跟随提示过程
学习目标
完成本单元后,您将能够:
- 说明信任层如何安全地处理数据。
- 描述动态基础训练如何改善提示上下文。
- 描述信任层的护栏如何保护数据。
提示过程
您刚刚了解了一些关于信任层的内容,现在让我们看看它如何在 Salesforce 的生成式 AI 中发挥作用。在这个单元中,您将了解一个提示如何经过 Einstein 信任层到达 LLM。

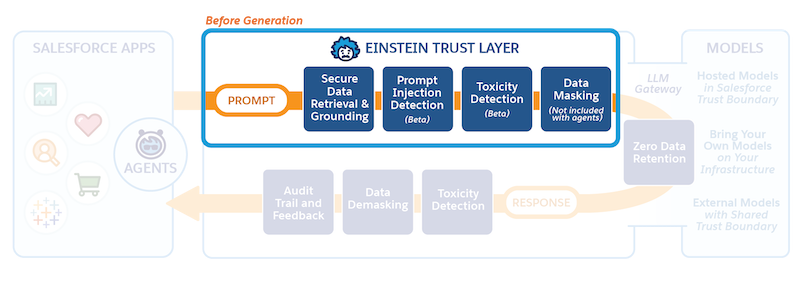
提示生成器、提示模板 Connect API 以及提示模板可调用操作中都有提示防御。
提示的强大功能
在提示基础知识 Trailhead 模块中,您了解到提示是生成式 AI 应用程序的动力源泉。您还将了解到明确的指示、上下文信息和约束条件有助于创建很棒的提示,从而使 LLM 给出出色的回复。为了为我们的客户提供便利以及保持一致性,我们预先构建了各种业务用例的提示模板,例如销售电子邮件或客户服务回复。当 Salesforce 应用程序向信任层发出请求时,信任层将调用相应的提示模板。
让我们通过一个客户服务案例来说明提示过程。您将看到提示模板,如何用客户数据和相关资源填充模板,以及 Einstein 信任层在将数据传输到外部 LLM 以生成与提示相关的回复之前如何保护数据。
会见 Jessica
Jessica 是一家消费信用卡公司的客服人员。该公司刚刚引入了 Service Replies(服务回复),这是一项由 Einstein 提供支持的功能,可以在客服人员与其客户聊天时生成建议的回复。Jessica 同意成为第一批尝试使用该功能的客服人员之一。在为客户提供服务时,她极具个人风格,因此她有点担心 AI 生成的回复可能与她平时表现出的风格不符。但她渴望在履历中增加一些生成式 AI 方面的经验,也很好奇服务回复是否可以帮助她为更多的客户提供服务。
Jessica 开始与她一天中的第一个客户聊天,这位客户希望升级他的信用卡。服务回复会在服务控制台中直接显示建议的回复。每当客户发送新消息时,系统会刷新回复,以使其在对话的上下文中具有意义。它们还会根据 Salesforce 中存储的客户数据针对客户实现个性化。建议的每个回复都是基于一个提示模板构建的。提示模板包含将用业务数据进行填充的指示和占位符,在本例中需要的是与 Jessica 的客户和支持案例相关的数据,以及与 Jessica 所在组织相关的数据和流程。提示模板位于 Salesforce Trust 层之后,作为服务控制台中的终端用户,Jessica 无法看到这些提示模板。
让我们仔细看看这些数据是如何经由信任层提供相关且高质量的回复,同时确保客户数据安全的。

您是 {!organization.name} 的一名客服人员。您的客户是 {!account.name} 的 {!contact.name},地址位于 {!contact.address},已成为您的客户 {!customer.history} 了。
在下面与客户的对话中生成客户服务人员的回复。询问有关客户问题的详细信息,但不得提出任何具体建议或解决方案。如果您还不确定,就说您会调查一下。
对话:{!conv_context}
以下是与您回复客户相关的 Knowledge 文章。
相关文章:{!Retriever.knowledge_recommendations}
动态基础训练
若想生成相关且高质量的回复需要相关且高质量的输入数据。当 Jessica 的客户加入对话时,服务回复会将对话与一个提示模板相关联,并开始用页面上下文、合并字段和来自客户记录的相关 Knowledge 文章替换占位符字段。这个过程被称为动态基础训练(dynamic grounding)。通常情况下,提示越进行基础训练,回复的准确性和相关性就越高。动态基础训练使提示模板可以重复使用,以便在整个组织中进行扩展。
动态基础训练的过程始于安全数据检索,它从 Jessica 所在组织中识别与其客户相关的数据。最为重要的是,安全数据检索遵循她所在组织中当前设定的所有 Salesforce 权限,在对象、字段等方面限制了对特定数据的访问。这样可以确保 Jessica 只提取她有权访问的信息。所检索到的数据不包含任何私人信息或需要更高权限访问的内容。

