Load Your Data
Learning Objectives
After completing this unit, you’ll be able to:
- Describe the benefits of lean data loading in Salesforce.
- Understand the advantages of Bulk API over SOAP API when loading large amounts of data.
- Speed up the process of loading large data sets by suspending data validation and enrichment operations.
Loading Lean
Whether we’re talking LDV migration or ongoing large data sync operations, minimizing the impact these actions have on business-critical operations is the best practice. A smart strategy for accomplishing this is loading lean—including only the data and configuration you need to meet your business-critical operations.
What does loading lean entail?
- Identifying the business-critical operations before moving users to Salesforce.
- Identifying the minimal data set and configuration required to implement those operations.
- Defining a data and configuration strategy based on the requirements you’ve identified.
- Loading the data as quickly as possible to reduce the scope of synchronization.
When deciding on your data loading and configuration strategy, consider these setup options, which enable you to defer non-critical processes and speed LDV loading.
Organization-wide sharing defaults. When you load data with a Private sharing model, the system calculates sharing as the records are being added. If you load with a Public Read/Write sharing model, you can defer this processing until after cutover.
Complex object relationships. The more lookups you have defined on an object, the more checks the system has to perform during data loading. But if you’re able to establish some of these relationships in a later phase, that makes loading go faster.
Sharing rules. If you have ownership-based sharing rules configured before loading data, each record you insert requires sharing calculations if the owner of the record belongs to a role or group that defines the data to be shared. If you have criteria-based sharing rules configured before loading data, each record with fields that match the rule selection criteria also requires sharing calculations.
Workflow rules, validation rules, and triggers. These are powerful tools for making sure data entered during daily operations is clean and includes appropriate relationships between records. But they can also slow down processing if they’re enabled during massive data loads.
But Not Too Lean
While it’s smart to remove barriers to faster data loading, it’s also important to remember that a few pieces of your configuration are essential (or at least highly desired) during any data load and should not be messed with:
-
Parent records with master-detail children. You won’t be able to load child records if the parents don’t already exist.
-
Record owners. In most cases, your records will be owned by individual users, and the owners need to exist in the system before you can load the data.
-
Role hierarchy. You might think that loading would be faster if the owners of your records were not members of the role hierarchy. But in almost all cases, the performance would be the same, and it would be considerably faster if you were loading portal accounts. So there’s no benefit to deferring this aspect of configuration.
Bulk API vs. SOAP API Data Loading
When you’re loading LDV, the API you choose makes a difference. The standard SOAP API is optimized for real-time client applications that update a few records at a time. SOAP API requires developers and administrators to implement complex processes to upload data in bite-sized chunks, monitor results, and retry failed records. This method is acceptable for small data loads, but becomes unwieldy and time-consuming with large data sets.
Bulk API, on the other hand, is designed to make it simple to process data from a few thousand to millions of records. Bulk API is based on REST principles and was developed specifically to simplify and optimize the process of loading or deleting large data sets.
Using Bulk API for LDV allows for super-fast processing speeds, along with reduced client-side programmatic language, easy-to-monitor job status, automatic retry of failed records, support for parallel processing, minimal roundout trips, minimal API calls, limited dropped connections, and easy-to-tune batch size. Simply put, it’s the quickest way to insert, query, and delete records.
How Bulk API Works
When you upload records using Bulk API, those records are streamed to create a new job. As the data rolls in for the job, it’s stored in temporary storage and then sliced up into user-defined batches (10,000 records max). Even as your data is still being sent to the server, the platform submits the batches for processing.
Batches can be processed in parallel or serially depending on your needs. The Bulk API moves the functionality and work from your client application to the server. The API logs the status of each job and tries to reprocess failed records for you automatically. If a job times out, the Bulk API automatically puts it back in the queue and re-tries it for you.
Each batch is processed independently, and once the batch finishes (successful or not), the job is updated with the results. Jobs can be monitored and administrated from the Salesforce.com Admin UI by anyone with appropriate access.
Increase Speed by Suspending Events
When you need to load an LDV quickly, it’s important to ensure that each insert is as efficient as possible. With the right prep and post-processing, you can disable data validation and enrichment operations while loading —without compromising your data integrity or business rules.
