映射所需对象
学习目标
完成本单元后,您将能够:
- 认识 Customer 360 数据模型组件。
- 描述个人、联系点和当事人对象。
- 确认身份解析规则集的映射要求。
Customer 360 数据模型组件
为了进一步了解数据和身份概念的要求,我们需要回顾一下 Customer 360 数据模型 Customer 360 数据模型是 Data 360 采用的标准数据模型,有助于数据的互操作性。这是一种特别的说法,意味着它可以让数据在您需要的任何地方可用。了解 Customer 360 数据模型组件,可以让您更轻松地进行数据映射和创建身份解析规则集。让我们了解一下。

主题领域(一个业务目标)
Customer 360 数据模型根据业务目标将主题领域或数据模型进行分组。这些目标可能是营销或推广您的产品或为您的客户提供无缝的产品支持。数据模型主题领域可能包括一组被称为“当事人”的唯一识别码,也可以是参与数据、销售订单或产品信息。
数据模型对象,也称为 DMO(数据组)
由导入的数据流和见解在数据模型中创建的对象。DMO 可以是标准化的,也可以是自定义的,具体取决于您的业务需求。DMO 存储潜在客户、产品信息、客户信息等数据。
属性(联系人相关数据)
属性是您从不同来源了解到的关于特定联系人的独特信息。这些数据可以帮助您将个人数据链接在一起,并最终构建统一的客户简档。对于营销人员来说,这些数据点非常宝贵,因为它们可以用来创建精细化的细分。例如,您可能想向所有年龄在 25 岁以下并且喜欢举重而非跑步的联系人发送优惠券。为此,您需要将年龄和活动偏好数据导入 Data 360。

数据映射的重要性
现在您已经温习完毕,是时候认真对待了。为了创建统一简档,您必须正确地映射数据。Data 360 就像人工智能 (AI),因为它需要高质量的数据和一些人为干预才能发挥出最佳效果。
在 Data 360 中,只有将简档正确映射到个人对象和另一个元素(联系点对象或当事人识别码对象)时,系统才能将其统一。
让我们从第一个必需项(即个人对象)开始。
个人对象
个人对象最为重要,因为它包含了您所知道的关于客户的所有个人信息。而且这些数据可以来自各种各样的来源(从商务数据到社交媒体帖子)。事实上,添加的每个数据流都需要将一个字段与个人 ID 字段相连,以便创建统一个人简档。这是身份解析所必需的。
让我们再强调一次。
所有包含客户信息的数据流都需要将一个字段映射到个人对象中的个人 ID 字段上,以便使用身份解析。
所需映射和关系
