Estimation de la probabilité
Objectifs de formation
Une fois cette unité terminée, vous pourrez :
- Décrire ce que sont les distributions continues
- Décrire les caractéristiques d’une distribution normale
Introduction
Le module Distributions des données explique que vous pouvez utiliser un histogramme pour représenter la distribution de valeurs continues. Intéressons-nous maintenant au concept des distributions continues.
Nous n’aborderons pas les formules utilisées pour effectuer les calculs mentionnés dans cette unité, mais une connaissance générale de ces concepts peut vous être utile pour explorer des phénomènes, comprendre des situations et communiquer grâce aux données.
Courbes de densité
Le module Distributions des données explique comment les histogrammes permettent de représenter les distributions d’échantillons finis de variables continues. La hauteur de chaque barre de l’histogramme est proportionnelle à la fréquence des valeurs dans cette classe. En d’autres termes, plus la barre est élevée, plus le nombre de points de données de l’échantillon qui se trouvent dans cette classe est élevé.
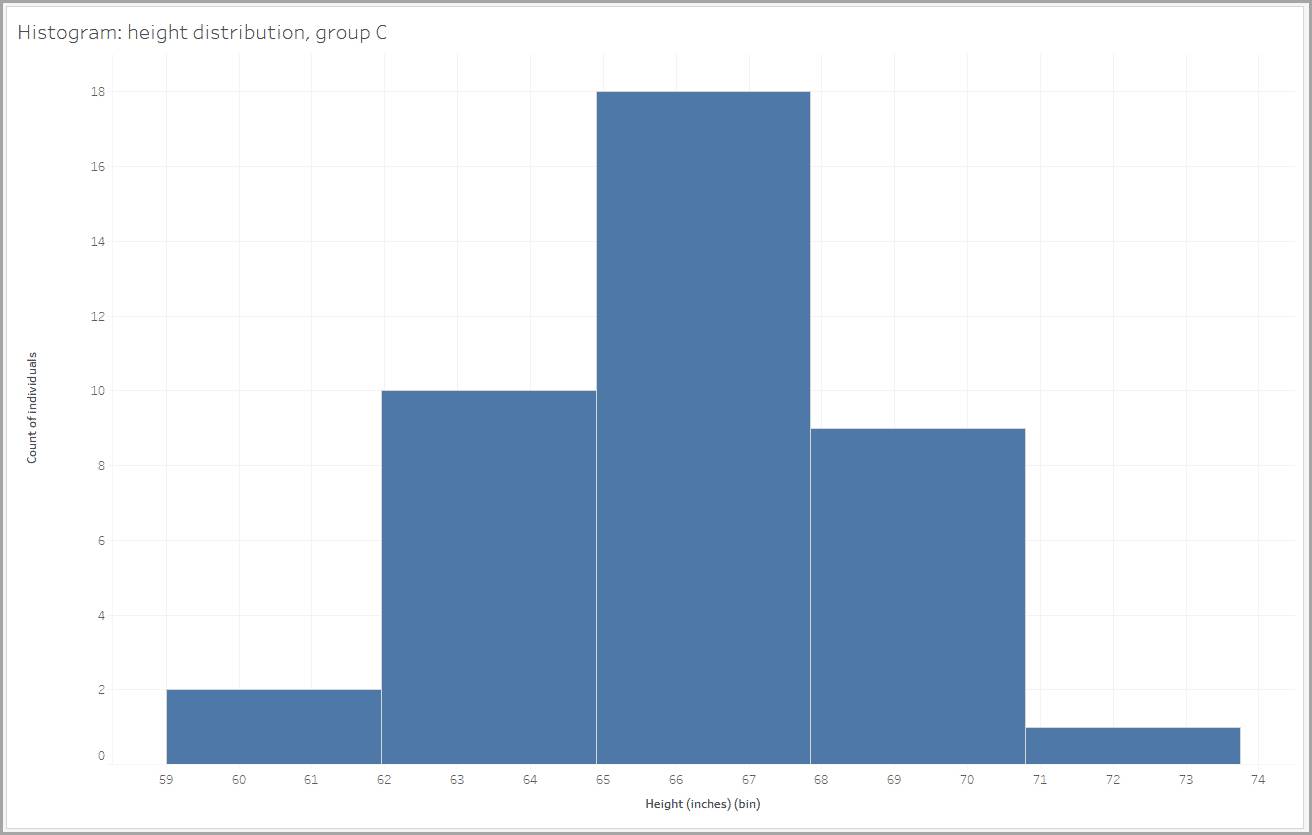
Par exemple, l’histogramme ci-dessus montre la distribution des tailles (en pouces) de 40 personnes. Cet échantillon de données contient de toute évidence un nombre fini de points de données. Néanmoins, si vous tenez compte de toutes les valeurs possibles pour la variable continue de taille, vous pouvez constater qu’elle peut beaucoup varier. Toute une vie ne suffirait pas pour créer un histogramme avec des classes pour toutes les valeurs de taille possibles. Cette affirmation est valable pour toutes les variables continues.
