Découverte du concept d’agrégation
Objectifs de formation
Une fois cette unité terminée, vous pourrez :
- Définir ce qu’est l’agrégation
- Appliquer différents types d’agrégation
Présentation du concept d’agrégation
Une agrégation consiste à rassembler des données quantitatives de sorte à potentiellement mettre en évidence des tendances majeures. Par exemple, une agrégation peut consister à totaliser toutes les recherches sur le Web concernant un camping donné, ou à calculer le revenu moyen de tous les salariés d’une commune.
Dans de nombreux outils d’analyse, les variables quantitatives sont agrégées par défaut, mais peuvent être désagrégées (réparties par catégorie) pour afficher des points de données correspondant à chacune des valeurs de chacune des lignes de la source de données.

Voici quelques agrégations courantes.
Agrégation |
Description |
Exemple : 3, 3, 6 |
|---|---|---|
Somme |
Total arithmétique des valeurs |
3 + 3 + 6 = 12 Somme = 12 |
Moyenne |
Moyenne arithmétique des valeurs (c’est-à-dire la somme divisée par le nombre de valeurs) |
3 + 3 + 6 = 12 12/3 = 4 Moyenne = 4 |
Médiane |
Valeur médiane dans une liste de valeurs triées de la plus petite à la plus grande (ou de la plus grande à la plus petite) |
3, 3, 6 Médiane = 3 |
Minimum |
La plus petite valeur |
3, 3, 6 Minimum = 3 |
Maximum |
La plus grande valeur |
3, 3, 6
Maximum = 6 |
Total |
Nombre de valeurs (dans une table de données, le nombre de lignes ou d’enregistrements) |
Il y a trois valeurs
Nombre = 3 |
|
Décompte approximatif (ou Décompte unique) |
Nombre de valeurs distinctes, où chaque valeur unique n’est comptée qu’une seule fois (dans une table de données, le nombre de lignes d’enregistrements uniques) |
Il existe deux valeurs uniques : 3 et 6.
Décompte approximatif (ou décompte unique) = 2 |
Exemples d’agrégation
Examinons des exemples d’agrégations et l’impact qu’elles ont sur l’analyse des données. Nous utiliserons les données d’enquête associées à un test de vocabulaire en ligne. Chaque participant a répondu à un questionnaire de vocabulaire en ligne, puis a répondu à quelques questions démographiques sur lui-même.
Examen d’une visualisation avec une variable quantitative agrégée
Observez la variable quantitative Age (Âge) dans la visualisation suivante. Vous remarquerez que l’agrégation de somme additionne toutes les valeurs de la variable Age (Âge), pour un total de 420 085 ans.

Dans le graphique ci-dessus, une seule barre résume toutes les données (12 168 lignes) de l’ensemble de données sous la forme d’un seul nombre.
Cette somme des âges peut être décomposée par niveau d’éducation le plus élevé, ce qui donne lieu à une barre indiquant l’âge total pour chaque niveau d’éducation. (Si vous additionnez chacune de ces valeurs, cela équivaut au total de la barre unique : 116 602 + 160 542 + 120 351 + 22 092 + 498 = 420 085.)
