Understand the Basics of Databases
Learning Objectives
After completing this unit, you’ll be able to:
- Identify five milestones in the history of databases.
- Differentiate between relational and non-relational databases.
- Define “big data.”
History of Databases
“It’s in the cloud.” This is something we hear all the time. Of course any images it conjures of vapor and foggy mist are misleading because the cloud is just a physical data center full of servers. Salesforce has many of them, all over the world. But how is all this data organized and accessed? Well, it all depends on the database. This unit is a crash course on key database concepts.
Timeline
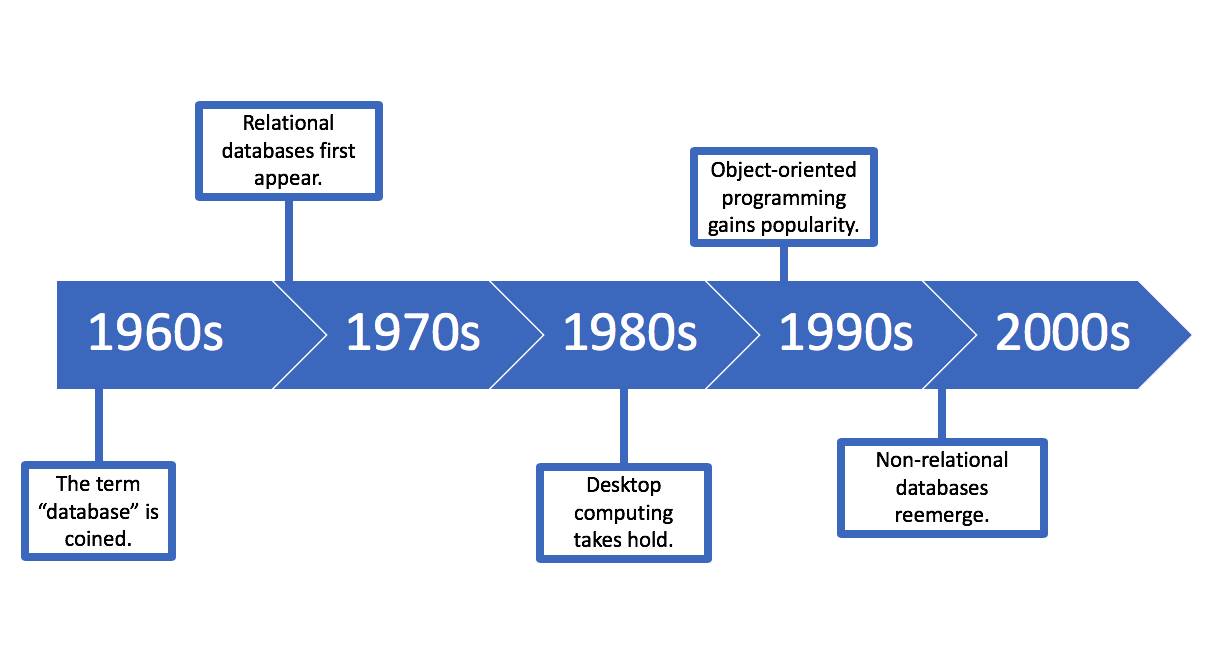
Our story begins in the 1960s, back when a computer filled a room.
Decade |
Milestones |
|---|---|
1960s |
The term “database” emerged in the early 1960s, when disks replaced tape-based storage. The first databases were non-relational, meaning they were simply linked lists of free-form records. That changed within a decade. |
1970s |
In the 1970s relational databases were introduced, and eventually became the norm. Unlike previous databases, these offered normalized, related, and searchable tables. |
1980s |
Desktop computing became widely available in the 1980s, along with user-friendly business software that interacts with underlying databases. |
1990s |
In the 1990s, object-oriented programming (OOP) made it possible to organize data by classes and attributes rather than simply tables and fields. |
2000s |
Non-relational databases made a comeback in the 2000s in the form of NoSQL (not only SQL) databases. These are simple and very scalable, so they meet the demands of big data and real-time web applications. |
Now that we’ve got a quick history lesson under our belts, let’s take a closer look at two major classifications of databases.
Relational vs. Non-relational
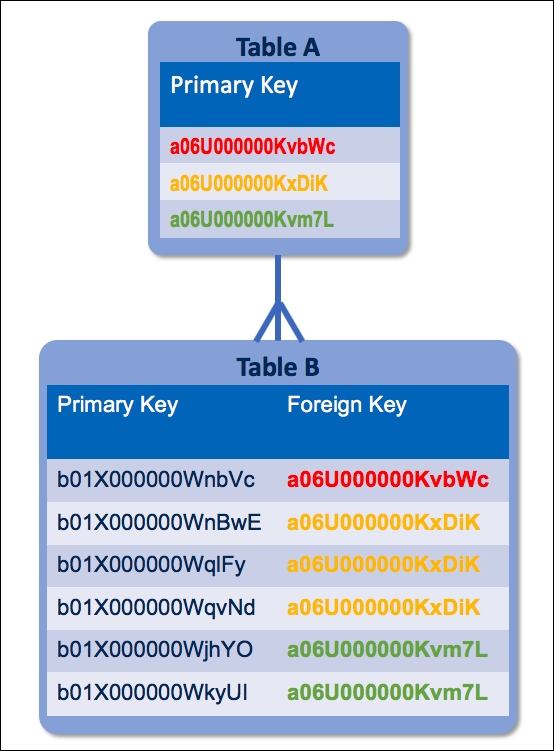
Relational databases dominated the landscape for decades, and remain relevant today. They split data across multiple related tables. Parent tables contain rows of unique identifiers called “primary keys.” Child tables reference those primary keys with other identifiers (“foreign keys”). In the diagram, Table A is the parent and Table B is the child.
