Descubrir técnicas y aplicaciones de IA
Objetivos de aprendizaje
Después de completar esta unidad, podrá:
- Identificar casos de uso prácticos de IA.
- Identificar las limitaciones de ChatGPT y otros modelos de IA.
- Comprender el ciclo de vida de los datos para la IA y la importancia de la privacidad de los datos y la seguridad en las aplicaciones de IA.
Trailcast
Si desea escuchar una grabación de audio de este módulo, utilice el siguiente reproductor. Cuando termine de escuchar la grabación, recuerde volver a cada unidad, consultar los recursos y completar las tareas asociadas.
Tecnología de inteligencia artificial
La inteligencia artificial es el extenso campo que hace referencia enseñar a las máquinas a aprender y pensar como los seres humanos. Existen muchas tecnologías que incluyen IA.
- El aprendizaje automático utiliza varios algoritmos matemáticos para obtener perspectivas de los datos y realizar predicciones.
- El aprendizaje profundo utiliza un tipo específico de algoritmo llamado red neuronal para encontrar asociaciones entre un conjunto de entradas y salidas. El aprendizaje profundo es más eficaz a medida que aumenta la cantidad de datos.
- El procesamiento de lenguaje natural es una tecnología que permite que las máquinas tomen el lenguaje de los seres humanos como entrada y realicen acciones en consecuencia.
- Los modelos de lenguaje grandes son modelos informáticos avanzados diseñados para comprender y generar textos similares al de los seres humanos.
- La visión artificial es una tecnología que permite que las máquinas interpreten información visual.
- La robótica es una tecnología que permite que las máquinas realicen tareas físicas.
Consulte el módulo de Trailhead Aspectos fundamentales de la inteligencia artificial para obtener más información.
El aprendizaje automático (ML) puede clasificarse en varios tipos según el enfoque de aprendizaje y la naturaleza del problema que se esté resolviendo.
-
Aprendizaje supervisado: En este enfoque de aprendizaje automático, un modelo aprende de datos etiquetados, realizando predicciones basadas en los patrones que encuentra. Después, el modelo puede realizar predicciones o clasificar datos nuevos no vistos basándose en los patrones que ha aprendido durante el entrenamiento.
-
Aprendizaje no supervisado: En este caso, el modelo aprende de datos no etiquetados, buscando patrones y relaciones sin salidas predefinidas. El modelo aprende para identificar similitudes, agrupar puntos de datos similares o encontrar patrones ocultos subyacentes en el conjunto de datos.
-
Aprendizaje de refuerzo: Este tipo de aprendizaje implica que un agente aprenda a partir de pruebas y errores, realizando acciones para maximizar las recompensas recibidas de un entorno. El aprendizaje de refuerzo suele utilizarse en escenarios en los que es necesario aprender una estrategia de toma de decisiones óptima mediante pruebas y errores, como en robótica, en juegos y en sistemas autónomos. El agente explora diferentes acciones y aprende de las consecuencias de esas acciones para optimizar el proceso de toma de decisiones.
Las herramientas de AutoML y de IA sin código, como OneNine IA y Salesforce IA se han introducido en los últimos años para automatizar el proceso de creación de una canalización completa de aprendizaje automático, con la mínima intervención de los seres humanos.
La función del aprendizaje automático
El aprendizaje automático es un subconjunto de inteligencia artificial que utiliza algoritmos estadísticos para permitir que los ordenadores aprendan de datos, sin que estén programados específicamente. Utiliza algoritmos para crear modelos que puedan realizar predicciones o tomar decisiones basadas entradas.
Aprendizaje automático en comparación con la programación
En la programación tradicional, el programador debe tener un conocimiento claro sobre el problema y la solución que se intenta conseguir. En el aprendizaje automático, el algoritmo aprende de los datos y genera sus propias reglas o modelos para solventar el problema.
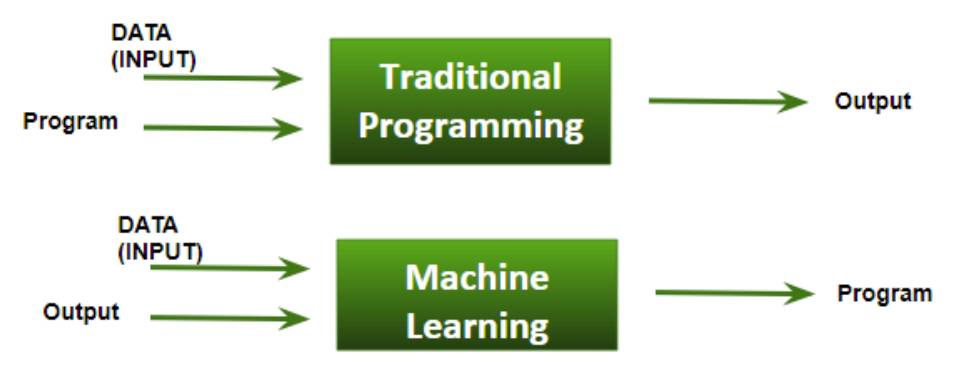
La importancia de los datos en el aprendizaje automático
Los datos son el combustible del aprendizaje automático. La calidad y la cantidad de datos utilizados en el entrenamiento de un modelo de aprendizaje automático puede tener un impacto significativo en su precisión y eficacia. Es fundamental asegurar que los datos utilizados sean relevantes, precisos, imparciales y que estén completos.