Au lieu d’utiliser un histogramme pour représenter chaque valeur possible pour une variable continue, nous pouvons utiliser une distribution continue. Une distribution continue a l’allure d’une courbe progressive, également appelée courbe de densité. Une courbe de densité représente plus que les simples valeurs d’un échantillon : elle représente toutes les valeurs possibles, ainsi que leur probabilité d’occurrence.

Lorsque nous observons un histogramme, nous nous servons de la hauteur des barres pour déterminer le nombre de points de données dans chaque classe, ou leur fréquence d’occurrence. Toutefois, lorsque nous regardons des distributions continues, nous ne pouvons pas interpréter la hauteur d’une courbe de probabilité de la même manière.
Imaginons que nous disposions de données contenant toutes les valeurs possibles pour la taille. Il ne serait pas pertinent de chercher la probabilité qu’une personne fasse une taille de 61 pouces. Avec un nombre infini de valeurs, poser cette question serait aussi arbitraire que de chercher la probabilité qu’une personne mesure 61,002 pouces ou 60,9997 pouces.
Intéressons-nous plutôt à la probabilité dans un intervalle, qui est égale à l’aire sous la courbe au sein de cet intervalle.
L’aire totale sous la courbe est de 1, ou 100 %, car la probabilité que toutes les valeurs possibles se situent quelque part sous cette courbe est de 100 %.

Pour résumer, voici quelques concepts à garder à l’esprit au sujet des courbes de densité.
- L’aire totale sous la courbe est égale à 100 % ou 1.
- Il s’agit de distributions continues qui représentent tous les points de données possibles en même temps.
- L’axe des ordonnées représente la densité de probabilité, qui montre les chances d’obtenir des valeurs proches des points correspondants sur l’axe des abscisses.
Distribution normale
Nous allons maintenant nous intéresser à une courbe de densité spécifique, la distribution normale ou loi normale. Elle se caractérise par une forme de cloche symétrique.
Lorsque vous avez observé les distributions de variables continues tracées sous forme d’histogrammes, vous avez appris à décrire une distribution symétrique. Si vous pliez en deux verticalement un histogramme de distribution symétrique, les deux moitiés se chevauchent parfaitement. Dans les distributions symétriques, la moyenne et la médiane ont une valeur identique.
De la même manière, dans une distribution normale, la forme de la courbe est symétrique, et la moyenne est égale à la médiane.
Voici les principales caractéristiques d’une distribution normale.
- Elle présente une symétrie autour de la moyenne.
- La moyenne et la médiane sont égales.
- L’aire sous la courbe est égale à 1 (ou 100 %).
- La densité est plus importante au centre et plus faible aux extrémités.
- Elle se définit à l’aide de deux paramètres, à savoir la moyenne et l’écart type.

