研究聚合
学习目标
完成本单元后,您将能够:
- 定义聚合。
- 应用不同类型的聚合。
什么是聚合?
聚合是指一个包含定量数据的集合,可以显示大数据趋势。比如,将关于某个露营地的所有网络搜索汇总或者求出某个城市所有工薪族的平均收入。
在很多分析工具中,定量变量默认是聚合的,但也可以进行分解(按类别细分),以显示数据源每一行中每个值的数据点。

下面是一些常见的聚合。
聚合 |
描述 |
例如:3, 3, 6 |
|---|---|---|
总和 |
这些数值的算术总和 |
3 + 3 + 6 = 12 总和 = 12 |
平均值 |
数值的算术平均数(即总和除以数值个数) |
3 + 3 + 6 = 12 12/3 = 4 平均值 = 4 |
中值 |
从最小到最大(或从最大到最小)排序的数值列表中的中间值 |
3, 3, 6 中值 = 3 |
最小值 |
最小的值 |
3, 3, 6 最小值 = 3 |
最大值 |
最大的值 |
3, 3, 6
最大值 = 6 |
计数 |
数值的数量(在数据表中为行数或记录数) |
有三个值
计数 = 3 |
|
不同计数 (或唯一计数) |
不同值的数量,每个唯一值仅计一次(在数据表中,唯一记录行数) |
有两个唯一值:3 和 6
不同计数(或唯一计数)= 2 |
聚合的例子
让我们来看几个聚合的示例以及它们对数据分析的影响。我们将使用与在线词汇测试相关的调查数据。每个参与者都参加了在线词汇测验,然后回答了一些关于自己的人口统计问题。
查看包含聚合定量变量的可视化
查看以下可视化中的年龄定量变量。请注意,总和聚合将年龄变量中的所有值相加,总计 420,085 岁。
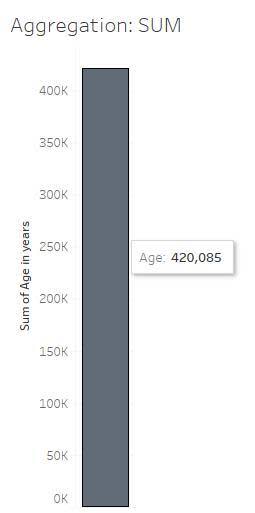
在上图中,单个条形将数据集中的所有数据(12,168 行)汇总为一个数字。
此年龄总和可以按最高教育程度进行细分,从而生成一个显示各教育层次总年龄的条形。(如果把每个值相加,就等于条形的总值。116,602 + 160,542 + 120,351 + 22,092 + 498 = 420,085。)

重要提示:这里的总和并不是一个合适的聚合,因为 116,602 岁的年龄没有意义。对于某些变量(例如本例中的年龄),使用总和聚合并不是有用或适当的数据表示。(在其他示例中,总和可能是适当的聚合。) 创建或查看可视化时,请务必注意分析和图表中使用的聚合。
查看基础数据
为了更好地了解哪些数值被求和,让我们来看看原始数据。当您检查行级数据时,您会看到每名参与者以及他们的教育程度和年龄的行。

查看 Choose not to say(选择不说)教育程度,年龄总和为 498。
13 + 13 + 13 + 13 + 15 + 16 + 16 + 16 + 17 + 17 + 18 + 20 + 20 + 23 + 37 + 45 + 53 + 65 + 68 = 498 岁
查看平均值聚合的影响
让我们看一下同一个条形图,但将聚合更改为平均值。现在,条形的高度不是将所有年龄相加并显示总值,而是其算术平均值。即将每个教育程度的所有年龄相加并除以值的数量。

查看 Choose not to say(选择不说)教育程度(以浅蓝色显示),平均年龄为 26.21 岁。
13 + 13 + 13 + 13 + 15 + 16 + 16 + 16 + 17 + 17 + 18 + 20 + 20 + 23 + 37 + 45 + 53 + 65 + 68 = 498
498 ÷ 19 = 26.21
现在的数字看起来比较像是一个人的真实年龄(大约 20 至 43 岁)。平均而言,年轻的受访者受教育程度较低。
查看中值聚合的影响
让我们看看在数据集中年龄何时会被聚合为中值(或中间值)。平均值可能会被极值拉长或偏斜。例如,如果一个 103 岁的人参加了测验,那么可能会让参与者的教育类别总体看起来年龄较大。为了避免极值导致偏斜的问题,中值聚合按顺序(从最大到最小或从最小到最大)对所有值进行排序,并返回中间值。