The platform includes powerful tools for making sure data entered by your users is clean and includes appropriate relationships between records. Validation rules ensure that the data users enter for new and existing records meets the standards specified by your business. Workflow rules allow you to automate field updates, email alerts, outbound messages, and tasks associated with workflow, approvals, and milestones. Triggers allow you to manipulate data and perform other actions on record insert.
While these tools allow you to preserve data integrity during normal operations, they can also slow inserts to a crawl if you enable them during massive data loads. But if you turn off validation, workflow, and triggers, how can you be sure that once you’ve finished loading, you have accurate data and the right relationships established between objects? There are three key phases to this effort—analyzing and preparing data, disabling events for loading, and post-processing.
Analyzing and Preparing Data
To load safely without triggers, validation rules, and workflow rules running, examine the business requirements that you could ordinarily meet with these operations, then answer a couple of questions.
First, which of your requirements can you meet by data cleansing before data loading, or by sequencing load operations where there are critical dependencies between objects? For example, if you normally use a validation rule to ensure that user entries are within valid ranges, you can query the data set before loading to find and fix records that don’t conform to the rules.
Second, which of your requirements can you meet by post-processing records after data loading? A typical set of use cases here relates to data enrichment—which could involve adding lookup relationships between objects, roll-up summary fields to parent records, and other data relationships between records.
Disabling Events for Loading
Once you’ve analyzed all your data validation and enrichment requirements, and planned actions to manage them either before or after data loading, you can temporarily disable your rules and triggers to speed up loading. Simply edit each rule and set it to “inactive” status. You can disable Validation, Lead and Case assignment rules, and Territory assignment rules in the same way.
Temporarily disabling triggers is a little more complex and requires some preparation. First, create a Custom Setting and a corresponding checkbox field to control when a trigger should fire. Then include a statement in your trigger code like the one highlighted in this example.
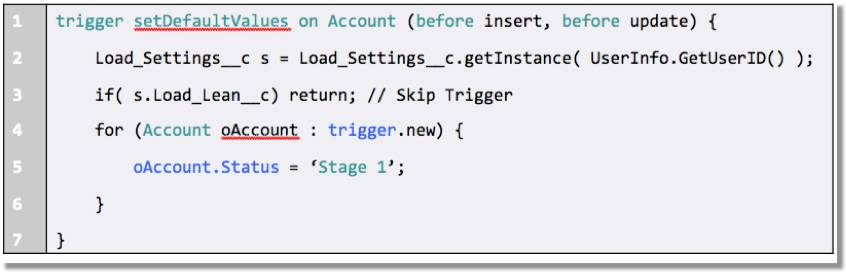
Once this is done, disabling or enabling your trigger is as simple as editing the checkbox field.
Post-Processing
When you’ve finished loading your data, it’s time to complete the data enrichment and configuration tasks you’ve deferred until this point:
- Add lookup relationships between objects, roll-up summary fields to parent records, and other data relationships between records using Batch Apex or Bulk API.
- Enhance records in Salesforce with foreign keys or other data to facilitate integration with your other systems using Batch Apex or Bulk API.
- Reset the fields on the custom settings you created for triggers, so they’ll fire appropriately on record creation and updates.
- Turn validation, workflow, and assignment rules back on so they’ll trigger the appropriate actions as users enter and edit records.
So there you have it: By loading lean, using Bulk API, and suspending events, you can be sure your data loads are efficient, as quick as possible, and retain their integrity. And now that we’ve gone over loading data, move on to the next unit where we cover deleting and extracting it.

Resources
- Salesforce Developer: Bulk API Developer Guide
- Salesforce Developer: Extreme Force.com Data Loading, Part 2: Loading into a Lean Salesforce Configuration
- Salesforce Developer: Extreme Force.com Data Loading, Part 3: Suspending Events that Fire on Insert
- Salesforce Developer: Extreme Force.com Data Loading, Part 4: Sequencing Load Operations
- Salesforce Developer: Extreme Force.com Data Loading, Part 5: Loading and Extracting Data