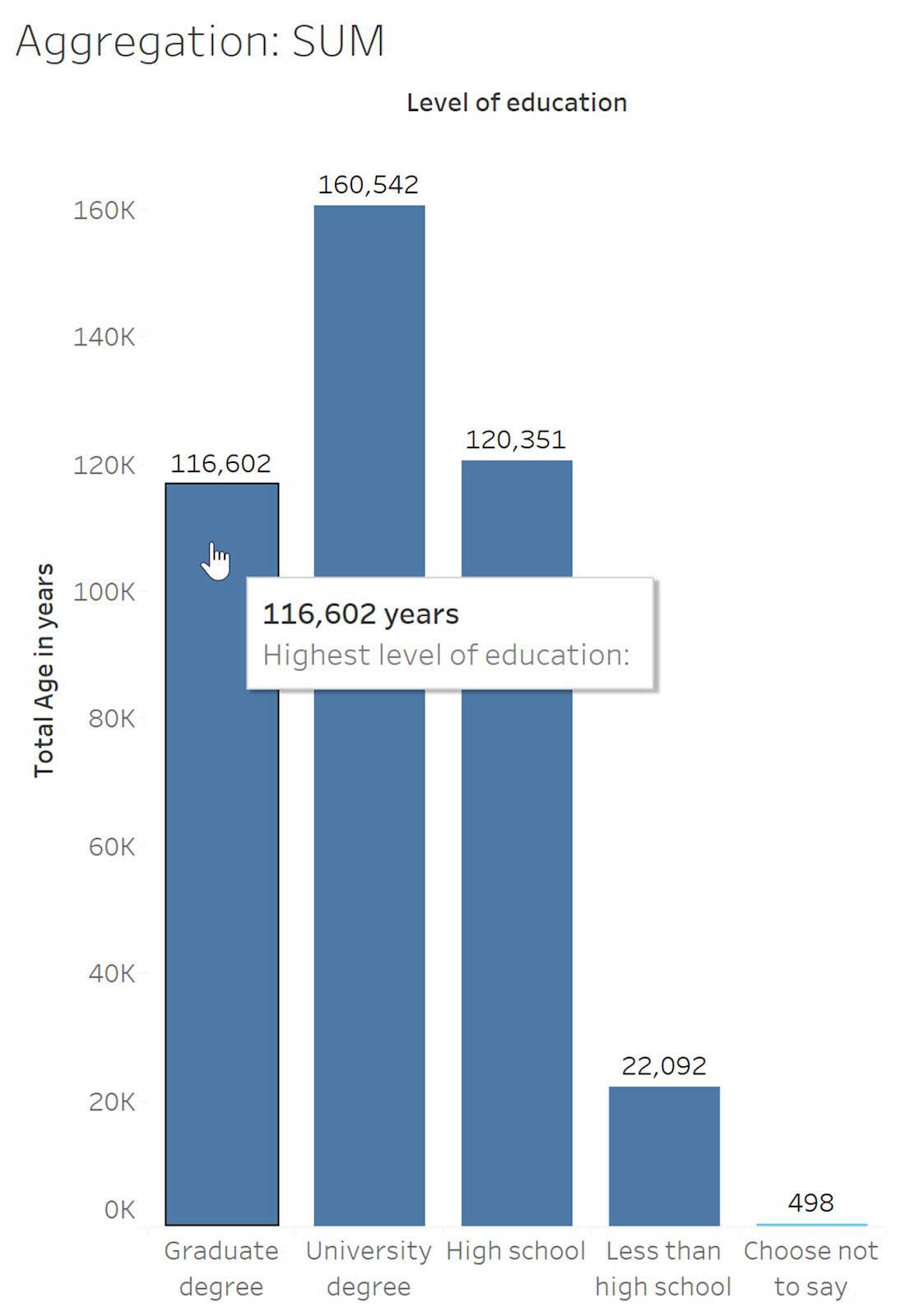
Important : La somme n’est pas une agrégation appropriée ici puisqu’un âge de 116 602 ans n’a pas de sens. Pour certaines variables, comme l’âge dans cet exemple, l’utilisation de l’agrégation de somme n’est pas une représentation utile ou appropriée des données. (Dans d’autres exemples, la somme peut être une agrégation appropriée.) Lors de la création ou de l’affichage de visualisations, il est important de prêter attention aux agrégations utilisées dans les analyses et les graphiques.
Affichage de données sous-jacentes
Pour mieux comprendre quelles valeurs sont additionnées, observons les données brutes. Lorsque vous examinez les données au niveau des lignes, vous voyez une ligne pour chaque participant, ainsi que son niveau d’éducation et son âge.

En regardant le niveau d’éducation Choose not to say (Choisir de ne pas préciser), la somme de l’âge est de 498.
