Erkunden von Aggregation
Lernziele
Nachdem Sie diese Lektion abgeschlossen haben, sind Sie in der Lage, die folgenden Aufgaben auszuführen:
- Definieren von Aggregation
- Anwenden unterschiedlicher Aggregationstypen
Was ist Aggregation?
Eine Aggregation bezieht sich auf die Sammlung quantitativer Daten und kann wichtige Datentrends aufzeigen. Beispielsweise die Summierung aller Websuchen nach einem bestimmten Campingplatz oder das Durchschnittseinkommen aller Erwerbstätigen in einer Stadt.
In vielen Analysetools werden quantitative Variablen standardmäßig aggregiert, können aber disaggregiert (also nach Kategorie aufgeschlüsselt) werden, um Datenpunkte für jeden Wert in jeder Zeile der Datenquelle zu zeigen.

Hier sind einige gängige Aggregationen.
Aggregate (Aggregation) |
Beschreibung |
Beispiel: 3, 3, 6 |
|---|---|---|
Summe |
Der arithmetische Gesamtwert der Werte |
3 + 3 + 6 = 12 Summe = 12 |
Durchschnitt |
Der arithmetische Mittelwert der Werte (also die Summe geteilt durch die Anzahl der Werte) |
3 + 3 + 6 = 12 12 : 3 = 4 Mittelwert = 4 |
Median |
Der mittlere Wert in einer Liste von Werten, die vom kleinsten zum größten (oder vom größten zum kleinsten) sortiert sind |
3, 3, 6 Median = 3 |
Minimum |
Der kleinste Wert |
3, 3, 6 Minimum = 3 |
Maximum |
Der größte Wert |
3, 3, 6
Maximum = 6 |
Anzahl |
Die Anzahl der Werte (in einer Datentabelle die Anzahl der Zeilen oder Datensätze) |
Es gibt drei Werte
Anzahl = 3 |
|
Eindeutige Anzahl (oder unterschiedliche Anzahl) |
Die Anzahl eindeutiger Werte, wobei jeder eindeutige Wert nur einmal gezählt wird (in einer Datentabelle bezieht sich dies auf die Anzahl eindeutiger Zeilen von Datensätzen) |
Es gibt zwei eindeutige Werte: 3 und 6
Eindeutige Anzahl (oder unterschiedliche Anzahl) = 2 |
Beispiele für Aggregation
Sehen wir uns einige Beispiele für Aggregationen und ihre Auswirkungen auf die Datenanalyse an. Wir verwenden Umfragedaten, die mit einem Online-Vokabeltest verbunden sind. Jeder Teilnehmer nahm an einem Online-Vokabeltest teil und beantwortete anschließend einige demografische Fragen zu seiner Person.
Visualisierung mit einer aggregierten quantitativen Variable
Sehen Sie sich in der folgenden Visualisierung die quantitative Variable "Age" (Alter) an. Bei der Aggregation "Summe" werden alle Werte der Variable "Age" (Alter) zu einem Gesamtwert von 420.085 Jahren addiert.

Im obigen Diagramm summiert ein einzelner Balken alle Daten (12.168 Zeilen) des Datensets in einer einzigen Zahl.
Diese Summe von Age (Alter) kann nach dem höchsten Bildungsgrad aufgeschlüsselt werden, was zu einem Balken führt, der das Gesamtalter für jeden Bildungsgrad anzeigt. (Wenn man diese Wert addiert, erhält man als Ergebnis die Gesamtsumme des Einzelbalkens. 116,602 + 160.542 + 120.351 + 22.092 + 498 = 420.085.)

Wichtig: Die Summe ist hier keine geeignete Aggregation, da ein Alter von 116.602 Jahren keine Aussagekraft hat. Für einige Variablen, wie z. B. die Variable "Age" (Alter) in diesem Beispiel, ist die Aggregation "Summe" keine sinnvolle oder geeignete Darstellung der Daten. (In anderen Beispielen kann Summe jedoch eine geeignete Aggregation sein.) Beim Erstellen oder Anzeigen von Visualisierungen ist es wichtig, auf die Aggregationen zu achten, die in Analysen und Diagrammen verwendet werden.
Anzeigen zugrunde liegender Daten
Um besser zu verstehen, welche Werte summiert werden, lassen Sie uns das Rohdaten betrachten. Wenn Sie die Daten auf Zeilenebene untersuchen, sehen Sie eine Zeile für jeden Teilnehmer sowie dessen Bildungsgrad und Alter.