查看 Choose not to say(选择不说)教育程度(以浅蓝色显示),中值年龄为 17 岁。
13 , 13 , 13 , 13 , 15 , 16 , 16 , 16 , 17 , 17 , 18 , 20 , 20 , 23 , 37 , 45 , 53 , 65 , 68
从这张图表中,我们可以看到年龄中值要低一些。中值预期会更低,因为参加测验没有年龄上限,但必须年满 13 岁。这意味着不可能存在任何更年轻的极值来降低平均值。总体趋势仍然是受教育程度越高,参与者年龄越大。
查看最小值和最大值聚合的影响
最小值聚合返回所选数据中的最小值,最大值聚合返回最大值。
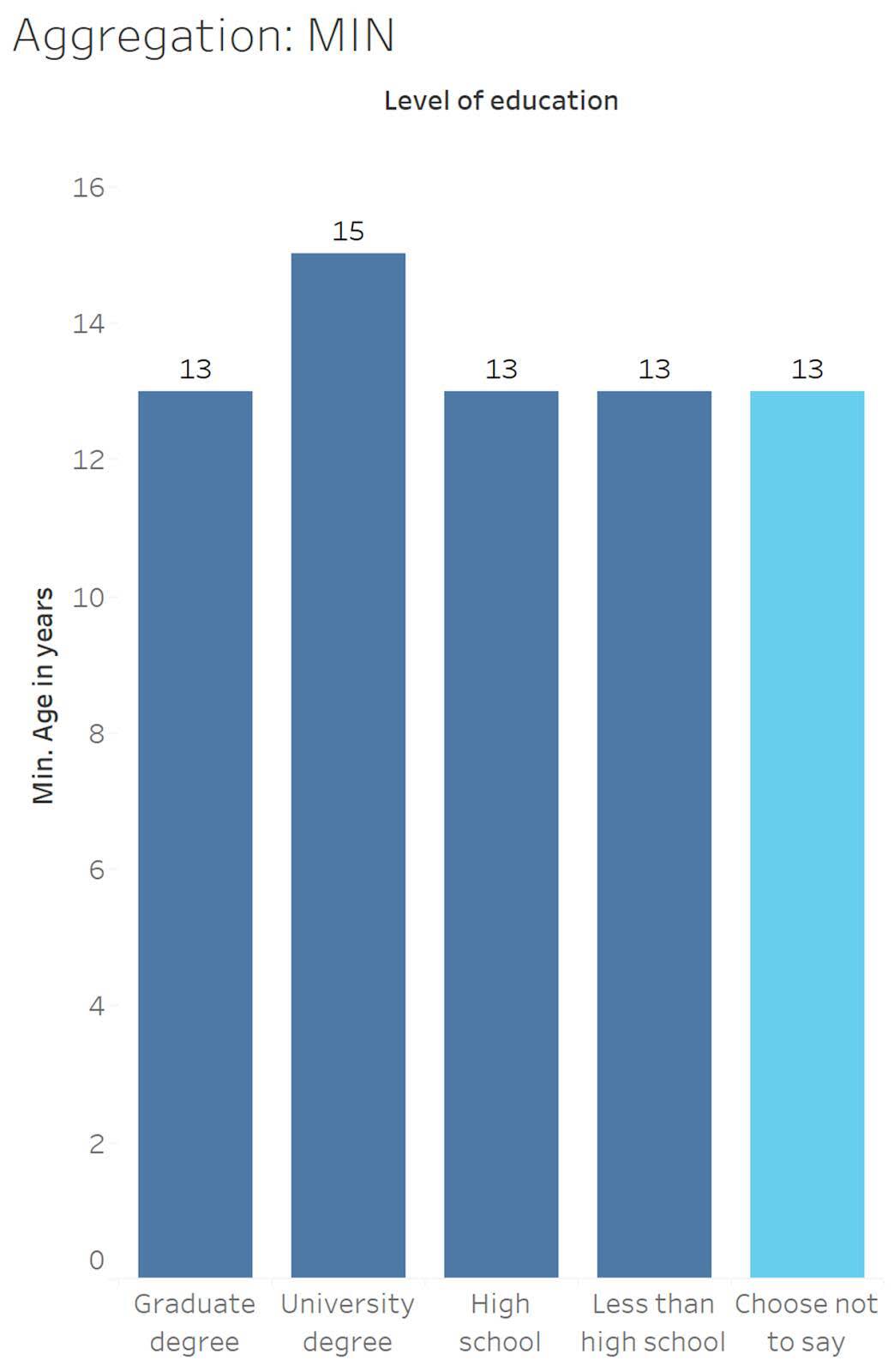
查看 Choose not to say(选择不说)教育程度(以浅蓝色显示),年龄最小值为 13 岁。
13 , 13 , 13 , 13 , 15 , 16 , 16 , 16 , 17, 17 , 18 , 20 , 20 , 23 , 37 , 45 , 53 , 65 , 68