13 + 13 + 13 + 13 + 15 + 16 + 16 + 16 + 17 + 17 + 18 + 20 + 20 + 23 + 37 + 45 + 53 + 65 + 68 = 498 ans
Affichage des effets de l’agrégation de moyenne
Regardons le même graphique à barres que précédemment, mais remplaçons l’agrégation par la moyenne. Au lieu d’additionner tous les âges et d’afficher cette valeur, la hauteur des barres correspond désormais à sa moyenne arithmétique. Pour chaque niveau d’éducation, tous les âges sont additionnés et divisés par le nombre de valeurs.

En regardant le niveau d’éducation Choose not to say (Choisir de ne pas préciser) (affiché en bleu clair), la moyenne est de 26,21 ans.
13 + 13 + 13 + 13 + 15 + 16 + 16 + 16 + 17 + 17 + 18 + 20 + 20 + 23 + 37 + 45 + 53 + 65 + 68 = 498
498 ÷ 19 = 26,21
Désormais, les chiffres correspondent à des âges qui semblent réalistes pour une personne (environ entre 20 à 43 ans). Et en moyenne, les personnes interrogées plus jeunes sont moins instruites.
Affichage des effets de l’agrégation de médiane
Explorons quand la valeur Age (Âge) est agrégée en tant que valeur médiane dans un ensemble de données. Les moyennes peuvent être étirées ou biaisées par des valeurs extrêmes. Par exemple, si une personne âgée de 103 ans répondait au questionnaire, son âge pourrait donner l’impression que sa catégorie d’éducation comptait globalement des participants