Für den Bildungsgrad Choose not to say (Keine Angabe) beträgt die Summe für "Age (Alter)" 498.
13 + 13 + 13 + 13 + 15 + 16 + 16 + 16 + 17 + 17 + 18 + 20 + 20 + 23 + 37 + 45 + 53 + 65 + 68 = 498 Jahre
Auswirkungen der Aggregation Mittelwert
Wir betrachten nun dasselbe Balkendiagramm wie zuvor, ändern aber die Aggregation zu Mittelwert. Anstatt alle Altersangaben zu addieren und diesen Wert anzuzeigen, entspricht die Höhe der Balken nun ihrem arithmetischen Mittelwert. Für jeden Bildungsgrad werden alle Altersangaben addiert und durch die Anzahl der Werte geteilt.

Der Mittelwert für das Alter von Personen im Bildungsgradbalken "Choose not to say (Keine Angabe) (hellblau dargestellt) beträgt 26,21 Jahre.
13 + 13 + 13 + 13 + 15 + 16 + 16 + 16 + 17 + 17 + 18 + 20 + 20 + 23 + 37 + 45 + 53 + 65 + 68 = 498
498 : 19 = 26,21
Bei den Zahlen handelt es sich nun um Altersangaben, die realistisch erscheinen (die Personen sind etwa 20 bis 43 Jahre alt). Und im Durchschnitt haben die jüngeren Befragten weniger Bildung.
Auswirkungen der Aggregation Median
Wir sehen uns nun an, wie es auswirkt, wenn Age (Alter) als Median in einem Datenset aggregiert wird. Mittelwerte können durch Extremwerte gestreckt oder verfälscht werden. Wenn beispielsweise eine