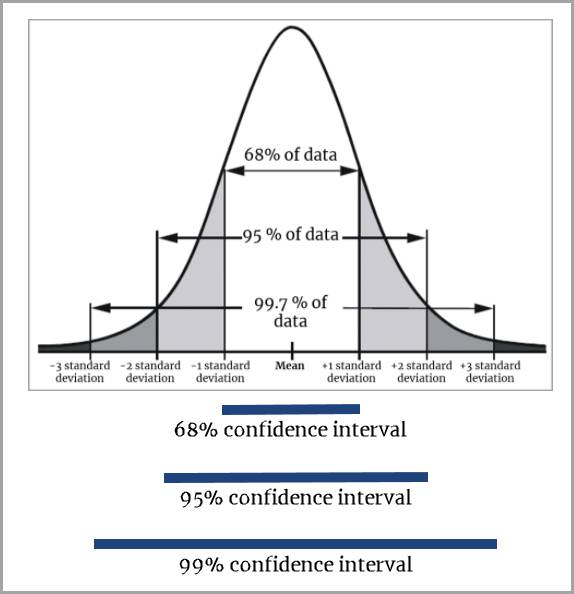
Observez la distribution normale sur la courbe ci-dessus. Dans une distribution normale, 68 % des données se trouvent dans l’intervalle compris dans l’écart type allant de -1 à +1 autour de la moyenne, et 95 % des données sont dans l’intervalle compris dans l’écart type allant de -2 à +2 autour de la moyenne. Les deux extrémités de la courbe indiquent que peu de valeurs (5 %) sortent de l’intervalle compris dans l’écart type allant de -2 à +2 autour de la moyenne.
Les distributions normales avec un écart type plus faible auront des courbes plus resserrées et plus hautes que celles avec un écart type plus élevé.
Sur cette image, les deux distributions ont une moyenne de 50. La plus grande présente un écart type de 5 et la plus petite un écart type de 10.

Utilité des distributions normales
Dans son ouvrage The Truthful Art, Alberto Cairo, professeur et expert en présentation d’informations explique ceci : « Bien qu’aucun phénomène naturel ne suive une distribution normale parfaite, bon nombre d’entre eux s’en approchent suffisamment pour en faire l’un des principaux outils utilisés en statistiques ». Il ajoute que « si vous savez que le phénomène que vous étudiez suit une distribution normale, même imparfaite, vous pouvez estimer la probabilité d’occurrence de tout élément ou score de manière raisonnablement précise ». En d’autres termes, les propriétés d’une courbe de loi normale peuvent être utilisées pour estimer la probabilité d’occurrence d’un élément ou score avec une précision raisonnable.
Les estimations relatives à une population sont souvent effectuées à partir d’un échantillon, car il est rarement possible d’effectuer des mesures portant sur la population entière. Si l’échantillon est représentatif de la population totale, la courbe de loi normale est un outil d’estimation utile.

Intervalles de confiance
Lorsque vous utilisez une courbe de loi normale pour estimer des probabilités à partir d’un échantillon de données, vous pouvez utiliser des intervalles de confiance pour déterminer une marge d’erreur.
Les intervalles de confiance sont un exemple d’inférence. L’inférence désigne le fait de tirer des conclusions au sujet d’une population à partir d’un échantillon de données.
Un intervalle de confiance contient une moyenne de population pour une proportion spécifiée du temps. Par exemple, si vous souhaitez obtenir un intervalle de confiance de 95 %, cela signifie que 95 % des intervalles dans vos données incluront la moyenne réelle.
L’intervalle de confiance de 95 % est défini en utilisant une distribution normale dans laquelle 95 % des données se trouvent dans un écart type allant de -2 à +2 autour de la moyenne.
Intéressons-nous à un exemple adapté du chapitre écrit par David M. Lane au sujet des intervalles de confiance dans l’ouvrage en ligne Introduction to Statistics, appartenant au domaine public.
Imaginons que vous souhaitiez connaître le poids moyen en livres des enfants de 10 ans aux États-Unis. Vous ne pouvez évidemment pas peser tous les enfants de 10 ans. Vous pouvez cependant peser un échantillon de 16 enfants, et déterminer que leur poids moyen est de 90 livres. Cette moyenne d’échantillon égale à 90 est une estimation de la moyenne de la population, mais n’indique pas si la moyenne de l’échantillon est proche de celle de la population. En d’autres termes, avez-vous l’assurance que le poids moyen de l’ensemble de la population des enfants de 10 ans aux États-Unis se situe dans un écart allant de -5 à +5 livres autour de 90 ? Il est impossible d’avoir cette certitude.
