data 360 接收非结构化数据,将其映射到标准数据模型对象 (DMO) 或非结构化数据模型对象 (UDMO),并从这些数据中创建有意义的内容区块。然后,Data 360 创建向量嵌入,以构建搜索索引,帮助应用程序理解与数据的在语义和词汇上的相似性。

选择搜索索引类型
在确定哪种搜索索引类型最适合您的特定用例和数据集之前,让我们首先深入了解一下这些搜索类型之间的区别,以及哪种类型的搜索查询能带来最相关的响应。
向量搜索索引
向量搜索,也称为语义搜索,旨在根据给定的搜索查询,检索语义相似的数据(或数据区块)。这些数据也可包含视频、音频及通话脚本。向量搜索检索是通过对数据进行分块、创建向量嵌入,并搜索那些与搜索查询具有高度语义相似性的向量嵌入来完成的。
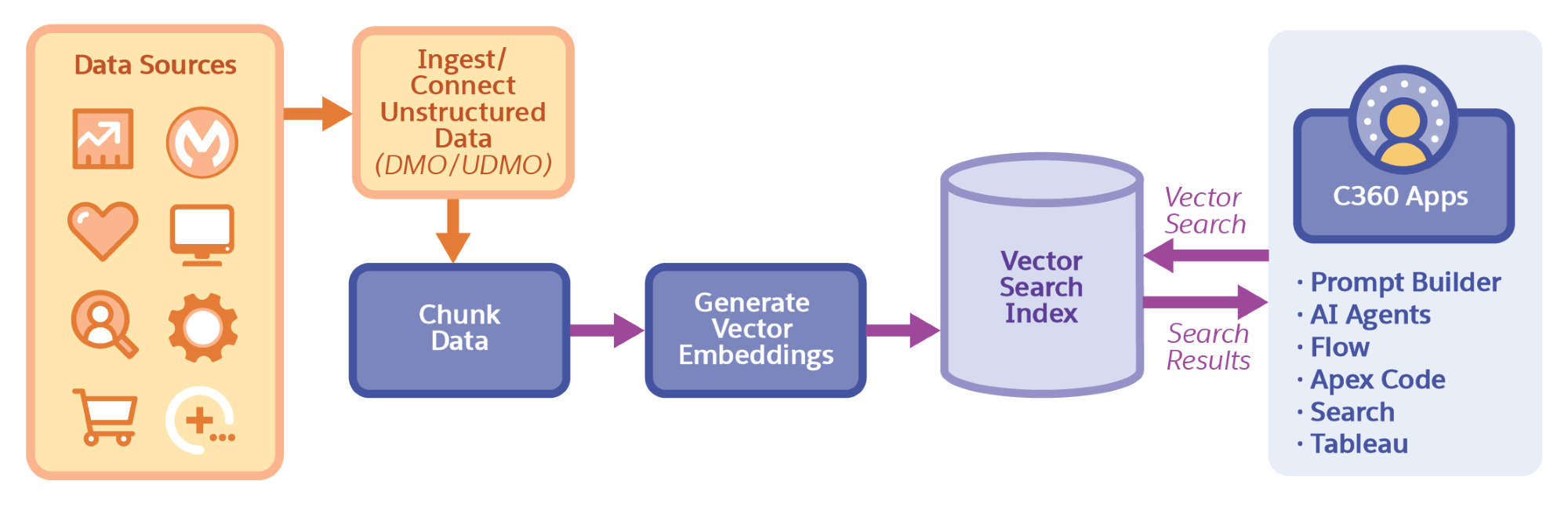
向量搜索适用于用户通过长格式搜索查询寻找通用信息的场景。搜索查询会检索向量搜索分数较高的数据,此分数与最高的语义匹配度相关联。
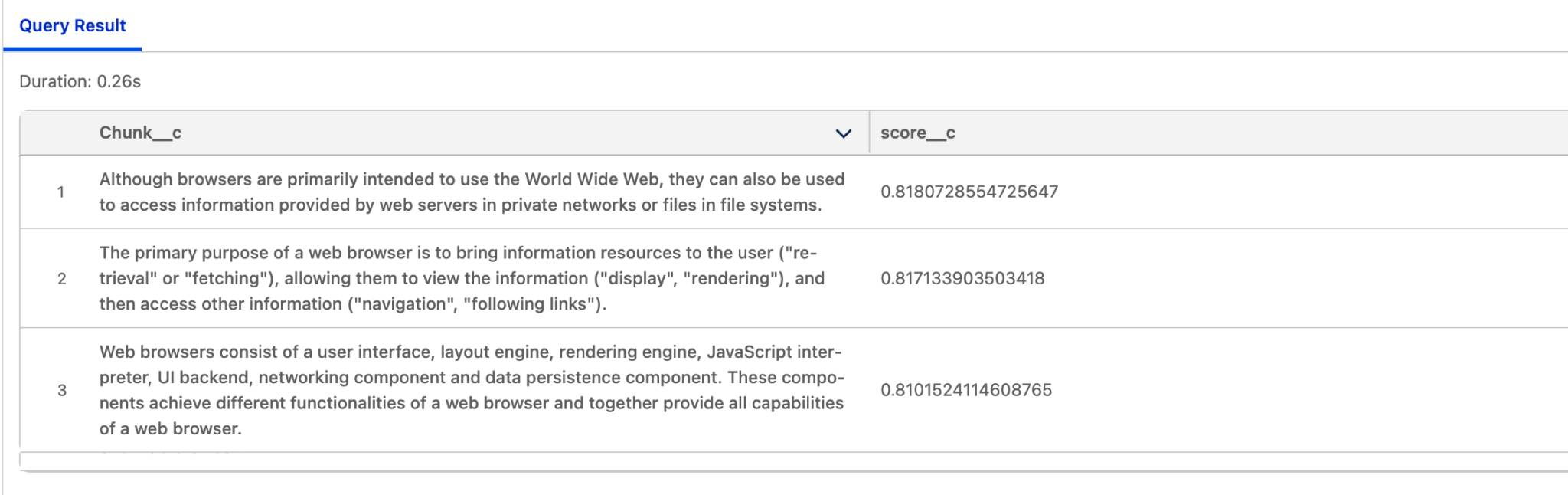
例如,以下是一个查询,旨在查找关于 Google Chrome 浏览器工作原理的信息。搜索查询会检索向量搜索分数最高的区块,此分数与搜索查询最高的语义匹配度相关。
查询:
select c.Chunk_c, v.score_c from vector_search(table(WikiArticle_c_vector_search_2_index__dlm), 'how does Google Chrome internet browser work', '', 100) as v join WikiArticle_c_vector_search_2_ chunk_dlm as c on v.SourceRecordId_c=c.RecordId_c ORDER by v.score_c desc limit 3;
结果:
混合搜索索引
混合搜索将语义感知向量搜索优势与处理域词汇的关键词搜索功能相结合。它合并了从两种搜索类型检索到的信息,然后通过融合排序器功能对结果进行排序,显示最相关的信息。
默认混合搜索融合排序器功能经过内部基准优化,以适应各种基于搜索的任务。训练和评估数据基于从 Einstein 搜索及 Einstein 搜索答案等生成式 AI 应用程序实际捕获的查询。

对于包含特定搜索术语的长格式搜索查询,混合搜索是一个绝佳选择。搜索查询会检索兼具高关键词搜索分数(与精确的关键词匹配相关联)和高向量搜索分数(与最高的语义匹配度相关联)的数据。这将检索到具有高混合搜索分数的数据,此分数与最相关的搜索结果相关联。
对于向量搜索中使用的相同查询示例,关键词搜索通过提升更相关内容的排名位置,为 LLM 提供更好的落地训练。