Person, die 103 Jahre alt ist, an dem Quiz teilgenommen hat, könnte durch ihr Alter der Eindruck entstehen, dass ihre Bildungskategorie insgesamt ältere Teilnehmer hatte. Um das Problem der Verfälschung durch Extremwerte zu vermeiden, sortiert die Median-Aggregation alle Werte in einer Reihenfolge (vom größten zum kleinsten oder vom kleinsten zum größten) und gibt den mittleren Wert zurück.
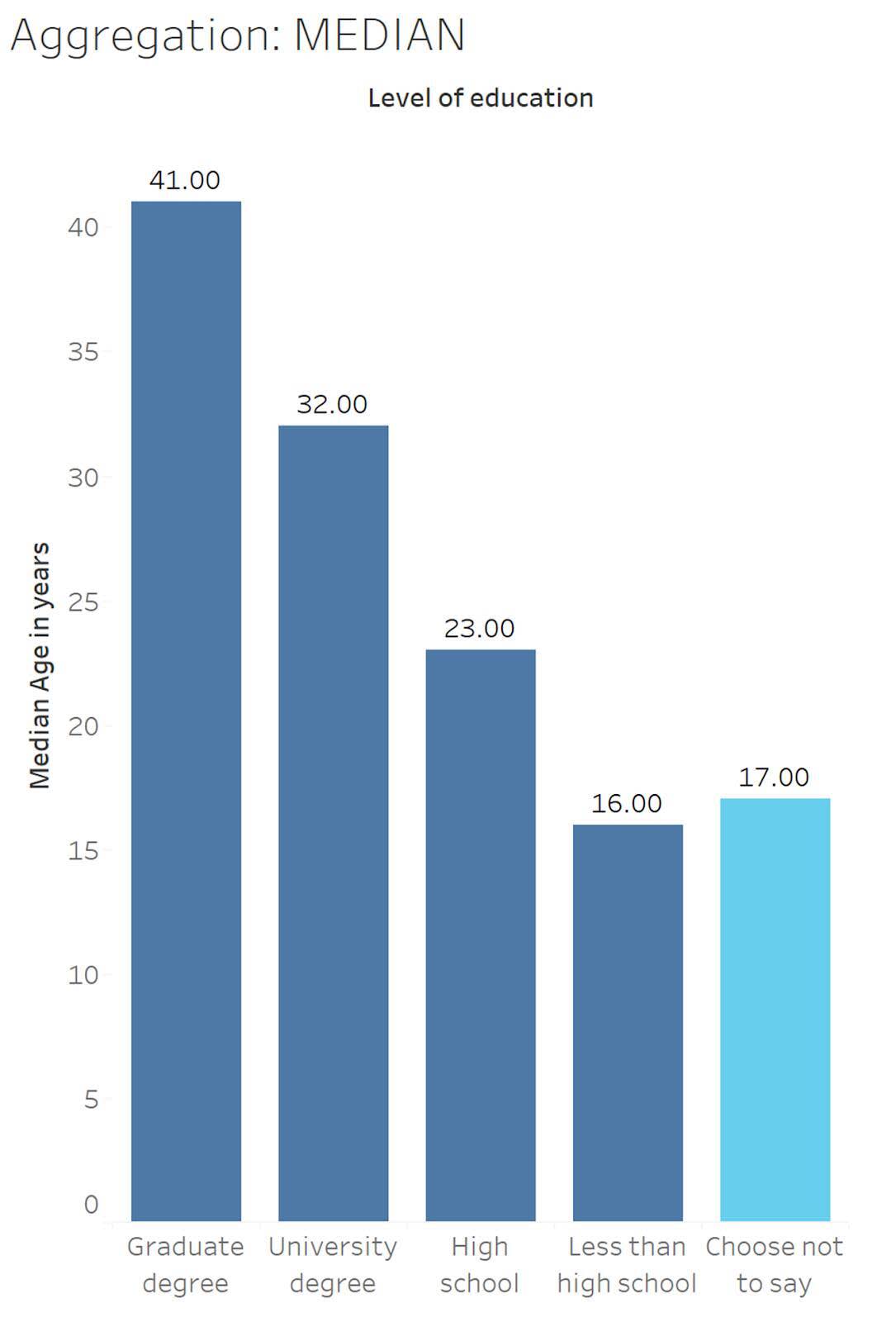
Der Median von Personen im Bildungsgradbalken "Choose not to say (Keine Angabe) (hellblau dargestellt) beträgt 17 Jahre.
13 , 13 , 13 , 13 , 15 , 16 , 16 , 16 , 17 , 17 , 18 , 20 , 20 , 23 , 37 , 45 , 53 , 65 , 68
Dieses Diagramm zeigt, dass das Medianalter etwas niedriger liegt. Niedrigere Mediane sind zu erwarten, da es kein Höchstalter für die Teilnahme am Quiz gibt, die Teilnehmer jedoch mindestens 13 Jahre alt sein müssen, um teilnehmen zu dürfen. Das bedeutet, dass es keine jungen Extremwerte geben kann, die den Durchschnitt drücken. Und die allgemeinen Trends zeigen sich weiterhin: je höher die Bildung, desto älter die Teilnehmer.
Auswirkungen der Minimum- und Maximum-Aggregationen
Die Minimum-Aggregation gibt den kleinsten Wert in den ausgewählten Daten und die Maximum-Aggregation den größten Wert zurück.