您是 Cumulus Financial 的一名客服人员。您的客户是 Northern Trail Outfitters 的 Dennis Maxfield,地址位于 415 Mission St., San Francisco, CA, 94105,已经成为您的客户 5 年了。
在下面与客户的对话中生成客户服务人员的回复。询问有关客户问题的详细信息,但不得提出任何具体建议或解决方案。如果您还不确定,就说您会调查一下。
对话:“你好,我无法升级我的 Cumulus 信用卡。你能帮忙吗?这些卡是否有最低信用评分要求?”
以下是与您回复客户相关的 Knowledge 文章。
相关文章:{!Retriever.knowledge_recommendations}
语义搜索
在 Jessica 的案例中,客户数据足以实现对话个性化。但这还不足以帮助 Jessica 快速有效地解决客户遇到的问题。Jessica 需要来自其他数据源(如 Knowledge 文章和客户历史记录)的信息来回答问题和确定解决方案。语义搜索使用机器学习和搜索方法在其他数据源中查找可以自动包含在提示中的相关信息。这意味着 Jessica 无需手动搜索这些资源,从而节省时间和精力。
在这里,语义搜索找到了一个相关的 Knowledge 文章来帮助解决信用卡问题,并将相关的文章片段包含在提示模板中。现在,这个提示真的在成形!

您是 Cumulus Financial 的一名客服人员。您的客户是 Northern Trail Outfitters 的 Dennis Maxfield,地址位于 415 Mission St., San Francisco, CA 94105,已经成为您的客户 5 年了。
在下面与客户的对话中生成客户服务人员的回复。询问有关客户问题的详细信息,但不得提出任何具体建议或解决方案。如果您还不确定,就说您会调查一下。
对话:“你好,我无法升级我的 Cumulus 信用卡。你能帮忙吗?这些卡是否有最低信用评分要求?”
以下是与您回复客户相关的 Knowledge 文章。
相关文章:“记得审查信用卡的要求——确保客户提供了所有必要的信息,并且信用评分超过了新信用卡所需的最低要求”
数据屏蔽
尽管提示包含有关 Jessica 的客户及其所提问题的准确数据,但它还没有准备好传递给 LLM,因为它包含了客户和客户的姓名和地址等信息。信任层通过数据屏蔽为 Jessica 的客户数据添加另一层安全保护。数据屏蔽包括对每个值进行标记,使每个值都被一个基于其所代表内容的占位符替换。这意味着 LLM 可以维持 Jessica 与其客户之间对话的上下文,并且仍旧生成相关的回复。
Salesforce 融合了模式匹配和高级机器学习技术,能够智能地识别客户详细信息,如姓名和信用卡信息,然后将其屏蔽。数据屏蔽是在后台进行的,所以 Jessica 无需执行任何操作即可防止将客户数据暴露给 LLM。在下一个单元中,您将了解如何将这些数据添加回回复中。
尽管 Salesforce 对第三方 LLM 采取零数据留存政策,但部分公司、用例或监管政策可能会要求不得将敏感数据发送给 LLM。Jessica 联系了她的 Salesforce 管理员,确认已开启数据屏蔽功能,以确保她的客户敏感数据不会被发送到 LLM。
目前 LLM 的数据屏蔽对智能体禁用。对于嵌入的生成式 AI 功能,如 Einstein 服务回复、Einstein 工作摘要数据屏蔽是可用的,因此 Jessica 可以将此选项用于其用例。

您是 <COMPANY_1> 的一名客服人员。您的客户是 <COMPANY_2> 的 <NAME_1>,地址位于 <ADDRESS_1>,已成为您的客户 5 年了。
在下面与客户的对话中生成客户服务人员的回复。询问有关客户问题的详细信息,但不得提出任何具体建议或解决方案。如果您还不确定,就说您会调查一下。
对话:“你好,我无法升级我的 <CREDIT_CARD_1>。你能帮忙吗?这些卡是否有最低信用评分要求?”
以下是与您回复客户相关的 Knowledge 文章。
相关文章:“记得审查信用卡的要求——确保客户提供了所有必要的信息,并且信用评分超过了新信用卡所需的最低要求”
提示防御
提示生成器提供了其他护栏,以保护 Jessica 和她的客户。这些护栏是对 LLM 的进一步指示,指导其在特定情况下如何行事,降低输出意外或有害内容的可能性。例如,可以指示 LLM 对于没有相关信息的内容不进行处理或生成答案。
黑客,有时甚至是员工,渴望绕过限制,企图以违背模型设计初衷的方式执行任务或操纵模型的输出。在生成式 AI 中,其中一种攻击类型被称为提示注入。提示防御有助于抵御这些攻击,并降低数据泄露的可能性。
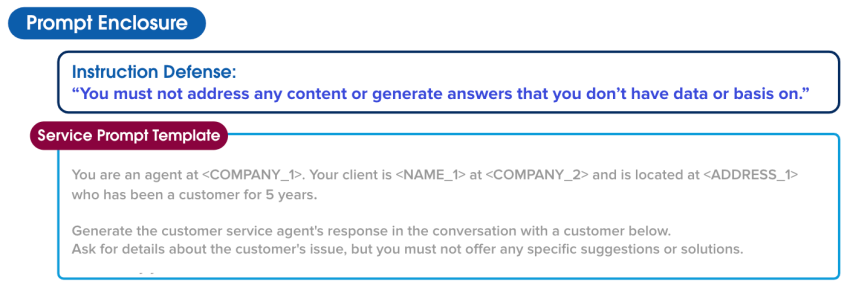
指令防御:“您绝不能在没有数据或依据的情况下处理任何内容或生成答案。”
接下来,让我们看一下当这个提示穿过安全网关进入 LLM 时会发生什么。
资源