プロンプトジャーニーをたどる
学習の目的
この単元を完了すると、次のことができるようになります。
- Trust Layer でデータを安全に処理する方法を説明する。
- 動的グラウンディングによってプロンプトのコンテキストがどのように改善されるか説明する。
- Trust Layer のガードレールでデータを保護する方法を説明する。
プロンプトジャーニー
Trust Layer の概要を学習したところで、Salesforce の生成 AI 全体でどのような位置付けになっているのか見ていきましょう。この単元では、プロンプトが Einstein Trust Layer のプロセスをどのように進んで LLM に達するのかを学習します。


プロンプト防御は、プロンプトビルダー、プロンプトテンプレート接続 API、プロンプトテンプレート呼び出し可能アクションで使用できます。
プロンプトの機動力
「プロンプトの基本事項」Trailhead モジュールでは、プロンプトが生成 AI アプリケーションの機動力であることを学習します。また、明確な指示、コンテキスト情報、制約によって的確なプロンプトが作成され、その結果 LLM で的確な応答が生成されることも学びます。お客様が一貫性のあるプロンプトを簡単に作成できるように、多様なビジネスユースケースに対応するプロンプトテンプレートが事前構築されています。任意の Salesforce アプリケーションから Trust Layer に要求が実行されると、Trust Layer から関連するプロンプトテンプレートがコールされます。
ここで、プロンプトジャーニーをわかりやすく説明するために、カスタマーサービスケースを順を追って見ていきます。プロンプトテンプレートがどのようなもので、どのような方法でテンプレートに顧客データや関連リソースが入力され、Einstein Trust Layer でデータが保護され、データが外部 LLM に達し、プロンプトに対する応答が生成されるのかを確認します。
Jessica の場合
Jessica は消費者向けクレジットカード会社のカスタマーサービスエージェントです。この会社は先頃、顧客とチャット中のカスタマーエージェントに推奨の返信を生成する、Einstein 搭載のサービス返信を実装しました。Jessica は数人のエージェントと共にこの機能を最初に試してみる役目を引き受けました。顧客と接する際の心のこもった対応に定評がある Jessica は、AI が生成する返信は自分のスタイルに合わないのではないかとやや不安になっています。その一方で、キャリアアップの点でも生成 AI エクスペリエンスを構築できるようになることに前向きで、サービス返信によってより多くの顧客をサポートできるかどうかにも関心を抱いています。
Jessica はその日の 1 人目の顧客とチャットを開始します。この顧客は、クレジットカードのアップグレードでサポートを求めています。サービス返信により、サービスコンソールに直接返信の提案が表示され始めました。顧客が新しいメッセージを送信するたびに返信が更新されるため、会話のコンテキストに即した内容になっています。また、Salesforce に保存されている顧客データに基づいて、返信が顧客向けにパーソナライズされています。提案される返信はそれぞれプロンプトテンプレートから作成されます。プロンプトテンプレートは指示と、ビジネスデータが入力されるプレースホルダーで構成されます。このケースでは、Jessica の顧客とそのサポートケースに関連するデータと、Jessica の組織の関連するデータやフローが入力されています。プロンプトテンプレートは Salesforce Trust Layer のバックグラウンドに存在し、サービスコンソールのエンドユーザーである Jessica がプロンプトテンプレートを表示することはできません。
では、顧客データの安全性を確保しながら、高質で関連性の高い返信を配信するために、このデータが Trust Layer をどのように進行していくのか詳しく見ていきましょう。