查询:
select c.Chunk__c, h.hybrid_score__c, h.keyword_score__c, h.vector_score__c from hybrid_search(table(WikiArticle_c_hybrid_search_2_index__dlm), 'how does Google Chrome internet browser work ?', '', 100) as h join WikiArticle_c_hybrid_search_2_chunk__dlm as c on h.SourceRecordId__c=c.RecordId__c ORDER by h.hybrid_score__c desc limit 2;
结果:

丰富搜索索引
利用额外的元数据和问题区块丰富标准内容区块,以增强用于检索增强生成 (RAG) 的向量搜索索引或混合搜索索引。
自动从内容区块中提取元数据(包括关键词、实体、主题概述、内容解答的问题以及内容摘要)可以显著提高检索准确率。这种由 LLM 生成的丰富内容可作为人工管理的替代方案,使 AI 智能体在回答问题时更容易识别出最相关的信息。
要进行使用,您需要在创建向量搜索索引或混合搜索索引时启用丰富区块。在构建搜索索引时,Data 360 会生成三个新的区块:一个包含原始区块文本的普通区块、一个包含元数据文本的区块,以及一个包含该区块可回答问题的区块。在 AI 模型中,为丰富搜索索引创建检索器。在 RAG 和智能体工作流程中,将检索器用于提示模板和智能体。
现在,我们来看丰富的混合搜索索引的示例查询,该查询会在结果中包含丰富区块。
查询:
SELECT
"RagFileUDMO_Enriched_chunk"."Chunk__c" AS "Chunk",
"searchFunc"."hybrid_score__c" AS "hybrid_score__c",
"searchFunc"."SourceChunks__c" AS "SourceChunks__c",
"searchFunc"."ChunkProcessingType__c" AS "ChunkProcessingType__c",
"RagFileUDMO_Enriched_chunk"."ChunkType__c" AS "ChunkType__c"
FROM (
SELECT * FROM hybrid_search(TABLE("RagFileUDMO_Enriched_index__dlm"),
'What is the purpose of Multi-Terrain Select system?', 'ChunkProcessingType__c