Das minimale Alter von Personen im Bildungsgradbalken "Choose not to say (Keine Angabe) (hellblau dargestellt) beträgt 13 Jahre.
13 , 13 , 13 , 13 , 15 , 16 , 16 , 16 , 17, 17 , 18 , 20 , 20 , 23 , 37 , 45 , 53 , 65 , 68

Das maximale Alter von Personen im Bildungsgradbalken "Choose not to say (Keine Angabe) (hellblau dargestellt) beträgt 68 Jahre.
13 , 13 , 13 , 13 , 15 , 16 , 16 , 16 , 17, 17 , 18 , 20 , 20 , 23 , 37 , 45 , 53 , 65 , 68
Auswirkungen der Aggregation Anzahl
Wir möchten nun feststellen, welcher Wert sich ergibt, wenn als Aggregation der Daten zum Alter die Anzahl ermittelt wird. Mit dieser Aggregation "Anzahl" wird die Anzahl der in den Daten enthaltenen Werte für die ausgewählte Kategorie zurückgegeben. Das bedeutet, dass wir nicht mehr das Alter, sondern die Anzahl der Teilnehmer betrachten.
Für den Bildungsgrad "Choose not to say (Keine Angabe)" beträgt die Anzahl 19 und die eindeutige Anzahl 12. Die eindeutige Anzahl beträgt 12, weil vier Teilnehmer 13, zwei Teilnehmer 16 und zwei Teilnehmer 20 Jahre alt waren. Die Alterswerte 12, 13 und 20 werden nur einmal gezählt, da die Aggregation nach eindeutiger Anzahl nur eindeutige Werte zählt.
|
Die Anzahl beträgt 19 13 13 13 13 15 16 16 16 17 17 18 20 20 23 37 45 53 65 68 |
Die eindeutige Anzahl beträgt dagegen 12 13 15 16 17 18 20 23 37 45 53 65 68 |
|---|
Die Anzahlen zeigen, dass es nur sehr wenige Teilnehmer gibt, die ihren Bildungsstand nicht angeben möchten.
Beispiel für Disaggregation
Das erste Diagramm, das wir uns angesehen haben, war eine vollständig aggregierte Ansicht der Daten: Es gab einen Wert, die Gesamtsumme. Dann wurde der gesamte Datensatz nach Bildungsgrad (disaggregiert), um die Aufschlüsselung der Summe der Alterswerte für jeden Bildungsgrad zu zeigen. Anstatt die Summe (oder den Mittelwert bzw. das Minimum) aller Alterswerte im Datenset zu betrachten, wird jeder Balken auf der Ebene jeder Bildungskategorie aggregiert. Die Daten sind immer noch aggregiert, aber auf einer detaillierteren Ebene.
|
|
|---|


Betrachten wir nun die ursprünglichen Daten noch einmal.

Jede Zeile steht für einen Teilnehmer. Wenn wir das Alter jedes einzelnen Teilnehmers anstelle eines aggregierten Werts sehen wollten, könnten wir die Daten vollständig disaggregieren oder jeden Punkt im Datenset darstellen.
Auswirkung des Disaggregierens von Daten

Dieses Diagramm verwendet Jitter, um die Datenpunkte oder Markierungen zu verteilen. Jitter bedeutet, dass die Markierungen nach dem Zufallsprinzip entlang einer Achse platziert werden, die keine Intervalle hat (hier die x-Achse), um die Dichte der Daten zu verdeutlichen. Ohne Jitter würden die Markierungen alle auf einer einzigen vertikalen Linie pro Bildungsstufe liegen. In einem Jitter-Diagramm ist die horizontale Position einer Markierung zufällig und transportiert keine besondere Bedeutung.
Diese Visualisierung zeigt, dass es mehr jüngere Teilnehmer und weniger ältere Teilnehmer gibt. Wir können auch sehen, dass es zwar einige ältere Teilnehmer in der Kategorie Less than high school (Weniger als High School) gibt, die Mehrheit aber recht jung ist – unter zwanzig. In der Kategorie High School liegen die meisten Alterswerte Anfang 20, was bedeuten könnte, dass dies aktuelle Hochschulstudenten sind. Es gibt auch sehr wenige Teilnehmer mit Hochschulabschluss, die jünger als 20 sind. Die disaggregierten Daten entsprechen ziemlich genau den realistischen Erwartungen, die wir aufgrund unseres Wissens über Alter und Bildungsgrad haben.
Probieren Sie es aus!
Aufgabe: Ausgangspunkt ist die folgende Tabelle mit drei Datenzeilen zur wöchentlichen Leserschaft von Zeitungen.
Name |
Pro Woche gelesene Zeitungen |
|---|---|
Bettina |
2 |
Manfred |
3 |
Viola |
7 |
Wie könnte man die Werte der Variablen Pro Woche gelesene Zeitungen (2, 3 und 7) als Summe, Mittelwert, Median, Minimum, Maximum und Anzahl aggregieren? Nehmen Sie sich etwas Zeit, um darüber nachzudenken, und überprüfen Sie Ihre Antworten dann mit Hilfe der interaktiven Karteikarten unten.
Lesen Sie den Typ der Aggregation auf jeder Karte, überlegen Sie, was der Wert für diese Aggregation sein könnte, und klicken Sie dann auf die Karte, um die richtige Antwort aufzudecken. Klicken Sie auf den Pfeil nach rechts, um zu nächsten Karte zu gelangen, bzw. den Pfeil nach links, um zur vorherigen Karte zurückzukehren.
Sie haben erkundet, wie sich Aggregationen auf Daten auswirken und welche Auswirkungen die Disaggregation von Daten hat. In der nächsten Lektion vertiefen Sie diese Konzepte, indem Sie etwas über Granularität lernen.
Ressourcen