Characteristics of Relational Databases
Admins and developers typically access and manipulate data in a relational database using structured query language (SQL). Transactions have four characteristics (which you can remember with the acronym ACID). Relational databases value consistency over availability.
- Atomic: All tasks must succeed, or the transaction is rolled back.
- Consistent: The state of the database must remain consistent throughout the transaction.
- Isolated: Each transaction is separate, not dependent on others.
- Durable: Data from a failed transaction can be recovered.
Relational databases are ideal for complex data analysis and operations. They follow a rigid structure, and the data must fit into it.
On the other hand, sometimes data just can’t be forced into a rigid structure. This situation began to arise in the 1990s when the Internet took off, and web applications produced data that isn’t neatly categorized. We saw a huge resurgence of non-relational databases, now sometimes called “not only SQL” or “NoSQL” databases.
Types of Non-relational Databases
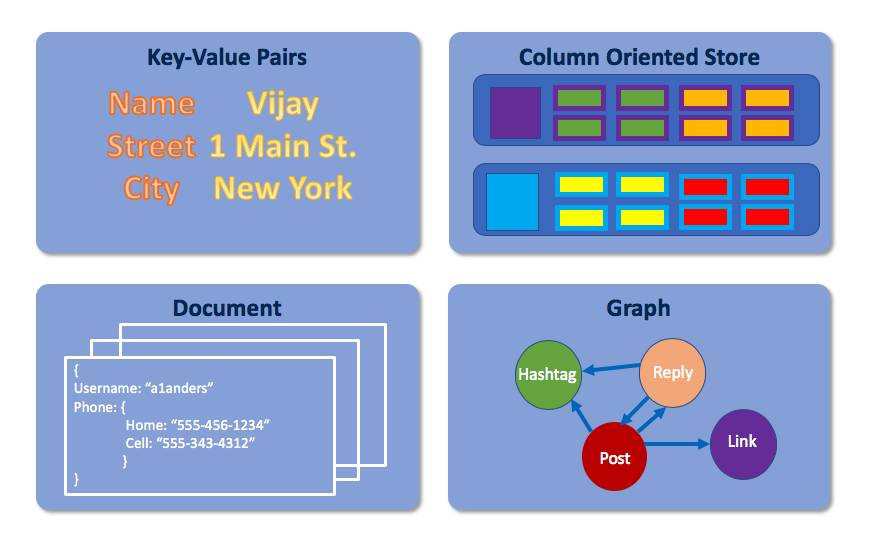
There are four.
- Key-value pairs use the associative array model, meaning data is represented in a collection of (key+value) pairs.
- Column-oriented stores use a table structure. Columns in a table can change from row to row.
- Document-oriented systems save the information for each document as a single instance in the database. Documents can be nested.
- Graphs organize elements, the relationships between elements, and attributes assigned to both elements and relationships.
Characteristics of Non-relational Databases
Non-relational databases share three qualities. (Remember them using the acronym BASE.) They value availability over consistency, the opposite of what we see in relational databases.
- Basically available: The system is available, even in the event of failure.
- Soft state: The state of the data may change.
- Eventual consistency: Consistency is not guaranteed at a transaction level, but the data is eventually synced across all nodes.
Non-relational databases are highly scalable since the structure is easy to model. Consistency can be imperfect, as there is no guarantee all clients see the same data at the same time.
Let’s compare.
Relational |
Non-relational |
|---|---|
Normalized |
Denormalized |
SQL |
Limited SQL or Asynchronous SQL |
Structured data |
Structured or unstructured data |
ACID transactions |
No or limited transactions |
There is no clear winner, as each type of database suits different business requirements. When it comes to huge volumes of information, non-relational is the way to go.
Hello, Big Data
Sounds impressive, but what is it? Big data refers to any data set too massive or complex to be handled by traditional data processing application software. We’re talking hundreds of millions (even billions) of rows. And big data is everywhere now that storage is cheap and processing is fast. Artificial Intelligence (AI) uses machine learning to process records faster than any human could.
Given all this cheapness and speed, businesses don’t want to throw data away. But how can they choose between non-relational databases (to manage the massive quantity and variety of data) vs. relational (to handle complex business logic)? The fact is, they need enterprise architecture to do it all. Multiple technologies must be integrated into one comprehensive solution.
Now that you know a bit about databases and the challenges of big data, in the next unit we find out how Salesforce can be used to store data.