= ''PLAIN''', 10)
UNION
SELECT * FROM hybrid_search(TABLE("RagFileUDMO_Enriched_index__dlm"),
'What is the purpose of Multi-Terrain Select system?', 'ChunkProcessingType__c
= ''QUESTION''', 10)
UNION
SELECT * FROM hybrid_search(TABLE("RagFileUDMO_Enriched_index__dlm"),
'What is the purpose of Multi-Terrain Select system?', 'ChunkProcessingType__c
= ''METADATA''', 10)
) AS "searchFunc"
INNER JOIN "RagFileUDMO_Enriched_chunk__dlm" AS "RagFileUDMO_Enriched_chunk"
ON "RagFileUDMO_Enriched_chunk"."RecordId__c" = "searchFunc"."RecordId__c"
INNER JOIN "RagFileUDMO__dlm" AS "RagFileUDMO"
ON "RagFileUDMO"."FilePath__c" =
"RagFileUDMO_Enriched_chunk"."SourceRecordId__c"
AND "RagFileUDMO"."KQ_FilePath__c" IS NOT DISTINCT FROM
"RagFileUDMO_Enriched_chunk"."KQ_SourceRecordId__c"
ORDER BY "searchFunc"."hybrid_score__c" DESC结果:

在 Data Cloud 中使用此功能会消耗 Flex 额度。有关详细信息,请参阅丰富索引的计费注意事项。有关详细信息,请联系您的客户经理。
总结
在 Data 360 中构建搜索索引,以利用您组织的非结构化、半结构化或结构化数据对 AI 进行落地训练。
选择最适合最终用户和应用程序搜索查询的搜索类型。如果用户查询主要关于一般信息或者查询内容较长(五个单词以上),则向量搜索足以满足此场景。当用户查询包含上下文内容(通常是较长的查询)时,向量搜索可提供相关结果。
要获取将语义搜索匹配和关键词搜索匹配相结合的最准确、最相关的查询结果,需创建混合搜索索引。
通过添加额外的元数据和问题区块来丰富搜索索引,在检索准确率显著提升的情况下,其带来的可量化价值足以抵消使用大语言模型 (LLM) 生成额外区块所产生的较高成本。