在我们使用 NTO 忠诚度计划数据源的示例中,映射到个人 ID 的字段为订阅者密钥字段。个人 ID 是身份解析规则集最重要的属性。它是个人对象的主键,是进行映射和身份解析所必需的。在数据流中,无论哪个字段是该客户的唯一识别码,都应该映射到此 ID。以下是个人对象的具体映射要求和选项。
数据模型对象 |
属性 |
API 名称 |
映射到 |
|---|---|---|---|
|
个人
|
|
|
|
您还可以将客户数据中的任何其他字段映射到与个人对象相关联的标准和自定义属性。例如,映射出生日期、名字、姓氏等信息。
您不仅需要将所有客户数据映射到个人 ID 字段,还必须将数据映射到另一个对象。让我们了解一下您的选项。
联系点对象
联系点(如电子邮件、电话、地址、设备和社交媒体)都有可用于身份解析的关联对象。这些信息代表了一个人的具体信息,这些信息在不同系统中可能发生变化或者是不同的。类似于个人 ID,联系点 ID 是联系点对象的主键,是进行映射和身份解析所必需的。在数据流中,无论哪个字段是该客户的唯一识别码,都应该映射到此 ID。让我们了解一下这些对象的要求。
数据模型对象 |
属性 |
API 名称 |
映射到 |
|---|---|---|---|
|
联系点地址
|
|
|
|
|
联系点 App
|
|
|
|
|
联系点电子邮件
|
|
|
|
|
联系点电话
|
|
|
|
当事人标识对象
最后但同样重要的是当事人标识对象。当事人方识别码匹配功能使您能够使用客户自行提供的识别码。匹配当事人识别码在 Marketing Engagement 数据捆绑包中尤为重要。数据捆绑包包括具有订阅者相关数据(如参与度指标)的数据源,这些数据与订阅者 ID 相关联,同时也包括具有客户信息的数据扩展。如果您决定根据当事人 ID 进行匹配,那么还需要映射其他类型的属性。
有关其他 Salesforce 产品可用的当前数据包列表,请访问 Data 360 参考指南中的入门版数据包。
-
当事人标识 ID:类似于个人 ID 和联系点 ID,当事人标识 ID 是主键或客户数据中的主要识别码。它可以是任何唯一 ID。
-
当事人:此 ID 是一个外键,与个人对象中使用的相同。
-
当事人标识类型:对于映射来说,这是一个必填字段,但在身份解析中则是可选字段。该字段提供了关于识别码的额外信息,例如社交媒体。必须具有描述性,因为它将用于设置匹配规则。
-
标识号码:用于身份解析比较的 ID。
-
