Convertir datos en modelos
Objetivos de aprendizaje
Después de completar esta unidad, podrá:
- Explicar las diferencias entre los algoritmos de codificación manual y los modelos entrenados.
- Definir el aprendizaje automático y cómo se relaciona con la IA.
- Distinguir entre los datos estructurados y no estructurados, y cómo afectan a la capacitación.
Trailcast
Si desea escuchar una grabación de audio de este módulo, utilice el siguiente reproductor. Cuando termine de escuchar la grabación, recuerde volver a cada unidad, consultar los recursos y completar las tareas asociadas.
El truco que esconde la magia
Lo que la IA es capaz de hacer parece magia. Y al igual que ocurre con la magia, es normal que queramos fisgar para saber cómo se hace. Lo que encontrará es que los informáticos e investigadores utilizan muchos datos, cálculos y capacidad de procesamiento en lugar de espejos y distracciones. Conocer la manera en la que la IA funciona le ayudará a utilizarla con todo su potencial, a la vez que evitará los obstáculos causados por sus limitaciones.
El cambio de la elaboración al entrenamiento
Durante décadas, los programadores han escrito código que toman una entrada, la procesa utilizando un conjunto de reglas y devuelve un resultado. Por ejemplo, aquí puede ver cómo averiguar un resultado a partir de un conjunto de números.
- Entrada: 5, 8, 2, 9
- Proceso: Agregue los valores [5 + 8 + 2 + 9] y divídalos entre el número de entradas [4]
- Resultado: 6
Este sencillo conjunto de reglas para hacer que una entrada se convierta en un resultado es un ejemplo de algoritmo. Los algoritmos se han escrito para realizar tareas bastante sofisticadas. Pero algunas tareas tienen muchas reglas (y excepciones) que son imposibles de capturar en un algoritmo creado manualmente. La natación es un buen ejemplo de tarea que resulta difícil de encapsular como un conjunto de reglas. Es posible que reciba consejos antes de lanzarse a la piscina, pero solo descubre realmente lo que le funciona a usted una vez que intenta mantener la cabeza fuera del agua. Algunas cosas se aprenden mejor con la experiencia.
¿Qué pasaría si pudiéramos entrenar a un ordenador de la misma manera? No lanzándolo a la piscina, sino permitiendo que averigüe lo que funciona para que una tarea se complete con éxito. Sin embargo, al igual que aprender a nadar es muy diferente de aprender a hablar, el tipo de entrenamiento depende de la tarea. Veamos algunos ejemplos de cómo se entrena la IA.
Experiencia necesaria
Imagine que cada vez que va a comprar leche, realiza un seguimiento de los detalles del trayecto en una hoja de datos. Es un poco raro, pero hágalo. Establezca las siguientes columnas.
- ¿Es durante el fin de semana?
- Hora del día
- ¿Llueve o no?
- Distancia hasta la tienda
- Total de minutos del trayecto
Después de varios trayectos, empieza a hacerse una idea de cómo afectan las condiciones a la duración del trayecto. Por ejemplo, la lluvia hace que conduzca más despacio, pero también implica que haya menos gente comprando. Su cerebro realiza conexiones entre las entradas (fin de semana [F], tiempo [T], lluvia [L], distancia [D]) y el resultado (minutos [M]).
¿Pero cómo podemos hacer que un ordenador se dé cuenta de las tendencias de manera que pueda estimarlas? Una manera es el método de adivinar y comprobar. Veamos cómo hacerlo.
Paso 1: Asígnele un "peso" a todas las entradas. Este es un número que representa en qué medida afecta una entrada a un resultado. Está bien empezar con el mismo peso para todo.
Paso 2: Utilice los pesos con los datos existentes (y algunos cálculos inteligentes que no veremos aquí) para estimar los minutos de la trayectoria para conseguir la leche. Podemos comparar los datos estimados con los datos históricos. Serán muy diferentes, pero no pasa nada.
Paso 3: Deje que el ordenador estime un nuevo peso para cada entrada, haciendo que algunas sean más importante que otras. Por ejemplo, es posible que el momento del día sea más importante que el hecho de que esté lloviendo o no.
Paso 4: Repita los cálculos para comprobar si los nuevos pesos hacen que el resultado esté mejor estimado. Si es así, significará que los pesos están mejor ajustados, y se han cambiado para bien.
Paso 5: Repita los pasos 3 y 4, haciendo que el ordenador modifique los pesos hasta que la estimación sea lo mejor posible.
En este punto, el ordenador ha establecido los pesos para cada entrada. Si piensa en los pesos como la medida en la que una entrada está conectada al resultado, puede hacer un diagrama que utilice el grosor de líneas para representar el peso de una conexión.
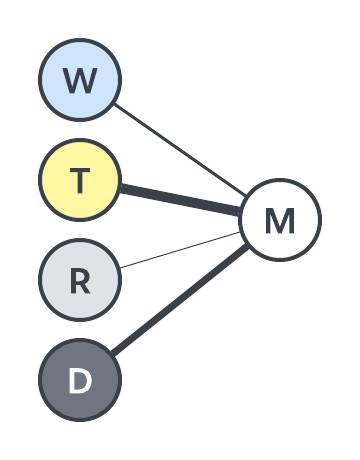
En este ejemplo, parece que el momento del día tiene la mayor conexión; sin embargo, la lluvia no hace que cambie tanto.
Este proceso de adivinar y comprobar ha creado un modelo para nuestra trayectoria de ir a comprar leche. Y, al igual que un modelo de barco, podemos meterlo en el agua para ver si flota, por así decirlo. Es decir, probarlo en el mundo real. Así que, las siguientes veces que vaya a ir a comprar leche, antes de salir, haga que el modelo estime cuánto tardará en hacerlo. Si los datos son correctos varias veces seguidas, puede permitir que realice las estimaciones en cada trayecto con seguridad.

[Imagen realizada con IA utilizando DreamStudio en stability.ai con el mensaje "Un robot en una mesa de trabajo uniendo las piezas de un barco velero pequeño. La imagen está realizada con un estilo de vector 2D".]
Uso de los datos correctos para el trabajo adecuado
Este es un ejemplo muy sencillo del uso del entrenamiento para realizar un modelo de IA, pero también aborda algunas ideas importantes. En primer lugar, es un ejemplo de aprendizaje automático (ML), que es el proceso que consiste en utilizar grandes cantidades de datos para entrenar un modelo con el fin de que realice predicciones, en lugar de elaborar un algoritmo de forma manual.
En segundo lugar, no todos los datos son los mismos. En el ejemplo de la leche, la hoja de datos es lo que llamaríamos datos estructurados. Están bien organizados, con etiquetas en cada columna para que sepa lo que significa cada celda. En cambio, los datos no estructurados serían, por ejemplo, artículos de noticias o un archivo de imagen no etiquetado. El tipo de datos que tenga disponible afectará al tipo de entrenamiento que pueda realizar.
En tercer lugar, los datos estructurados de nuestra hoja de datos permiten que los ordenadores realicen un aprendizaje supervisado. Se considera supervisado porque podemos asegurarnos de que cada dato de entrada tenga un resultado esperado equivalente que podamos verificar. Por el contrario, los datos no estructurados se utilizan para el aprendizaje no supervisado, cuando la IA intenta encontrar conexiones en los datos sin saber lo que está buscando realmente.
Dejar que el ordenador averigüe el peso para cada entrada en un tipo de regla de entrenamiento. Sin embargo, a menudo los sistemas interconectados pueden presentar más dificultades que la ponderación individualizada. Afortunadamente, como verá en la siguiente unidad, hay más formas de entrenamiento.