plus âgés. Pour éviter le problème de biais dû aux valeurs extrêmes, l’agrégation MEDIAN (MÉDIANE) classe toutes les valeurs dans l’ordre (de la plus grande à la plus petite ou de la plus petite à la plus grande) et renvoie la valeur du milieu.
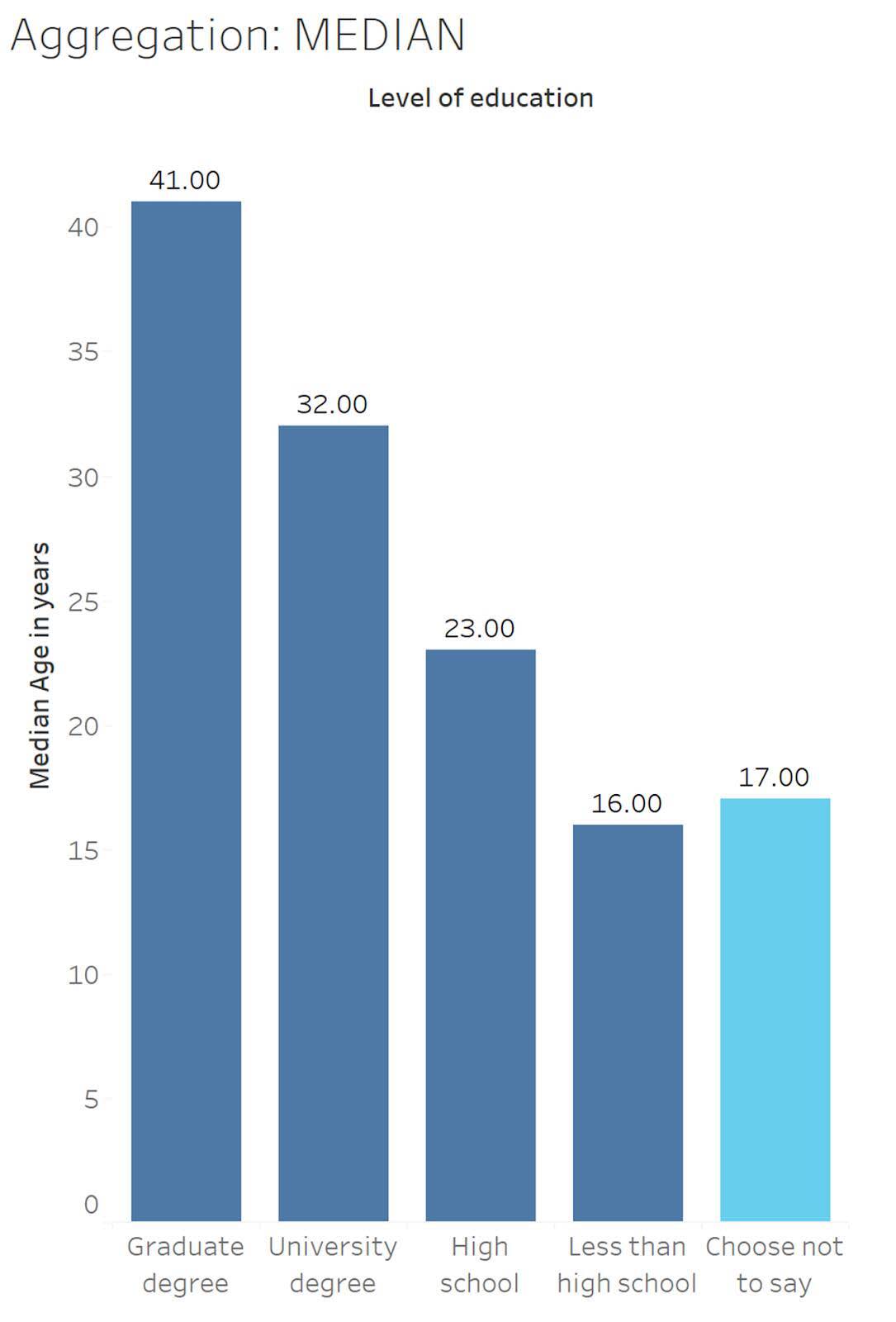
En regardant le niveau d’éducation Choose not to say (Choisir de ne pas préciser) (affiché en bleu clair), l’âge médian est de 17 ans.
13, 13, 13, 13, 15, 16, 16, 16, 17, 17, 18, 20, 20, 23, 37, 45, 53, 65, 68
À partir de ce graphique, nous pouvons voir que les âges médians sont un peu plus bas. On peut s’attendre à des médianes inférieures, car il n’y a pas de limite d’âge pour répondre au questionnaire, tandis que les participants doivent avoir au moins 13 ans pour participer. Cela signifie qu’il ne peut y avoir de valeurs extrêmes pour les jeunes qui feraient baisser la moyenne. De plus, les tendances générales apparaissent toujours : plus les participants sont instruits, plus ils sont âgés.
Affichage des effets des agrégations Minimum et Maximum
L’agrégation Minimum renvoie la plus petite valeur dans les données sélectionnées, et l’agrégation Maximum la valeur la plus élevée.

En regardant le niveau d’éducation Choose not to say (Choisir de ne pas préciser) (affiché en bleu clair), l’âge minimal (ans) est de 13 ans.