あなたは {!organization.name} のエージェントです。あなたのクライアントは {!account.name} の {!contact.name} で、{!contact.address} に所在し、{!customer.history} にわたる顧客です。
顧客との以下の会話におけるカスタマーサービスエージェントの応答を生成してください。顧客の問題の詳細を尋ねますが、具体的な提案や解決策を提示してはなりません。定かでない場合は、調べてお返事しますと伝えます。
会話: {!conv_context}
以下に、顧客への応答に関連すると思われるナレッジ記事を示します。
関連記事: {!Retriever.knowledge_recommendations}
動的グラウンディング
高質で関連性の高い返信を生成するには、高質で関連性の高い入力データが必要です。Jessica の顧客が会話を入力すると、サービス返信がその会話をプロンプトテンプレートにリンクし、プレースホルダー項目をページコンテキスト、差し込み項目、顧客レコードの関連するナレッジ記事などに置き換え始めます。このプロセスを動的グラウンディングといいます。一般に、プロンプトが適切にグラウンディングされていれば、応答の正確性と関連性が向上します。動的グラウンディングにより、プロンプトテンプレートが再利用可能になり、組織全体に拡張できるようになります。
動的グラウンディングのプロセスの第一歩は、安全なデータ取得です。このステップで、組織にある Jessica の顧客に関連するデータが特定されます。安全なデータ取得で特に重要な点は、現在組織で設定されている、オブジェクトや項目などの特定のデータへのアクセスを制限する Salesforce 権限をすべて尊重することです。そうすれば、Jessica がアクセスを許可されている情報のみを取り込むことになります。取得したデータに個人情報や、権限の昇格を要する内容は含まれません。

あなたは Cumulus Financial のエージェントです。あなたのクライアントは Northern Trail Outfitters の Dennis Maxfield で、415 Mission St., San Francisco, CA 94105 に所在し、5 年にわたる顧客です。
顧客との以下の会話におけるカスタマーサービスエージェントの応答を生成してください。顧客の問題の詳細を尋ねますが、具体的な提案や解決策を提示してはなりません。定かでない場合は、調べてお返事しますと伝えます。
会話:「こんにちは。Cumulus のクレジットカードをアップグレードできません。サポートが必要です。こうしたカードの中に、信用スコアの最低値が定められているものはありますか?」
以下に、顧客への応答に関連すると思われるナレッジ記事を示します。
関連記事: {!Retriever.knowledge_recommendations}
セマンティック検索
Jessica のケースでは、顧客データで会話を十分にパーソナライズできます。けれども、Jessica が顧客の問題を迅速かつ効果的に解決するためには、顧客データだけでは十分ではありません。Jessica が質問に答え、解決策を特定するためには、ナレッジ記事や顧客履歴などほかのデータソースからの情報が必要です。セマンティック検索では、プロンプトに自動的に含めることができるほかのデータソースから、関連情報を見つける機械学習と検索方法を使用します。つまり、Jessica がこうしたソースを手作業で検索する必要がないため、時間と手間が省かれます。
ここでは、セマンティック検索でクレジットカードの問題の解決に役立ちそうなナレッジ記事が見つかったため、その記事の関連する部分がプロンプトテンプレートに追加されています。プロンプトが形になってきました!

