估计概率
学习目标
完成本单元后,您将能够:
- 描述连续分布。
- 描述正态分布的特征。
简介
数据分布模块表明您可以用柱状图来绘制连续值的分布。现在我们来看连续分布的概念。
我们不讨论用来完成本单元中的计算的公式,不过随着您继续探索、了解和传播数据,全面熟悉这些概念可能会对您有帮助。
密度曲线
数据分布模块介绍了柱状图如何表示连续变量有限样本的分布。柱状图中每根柱子的高度与那个柱子里值的频率成正比。换而言之,柱子越高,样本里的数据点出现在那个柱子里的频率越高。

比如,上面的柱状图以英寸为单位显示 40 个人的身材分布。显然,这是一个含有限数据点的数据样本。但是,当您考虑身材这个连续变量的所有可能值时,您可以看到它可能会差别很大。我们的一生没有足够的时间来绘制包含每一种可能的身材值柱子的柱状图。对于任何连续变量来说,都是如此。
我们可以用连续分布,而不是柱状图来表示连续变量的每个可能的值。连续分布看起来很像一条平滑的曲线,所以也叫密度曲线。密度曲线不仅代表特定样本中的一些值。它还代表所有可能的值及其出现概率,即这些值有多大的可能性会出现。

看柱状图时,我们根据柱子的高度来了解那个柱子里出现的数据点数量,即那个柱子里数据点的出现频率。但是,当我们看连续分布时,我们不能用那种方法来阐释概率曲线的高度。
试想包含身材的每个可能值的数据。探究某人的身高恰好是 61 英寸的几率是没有意义的。在有无数个值的情况下,探究 61 英寸跟探究某人是 61.002 英寸或 60.9997 英寸的几率一样主观武断。
我们要看的是在某个区间内的概率,等于曲线下方那个区间内的面积。
曲线下方的总面积是 1 或 100%,因为有 100% 的概率所有可能的值处于曲线内的某个地方。
总结一下,思考密度曲线时,需要记住以下几个概念。
- 曲线下方的总面积是 100%,或 1。
- 它们属于连续分布,代表同时所有可能的数据点。
- y 轴代表概率密度,表示获得接近 x 轴上相应点的值的几率。
正态分布
现在我们把注意力放在一条特殊的密度曲线上,它是正态分布或正态曲线。它的形状是一个对称的“钟”。
学习用柱状图绘制的连续变量的分布时,您学会了描述对称分布。如果您把对称分布的柱状图对折,两边将完美吻合。在对称分布中,平均数和中位数相等。
跟对称分布一样,在正态分布中,形状也是对称的,而且平均数也等于中位数。
以下是正态分布的主要特征。
- 围绕平均数对称分布。
- 平均数和中位数相等。
- 正态曲线下方的面积等于 1.0(即 100%)。
- 中心密集,尾部稀疏。
- 由平均数和标准偏差这两个参数来定义。

请看上面的曲线所示的正态分布。在正态分布中,68% 的数据在平均数 +1 到 -1 标准偏差范围内,95% 的数据在平均数 -2 到 +2 标准偏差范围内。曲线两侧的短“尾”表明非常少的值 (5%) 将落在平均数 -2 到 +2 标准偏差范围以外。
标准偏差更小的正态分布呈现的曲线比标准偏差更大的正态分布更窄、更高。
在这张图中,两个正态分布的平均数都是 50。较高曲线的标准偏差为 5,较矮曲线的标准偏差为 10。

正态分布的用途
信息设计师 Alberto Cairo 教授在他的著作《真实的艺术》中说道“自然界中没有任何现象遵循完美的正态分布,但是许多足够接近它,从而使它成为统计学的主要工具之一。” Cairo 还说道,“如果您知道您正在研究的现象属于正态分布,那么即使它不完美,您也能够以合理的准确度估计任何情况或分数的概率。” 换句话说,正态曲线的属性可以用来以合理的准确度估计某种情况或分数的概率。
人口估计往往源自于某个样本,因为我们不太可能测量整个人口。如果样本代表人口,则正态曲线是有用的估计工具。
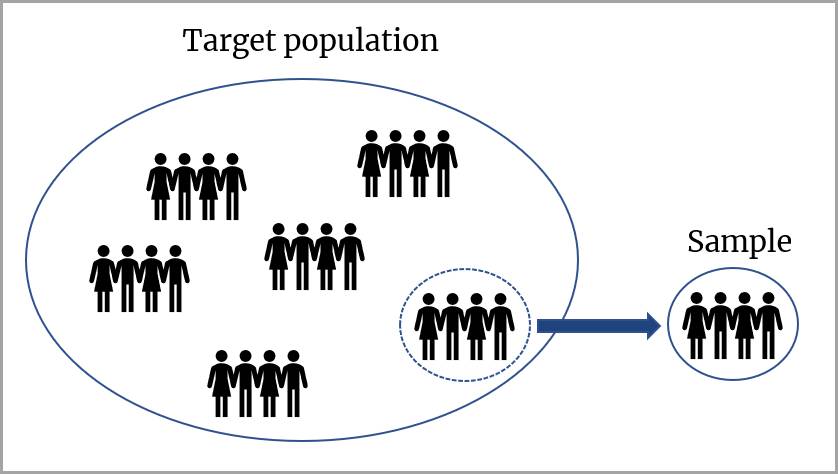
置信区间
使用正态曲线对样本数据做出概率估计时,您可以用置信区间来得出误差幅度。
置信区间是推断的一个例子。推断是指根据数据样本得出关于人口的结论的过程。