13, 13, 13, 13, 15, 16, 16, 16, 17, 17, 18, 20, 20, 23, 37, 45, 53, 65, 68
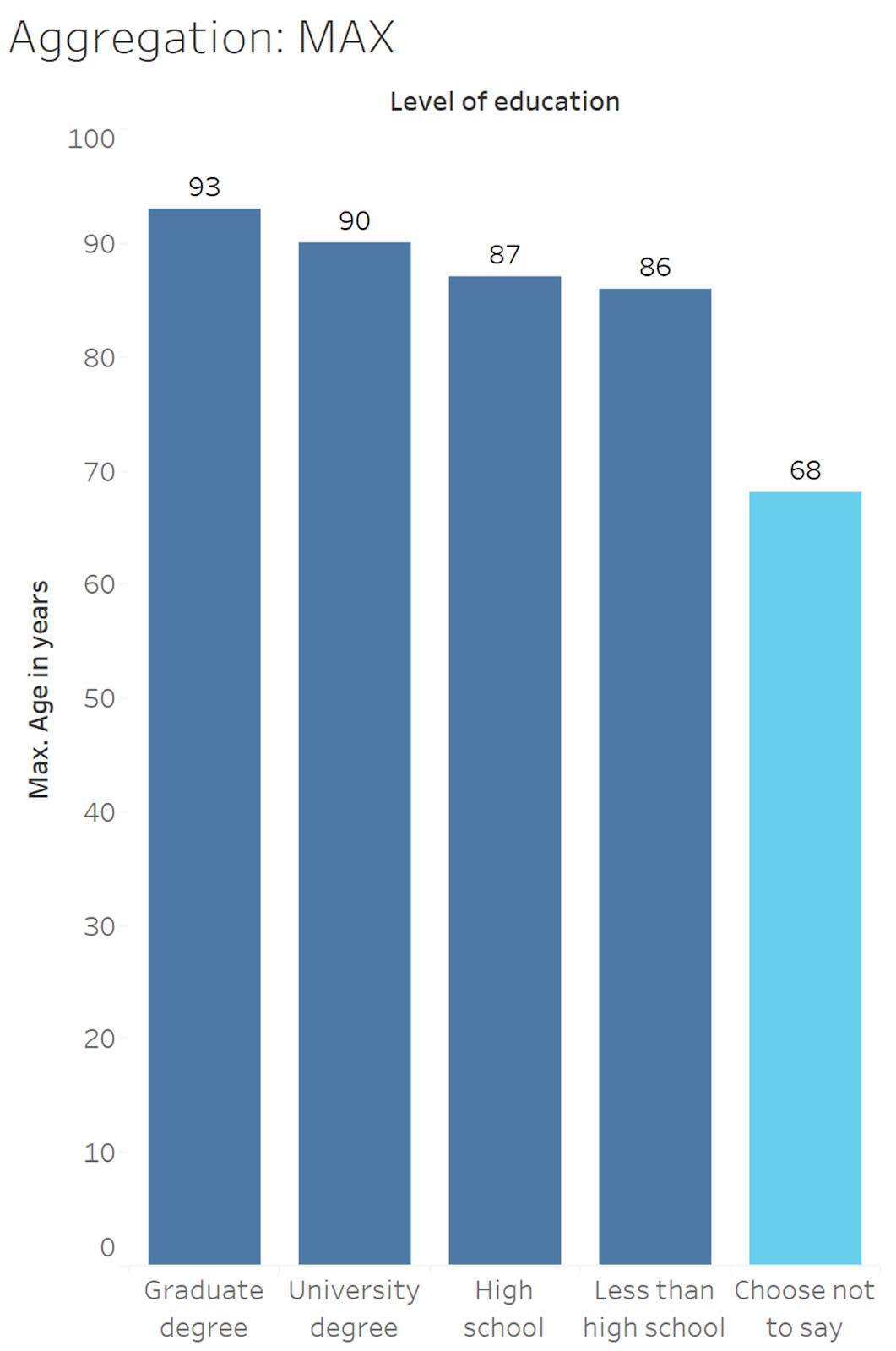
En regardant le niveau d’éducation Choose not to say (Choisir de ne pas préciser) (affiché en bleu clair), l’âge maximal (ans) est de 68 ans.
13 , 13 , 13 , 13 , 15 , 16 , 16 , 16 , 17 , 17 , 18 , 20 , 20 , 23 , 37 , 45 , 53 , 65 , 68
Affichage des effets de l’agrégation de décompte
Découvrons maintenant ce qu’il se passe si la variable Age (Âge) est agrégée sous forme de décompte. L’agrégation de décompte renvoie le nombre de valeurs dans les données pour la catégorie sélectionnée. Cela signifie que nous ne regardons plus l’âge, mais plutôt le nombre de participants.