Calidad de datos y limitaciones del aprendizaje automático
Para asegurar la calidad de los datos, es necesario limpiar y preprocesar los datos, eliminando cualquier información no deseada o sin importancia, los valores que faltan o los valores atípicos.
Mientras que el aprendizaje automático es una herramienta potente para solventar una amplia variedad de problemas, también existen limitaciones en cuanto a su eficacia, entre las que se incluyen el sobreajuste, el subajuste y el sesgo.
- El sobreajuste se produce cuando el modelo es demasiado complejo y se ajusta demasiado a los datos de entrenamiento, lo que tiene como resultado una falta de generalización.
- El subajuste se produce cuando el modelo es demasiado sencillo y no captura los patrones subyacentes de los datos.
- El sesgo se produce cuando el modelo está entrenado con datos que no representan a las personas del mundo real.
El aprendizaje automático está limitado por la calidad y la cantidad de los datos utilizados, la falta de transparencia en los modelos complejos, la dificultad a la hora de generalizar para situaciones nuevas, los desafíos al gestionar los datos que faltan y la posibilidad de predicciones sesgadas.
A pesar de que el aprendizaje automático es una herramienta potente, es importante ser consciente de estas limitaciones y tenerlas en cuenta al diseñar y utilizar modelos de aprendizaje automático.
IA predictiva en comparación con la IA generativa
La IA predictiva es el uso de los algoritmos del aprendizaje automático para realizar predicciones o tomar decisiones según las entradas de datos. Se puede utilizar en una gran cantidad de casos, entre los que se incluyen la detección de fraudes, los diagnósticos médicos y las predicciones de abandono de los clientes.
Enfoques distintos, propósitos diferentes
La IA predictiva es un tipo de aprendizaje automático que entrena un modelo para realizar predicciones o tomar decisiones según los datos. Se le proporciona un conjunto de datos de entrada al modelo y este aprende a reconocer patrones en los datos que permiten realizar predicciones precisas para nuevas entradas. La IA predictiva se utiliza mucho en aplicaciones como el reconocimiento de imágenes, el reconocimiento de habla y el procesamiento del lenguaje natural.
Por otra parte, la IA generativa crea nuevo contenido, como imágenes, vídeos o texto, basándose en una entrada proporcionada. En lugar de hacer predicciones basadas en datos existentes, la IA generativa crea nuevos datos similares a los datos de entrada. Se puede utilizar en una gran cantidad de casos, entre los que se incluyen el arte, los la música y la escritura creativa. Un ejemplo común de IA generativa es el uso de redes neuronales para generar nuevas imágenes basadas en un conjunto de entradas dado.
A pesar de que la IA predictiva y la IA generativa son enfoques diferentes de inteligencia artificial, no son mutuamente excluyentes. De hecho, muchas aplicaciones de IA utilizan tanto la técnica predictiva como la generativa a fin de conseguir sus objetivos. Por ejemplo, un bot de chat utiliza IA predictiva para comprender la entrada de un usuario; además, utiliza IA generativa para generar una respuesta similar a la que elaboraría un ser humano. En general, la elección de IA predictiva o generativa depende de la aplicación específica y de los objetivos del proyecto.
Ahora ya tiene algunos conocimientos sobre la IA predictiva y la IA generativa, y de sus diferencias. Este es un pequeño resumen a modo de referencia de lo que puede hacer cada una.