あなたは Cumulus Financial のエージェントです。あなたのクライアントは Northern Trail Outfitters の Dennis Maxfield で、415 Mission St., San Francisco, CA 94105 に所在し、5 年にわたる顧客です。
顧客との以下の会話におけるカスタマーサービスエージェントの応答を生成してください。顧客の問題の詳細を尋ねますが、具体的な提案や解決策を提示してはなりません。定かでない場合は、調べてお返事しますと伝えます。
会話:「こんにちは。Cumulus のクレジットカードをアップグレードできません。サポートが必要です。こうしたカードの中に、信用スコアの最低値が定められているものはありますか?」
以下に、顧客への応答に関連すると思われるナレッジ記事を示します。
関連記事:「クレジットカードの要件を確認してください。クライアントが必要な情報をすべて提供し、新しいクレジットカードに必要な最小限の信用スコア以上であることを確認します。」
データマスキング
プロンプトに Jessica の顧客とその問題に関する正確なデータが示されていますが、クライアントや顧客の名前と住所などの情報が示されているため、まだ LLM に送信するわけにはいきません。Trust Layer はデータマスキングで Jessica の顧客データの保護を強化します。データマスキングでは各値がトークン化され、その値が何を表すかに基づいてプレースホルダーに置き換えられます。つまり、LLM が Jessica と顧客の会話のコンテキストを把握して、適切な応答を生成できるようにします。
Salesforce では、パターンマッチングと機械学習の高度な技法を組み合わせて、名前やクレジットカード情報といった顧客の詳細をインテリジェントに特定してマスクします。データマスキングはバックグラウンドで行われるため、顧客のデータが LLM に公開されないようにするために Jessica が何かをする必要はありません。こうしたデータが応答にどのように追加されるかは、次の単元で学習します。
Salesforce はサードパーティの LLM に対してデータ保持ゼロポリシーを採用していますが、会社やユースケース、あるいは規制ポリシーによっては、機密データを LLM に一切送信しないことが求められる場合があります。Jessica は、自分の顧客に関する機密なデータが LLM に送信されないよう、データマスキングが有効になっていることを Salesforce のシステム管理者に確認します。
LLM のデータマスキングは現在エージェントでは無効になっています。Einstein サービス返信や Einstein 作業概要などの埋め込み型生成 AI 機能ではデータマスキングを使用できるため、Jessica はこのオプションを自分のユースケースで使用できます。

あなたは <COMPANY_1> のエージェントです。あなたのクライアントは <COMPANY_2> の <NAME_1> で、<ADDRESS_1> に所在し、5 年にわたる顧客です。
顧客との以下の会話におけるカスタマーサービスエージェントの応答を生成してください。顧客の問題の詳細を尋ねますが、具体的な提案や解決策を提示してはなりません。定かでない場合は、調べてお返事しますと伝えます。
会話:「こんにちは。<CREDIT_CARD_1> のクレジットカードをアップグレードできません。サポートが必要です。こうしたカードの中に、信用スコアの最低値が定められているものはありますか? 」
以下に、顧客への応答に関連すると思われるナレッジ記事を示します。
関連記事:「クレジットカードの要件を確認してください。クライアントが必要な情報をすべて提供し、新しいクレジットカードに必要な最小限の信用スコア以上であることを確認します。」
プロンプト防御
プロンプトビルダーは、Jessica とその顧客を守るために追加のガードレールを設置します。こうしたガードレールは、特定の状況でどのように動作すべきか LLM にさらなる指示を与え、LLM が想定外の内容や有害な内容を出力する可能性を軽減します。たとえば、LLM が情報を持ち合わせていない場合はコンテンツに対処したり、回答を生成したりしないよう指示することがあります。
ハッカーや、時として従業員も、制限をうまく迂回して、モデルの意図した処理方法ではないやり方でタスクを実行したり、モデルの出力を操作したりしようとします。生成 AI では、こうした攻撃の一種をプロンプトインジェクションと呼んでいます。プロンプト防御でこの攻撃から保護し、データが侵害される可能性を減少させることができます。
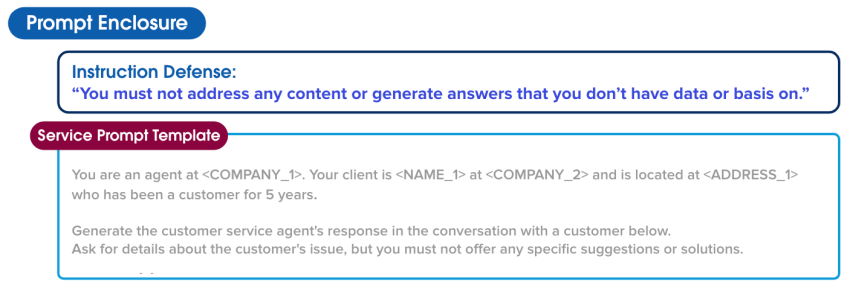
防御指示:「データや根拠のない内容に言及したり、そうした回答を生成したりしてはなりません。」
次は、このプロンプトがセキュアゲートウェイを通過して LLM に達するとどうなるかを見ていきます。
リソース