置信区间包含指定时间比例的人口平均数。比如,如果您想把置信区间设为 95%,那意味着您的数据中 95% 区间将包含真实平均数。
95% 的置信区间是通过正态分布推导出来的,其中 95% 的数据在平均数 -2 到 +2 标准偏差范围内。
我们来思考一个例子,改编自 David M. Lane 的网络公开著作《统计学入门》中关于置信区间的篇章。
假设您对美国 10 岁儿童的平均体重感兴趣。显然,您不可能去称每个 10 岁儿童的体重,而是称 16 名儿童组成的样本,发现平均体重是 90 磅。样本平均数 90 是对人口平均数的点估计值,但是它不能清楚地向您展示该样本的平均数偏离人口平均数有多远。换句话说,您确信整个美国 10 岁儿童人口的平均体重在 90 磅上下 5 磅范围内吗?您根本无从得知。
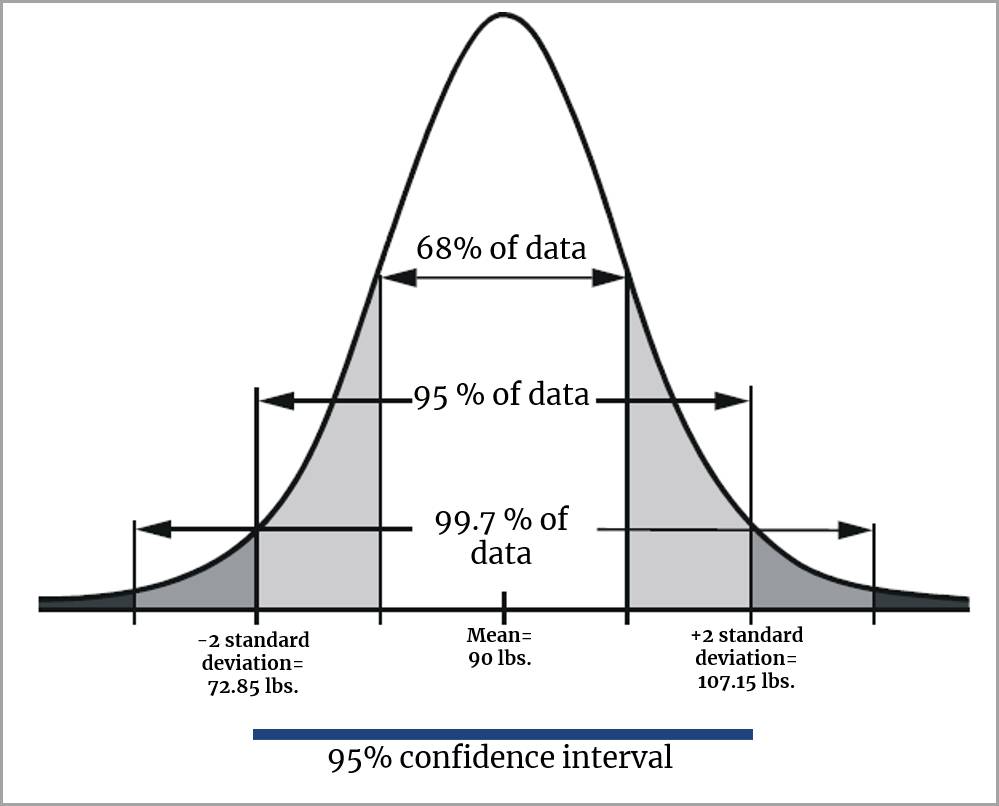
不过,您可以通过计算(这里不讨论)得出 95% 的置信区间。95% 的置信区间将包含介于 72.85 到 107.15 磅之间的平均体重。
换句话说,有充分的理由相信整个美国 10 岁儿童人口的平均体重将介于 72.85 到 107.15 磅之间,因为采用重复样本,并且对每个样本按 95% 的置信区间进行计算后,在 95% 的时间里区间将包含真实平均数。
不过,这也表示在 5% 的时间里,区间将不包含真实平均数。
现实世界中看到不确定性的例子
本单元前面提到过的 Alberto Cairo 还写了一些博客文章,描述了一些现实世界的例子,如何在论证飓风路径的可视化视图中表示不确定性(和误解)。您可以在 Alberto Cairo 的专业网站上浏览一篇关于曲解 2019 年五级台风“飓风多里安”的预测地图的博文以及其他一些相关话题。
现在您已经熟悉了连续分布,包括正态曲线的特殊形状。下一个单元,我们将学习使用数据样本时假设检验的概念。
资源