IA predictiva |
IA generativa |
|---|---|
Puede realizar predicciones precisas basadas en datos etiquetados |
Puede generar contenido nuevo y creativo |
Se puede utilizar para resolver una gran cantidad de problemas, entre los que se incluyen la detección de fraudes, los diagnósticos médicos y las predicciones de abandono de los clientes |
Se puede utilizar en una gran cantidad de casos, entre los que se incluyen el arte, la música y la escritura |
Está limitada por la calidad y la cantidad de los datos etiquetados disponibles |
Puede generar contenido inapropiado o sesgado basado en los datos de entrada |
Es posible que tenga dificultades a la hora de realizar predicciones fuera de los datos etiquetados con los que se entrenó |
Es posible que tenga dificultades para comprender el contexto o generar contenido coherente |
Es posible que requiera recursos informáticos significativos para entrenar y desarrollar |
Es posible que no sea compatible con todas las aplicaciones, como las que requieren precisión y exactitud |
Limitaciones de la IA generativa
La IA generativa crea nuevo contenido, como imágenes, vídeos o texto, basándose en una entrada proporcionada. ChatGPT, por ejemplo, es un modelo de IA generativa que puede generar respuestas similares a las que proporcionaría un ser humano para las entradas de texto. Funciona entrenando grandes cantidades de datos de texto y aprendiendo a predecir la siguiente palabra en una secuencia basándose en las palabras anteriores.
A pesar de que ChatGPT puede generar respuestas parecidas a las de los seres humanos, es posible que genere respuestas sesgadas o inapropiadas basadas en los datos con los que se entrenó. Este es un problema común con los modelos de aprendizaje automático, ya que pueden reflejar los sesgos y limitaciones de los datos de entrenamiento. Por ejemplo, si los datos de entrenamiento contienen lenguaje negativo u ofensivo, es posible que ChatGPT genere respuestas que también lo sean.
También es posible que ChatGPT tenga dificultades para comprender el contexto de entrada del usuario o para generar respuestas coherentes. La eficacia de ChatGPT depende de los datos con los que se ha entrenado. Si los datos de entrenamiento están incompletos, sesgados o tienen fallos, es posible que el modelo no pueda generar respuestas precisas o útiles. Esta puede ser una limitación significativa en las aplicaciones en las que la precisión y la relevancia son importantes. De forma similar a otros modelos de aprendizaje automático, os datos juegan una función importante, por lo que si los datos con los que están entrenados son malos, ChatGPT no será muy útil.
El ejemplo de ChatGPT demuestra la función primordial que tienen los datos al utilizar la IA de manera eficaz.
Ciclo de vida de los datos para la IA
El ciclo de vida de los datos se refiere a las etapas por las que pasan los datos, desde la recopilación inicial hasta su futura eliminación. El ciclo de vida de los datos para la IA consiste en una serie de pasos, entre los que se incluyen la recopilación, el procesamiento, el entrenamiento, la evaluación y la implementación. Es importante asegurar que los datos que se utilizan sean relevantes, precisos, estén completos y no sesgados, y de que los modelos generados sean eficaces y éticos.
El ciclo de vida de los datos para la IA es un proceso continuo, ya que hay que actualizar y perfeccionar los modelos frecuentemente basándose en datos nuevos y comentarios. Se trata de un proceso repetitivo que requiere mucha atención al detalle y un compromiso con la IA ética y eficaz. Los desarrolladores y usuarios de los modelos de ML deberían asegurarse de que sus modelos son eficaces, precisos y éticos, y de que tienen un impacto positivo en el mundo. El ciclo de vida de los datos es fundamental para asegurar que los datos se recopilan, se almacenan y se utilizan de manera responsable y ética.
Estas son las etapas del ciclo de vida de los datos.
-
Recopilación de datos: En esta etapa, los datos se recopilan de varias fuentes, como sensores, encuestas y fuentes en línea.
-
Almacenamiento de datos: Una vez que los datos se han recopilado, deben almacenarse de forma segura.
-
Procesamiento de datos: En esta etapa, los datos se procesan para extraer información y patrones. Esto puede incluir el uso de algoritmos de aprendizaje automático u otras técnicas de análisis de datos.
-
Usos de datos: Una vez que se hayan procesado los datos, se pueden utilizar para su propósito previsto, como tomar decisiones o comunicar políticas.
-
Colaboración de datos: A veces, es posible que sea necesario compartir datos con otras organizaciones o personas.
-
Retención de datos: La retención de datos se refiere a la cantidad de tiempo que se almacenan los datos.
-
Eliminación de datos: Cuando los datos ya no sean necesarios, hay que eliminarlos de forma segura. Por ejemplo, eliminando de forma segura los datos digitales o destruyendo el contenido físico.
A pesar de que la IA y el aprendizaje automático tienen el potencial para revolucionar muchas empresas y para resolver problemas complejos, es importante ser consciente de sus limitaciones y consideraciones éticas. Continúe con la siguiente unidad para prender sobre la importancia de la ética y la privacidad de los datos.
Recursos
- Sitio externo: OneNine AI: AI Use Cases by Industry
- GitHub: Types of Deep Learning Models
- Trailhead: Aspectos fundamentales de la inteligencia artificial
- Publicación de blog: What are chatGPT’s limits?