查看 Choose not to say(选择不说)教育程度(以浅蓝色显示),年龄最大值为 68 岁。
13 , 13 , 13 , 13 , 15 , 16 , 16 , 16 , 17, 17 , 18 , 20 , 20 , 23 , 37 , 45 , 53 , 65 , 68
查看计数聚合的影响
现在,让我们来看看如果将年龄聚合为一个计数会怎么样。计数返回所选类别数据中的数值个数。这意味着我们不再关注年龄,而是关注参与者的数量。
查看 Choose not to say(选择不说)教育程度,计数为 19,不同计数是 12。不同计数为 12 是因为有 4 名参与者 13 岁,2 名参与者 16 岁,2 名参与者 20 岁。我们只计算 12、13 和 20 一次,因为不同计数聚合只计算唯一值。
|
计数为 19 13 13 13 13 15 16 16 16 17 17 18 20 20 23 37 45 53 65 68 |
不同计数则为 12 13 15 16 17 18 20 23 37 45 53 65 68 |
|---|
计数表明,拒绝提供教育程度的参与者非常少。
分解的例子
您看到的第一张图表是一个完全聚合的数据视图——只有一个值,即总和。然后,完整的数据集按教育程度分类,显示每个教育程度的年龄总和的细目。每个条形图不是看数据集中所有年龄的总和(或平均值,或最小值),而是聚合到每个教育类别的水平。数据仍然是聚合的,但更加详细。
|
|
|---|

下面我们再次来思考这些原始数据。

每一行代表一位参与者。如果我们想查看每位参与者的年龄,而不是一个聚合值,我们可以对数据进行完全分解,或绘制数据集中的每个点。
查看分解数据的影响

该图表使用抖动来分散数据点或标记。抖动是指沿着没有间隔的轴(此处为 x 轴)随机放置标记,以帮助揭示数据的密度。如果没有抖动,每个教育程度的标记都会堆叠在一条垂直线上。在抖动散点图中,标记的水平位置是随机的,并且不传达任何特定含义。
在此可视化中,我们可以看到年龄较小的参与者较多,而年龄较大的参与者较少。我们还可以看到,虽然 Less than high school(高中以下)类别中有一些年龄较大的参与者,但大多数都相当年轻—不到二十岁。High school(高中)类别中的大多数年龄都在 20 岁出头,这可能表明他们当前是大学生。此外,拥有研究生学位且年龄在 20 岁以下的参与者也非常少。根据我们对年龄和教育程度的了解,该分解数据非常符合现实预期。
尝试一下!
挑战:请看下表,其中有三行关于每周报纸阅读量的数据。
名称 |
每周报纸阅读量 |
|---|---|
Brooklyn |
2 |
Morgan |
3 |
Vaida |
7 |
如何将 Newspapers read per week(每周报纸阅读量)变量(2、3 和 7)的值聚合为总和、平均值、中值、最小值、最大值和计数?花点时间思考一下,然后用下面的互动式抽认卡检查一下您的答案。
请阅读每张卡上的聚合类型,思考那种聚合产生的值是什么,然后点击卡片查看正确答案。单击向右箭头可移至下一张卡,单击向左箭头可返回上一张卡。
您已经学习了聚合如何影响数据以及分解数据产生的影响。下一个单元中,您将通过学习粒度掌握这些概念。
资源