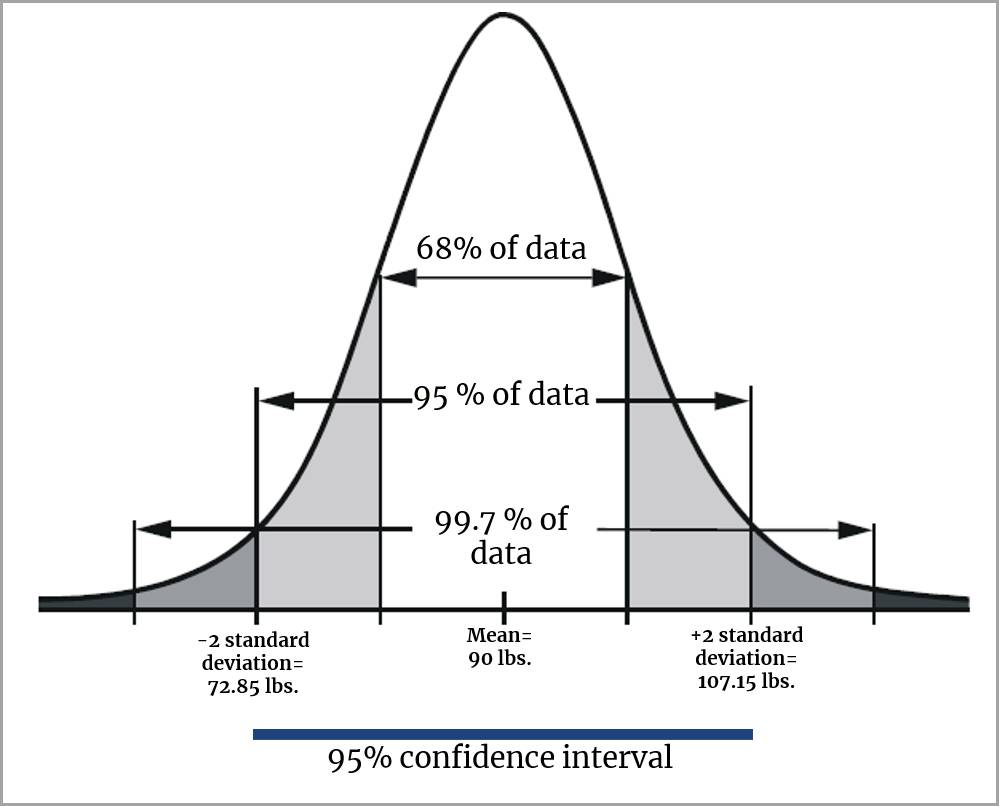
Néanmoins, vous pouvez utiliser un calcul (qui n’est pas expliqué dans cette unité) pour obtenir un intervalle de confiance de 95 %. Un intervalle de confiance de 95 % inclurait des poids moyens entre 72,85 et 107,15 livres.
En d’autres termes, il y a de bonnes raisons de considérer que le poids moyen de l’ensemble de la population des enfants de 10 ans aux États-Unis se trouve entre 72,85 et 107,15 livres, car, après avoir réalisé des mesures au sein de plusieurs échantillons et calculé l’intervalle de confiance de 95 % pour chacun d’entre eux, la véritable moyenne se trouve dans les intervalles 95 fois sur 100.
Toutefois, cela indique également qu’ils ne contiennent pas la véritable moyenne 5 % du temps.
Exemples concrets de représentation de l’incertitude
Alberto Cairo, dont nous avons parlé précédemment dans cette unité, a écrit plusieurs articles décrivant des exemples concrets sur la représentation de l’incertitude (et ses mauvaises interprétations) dans les visualisations de la trajectoire des ouragans. Sur le site professionnel d’Alberto Cairo, vous pouvez lire un article de blog qui traite des problèmes d’interprétation des cartes de prévision concernant l’ouragan de catégorie 5 Dorian qui a fait rage en 2019.
Vous connaissez maintenant bien les distributions continues, et savez notamment quelle forme spécifique ont les courbes de loi normale. Dans l’unité suivante, nous aborderons le concept de test d’hypothèses lors de l’utilisation d’échantillons de données.
Ressources
- Site Web : Online Statistics Education par David M. Lane : An Interactive Multimedia Course of Study, 2020
- Site Web : Site professionnel d’Alberto Cairo