En regardant le niveau d’éducation Choose not to say (Choisir de ne pas préciser), le décompte est de 19 et le décompte approximatif est de 12. Le décompte approximatif est de 12, car quatre participants avaient 13 ans, deux participants avaient 16 ans et deux avaient 20 ans. Nous ne comptons les valeurs 12, 13 et 20 qu’une seule fois, car l’agrégation de décompte approximatif ne compte que les valeurs uniques.
|
Le décompte est de 19 13 13 13 13 15 16 16 16 17 17 18 20 20 23 37 45 53 65 68 |
Alors que le total distinct est de 12 13 15 16 17 18 20 23 37 45 53 65 68 |
|---|
Les décomptes nous montrent que très peu de participants ont refusé de fournir leur niveau d’éducation.
Exemple de désagrégation
Le premier graphique que vous avez consulté était une vue complètement agrégée des données : il y avait une seule valeur, la somme globale. Ensuite, l’ensemble complet de données a été désagrégé par niveau d’éducation pour montrer la répartition de la somme des âges pour chaque niveau d’éducation. Au lieu d’examiner la somme (ou la moyenne ou le minimum) de tous les âges dans l’ensemble de données, chaque barre est agrégée au niveau de chaque catégorie d’éducation. Les données sont toujours agrégées, mais à un niveau plus détaillé.
|
|
|---|


Revenons à présent aux données d’origine.

Chaque ligne représente un participant. Si nous voulions voir l’âge de chaque participant au lieu d’une valeur agrégée, nous pourrions désagréger complètement les données ou représenter chaque point de l’ensemble de données.
Affichage des effets de la désagrégation des données

Ce graphique utilise la dispersion pour répartir les points de données ou les repères. La dispersion fait référence au placement aléatoire des repères le long d’un axe qui n’a pas d’intervalles (ici, l’axe des abscisses) pour permettre de révéler la densité des données. S’il n’y avait pas de dispersion, les notes seraient toutes empilées sur une seule ligne verticale par niveau d’éducation. Dans un graphique de dispersion, l’emplacement horizontal d’un repère est aléatoire et n’a aucune signification particulière.
Dans cette visualisation, nous pouvons voir qu’il y a plus de participants plus jeunes et moins de participants à mesure que l’âge augmente. Nous pouvons également constater que, bien qu’il y ait des participants plus âgés dans la catégorie Less than high school (Moins que le secondaire), la majorité est assez jeune (moins de vingt ans). La catégorie High school (Secondaire) comprend le plus de participants au début de la vingtaine, ce qui pourrait indiquer qu’ils sont actuellement étudiants à l’université. Il y a également très peu de participants diplômés d’études supérieures âgés de moins de 20 ans. Les données désagrégées correspondent assez bien aux attentes réalistes basées sur ce que nous savons sur l’âge et le niveau d’éducation.
À vous !
Défi : vous disposez du tableau suivant, qui contient trois lignes de données concernant le nombre de journaux lus par différentes personnes chaque semaine.
Nom |
Journaux lus par semaine |
|---|---|
Brooklyn |
2 |
Morgan |
3 |
Vaida |
7 |
Comment les valeurs de la variable Newspapers read per week (Journaux lus par semaine) (2, 3 et 7) seraient-elles être agrégées sous forme de somme, de moyenne, de médiane, de minimum, de maximum et de décompte ? Prenez un moment pour y réfléchir, puis vérifiez vos réponses à l’aide des fiches interactives ci-dessous.
Lisez le type d’agrégation sur chaque fiche, réfléchissez à la valeur qu’aurait cette agrégation, puis cliquez sur la fiche pour révéler la bonne réponse. Cliquez sur la flèche vers la droite pour passer à la fiche suivante et sur la flèche vers la gauche pour revenir à la précédente.
Vous avez découvert les effets des différentes agrégations sur les données, ainsi que les conséquences de la désagrégation de données. Dans l’unité suivante, vous approfondirez ces concepts en abordant la granularité.
Ressources