标识名称:类似于类型,此必填字段用于指定 ID 空间的名称,例如手机 ID 或 LinkedIn ID。此名称同时也在匹配规则设置中使用,因此也必须具有描述性。
-
标准和自定义属性:将客户数据中的任何其他字段映射到与当事人识别码相关联的标准和自定义属性。
让我们以使用驾驶执照作为唯一识别码的示例来说明。
当事人标识 ID |
当事人 |
当事人标识类型 |
标识号码 |
标识名称 |
|---|---|---|---|---|
100a |
10016-00001 |
驾驶执照 |
D1469256 |
CA 驾驶员 ID |
总之,以下是当事人标识所需的映射。
数据模型对象 |
属性 |
API 名称
|
映射到 |
|---|---|---|---|
|
当事人标识
|
|
|
|
当事人关系
为了在各个 ID 空间之间实现统一,当事人标识对象具有多对一的关系基数,这意味着您可以将多个当事人字段映射到同一个个人对象。在这个例子中,有三种当事人标识类型:LinkedIn、联系人 ID 以及 Agentforce Marketing 订阅者密钥。这三种类型都是可能的,这也是采用多对一关系基数的原因。
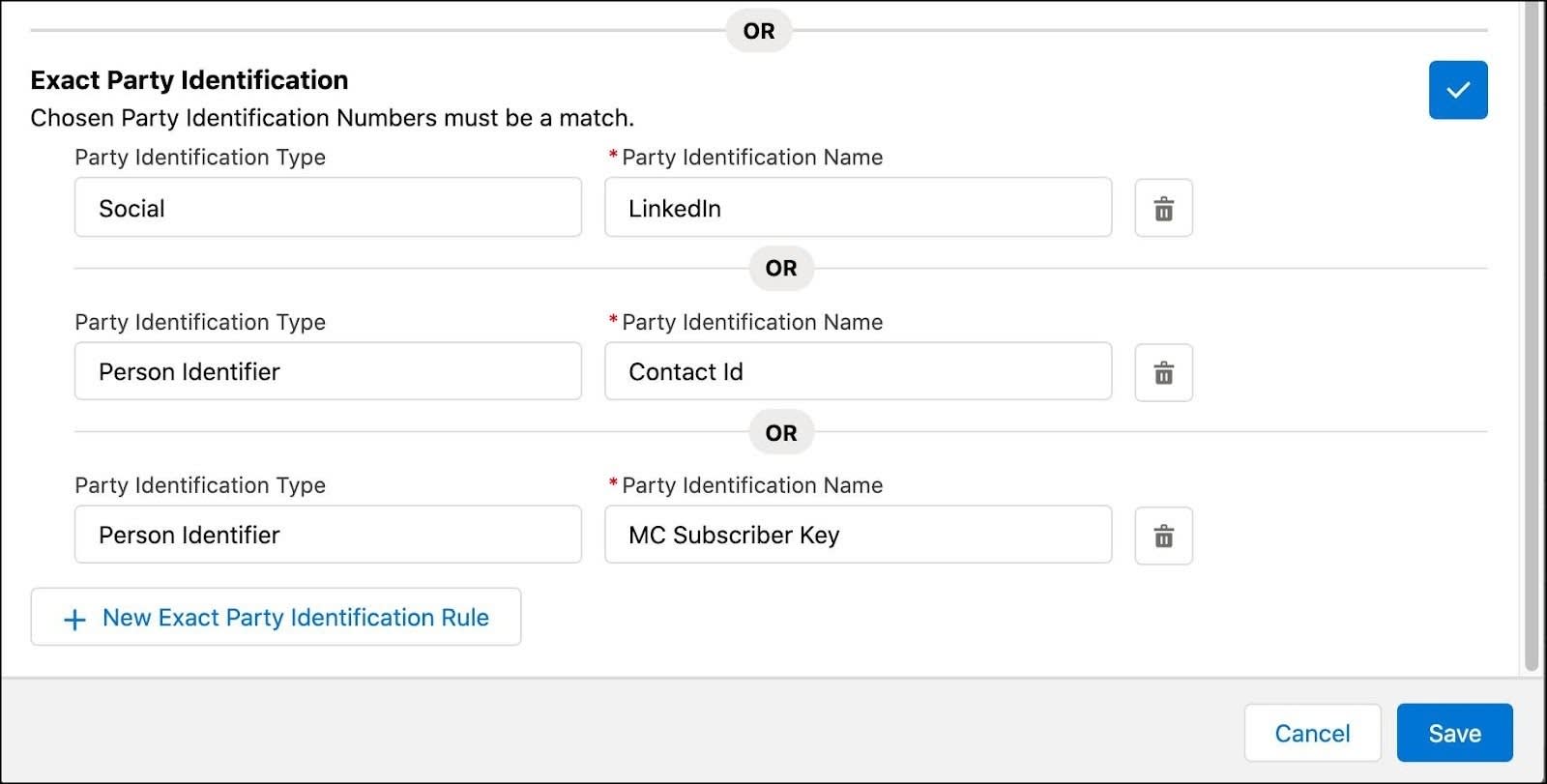
由于许多系统都使用识别码,您可以在完成映射和配置后轻松地将其添加到匹配规则中。确保记下所用的类型和名称,以便于设置。
数据映射示例
为了帮助可视化这个过程,让我们回顾一下 Northern Trail Outfitters (NTO) 数据模型中的一个数据映射示例。在这个示例中,数据流 NTO 忠诚度计划 (1) 被映射到个人对象 (2) 和联系点电话对象 (3)。NTO 创建了这个映射以便使用电话号码作为匹配规则。
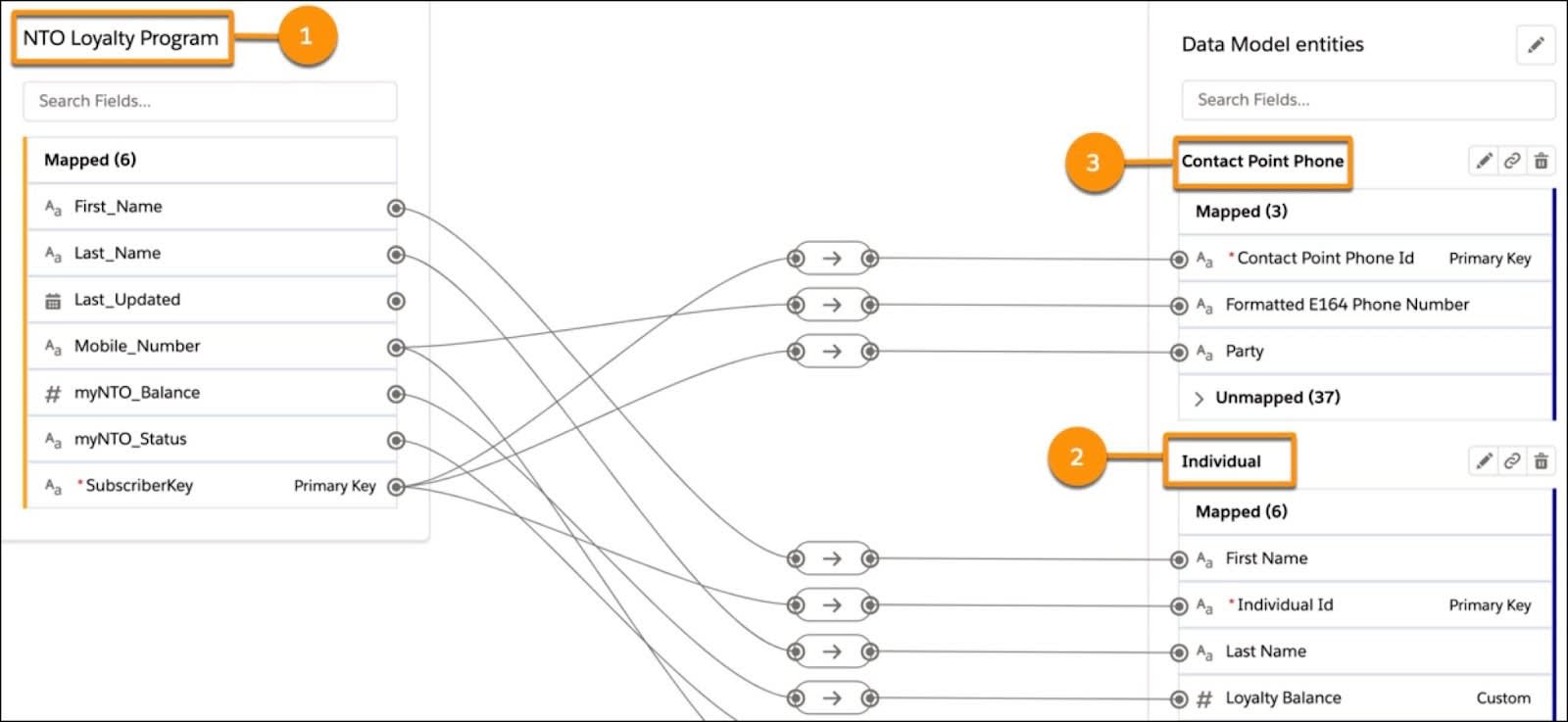
在这个映射中,有三个必需的映射(被认定为主键)。在这个例子中,这些主键是:
- 订阅者密钥
- 联系点电话 ID
- 个人 ID
还要注意,数据源中的订阅者密钥被映射到其他主键和当事人字段。为什么是当事人?因为当事人字段有助于提供数据源中的对象和主键之间的关系。
下一个:身份解析规则集
现在您已经了解了映射的重要性,在下一单元中,我们将探讨身份解析规则集的概念。
资源
- Salesforce 帮助:当事人主题领域
- Salesforce 帮助:Customer 360 数据模型:个人和联系点
- Salesforce 帮助:身份解析的数据建模要求
- Salesforce 开发人员:建模数据