跟随回复过程
学习目标
完成本单元后,您将能够:
- 描述回复过程。
- 解释零数据留存。
- 讨论为什么有毒语言检测很重要。

提示过程快速回顾
您已经可以看到 Salesforce 在 Einstein 信任层中为保护 Jessica 的客户数据和公司数据而采取的细致步骤。在了解更多信息之前,请快速回顾一下提示过程。
- 已自动从服务回复中提取了一个提示模板,以帮助处理 Jessica 的客户服务案例。
- 提示模板中的合并字段已填充了来自 Jessica 所在组织的可信且安全的数据。
- 相关 Knowledge 文章和其他对象的详细信息被检索并纳入提示,以增加上下文。
- 个人身份信息 (PII) 已被屏蔽。
- 额外的安全护栏已应用于提示,以提供进一步保护。
- 现在,提示已准备好通过安全网关传递给外部 LLM。
安全 LLM 网关
填充了相关数据并采取了保护措施后,提示准备通过安全 LLM 网关离开 Salesforce Trust 边界传递给连接的 LLM。在本例中,Jessica 所在组织连接的 LLM 是 OpenAI。OpenAI 使用这个提示为 Jessica 生成一个相关且高质量的回复,供她在与客户的对话中使用。
零数据留存
如果 Jessica 使用的是一个面向消费者的 LLM 工具,比如没有强大信任层的生成式 AI 聊天机器人,她的提示,包括其客户的所有数据,甚至 LLM 的回复,都可能会被 LLM 存储下来用于模型训练。但是,当 Salesforce 与外部基于 API 的 LLM 合作时,我们需要达成一项协议来确保整个交互的安全,这被称为零数据留存。采用零数据留存政策则意味着所有包含提示文本和所生成回复的客户数据都不会被存储在 Salesforce 外部。

它的工作方式是这样的。Jessica 的提示被发送到一个 LLM,记住,该提示是一条指令。LLM 会按照这个提示并遵循其中的指示和护栏,生成一个或多个回复。
通常,OpenAI 希望将提示和回复保留一段时间,以监测滥用行为。OpenAI 非常强大的 LLM 会检查其模型是否出现异常情况,比如您在上个单元中学到的提示注入攻击。但是零数据留存政策可防止 LLM 合作伙伴保留任何互动数据。我们达成了一项协议来管理这个问题。
我们不允许 OpenAI 存储任何数据。所以当一个提示被发送到 OpenAI 时,一旦回复被发送回 Salesforce,模型就会将提示和回复忘记。这一点非常重要,因为它使 Salesforce 能够处理自己的内容和管理滥用行为。此外,像 Jessica 这样的用户不必担心 LLM 提供商保留和使用其客户的数据。
回复过程
当我们首次介绍 Jessica 时,我们提到她有点担心 AI 生成的回复可能与她平时表现出的风格不符。她真的不确定会发生些什么,但她不需要担心,因为 Einstein 信任层已经考虑到了这个问题。它包含了几个功能,有助于保持对话的个性化和专业化。

到目前为止,我们已经看到了 Jessica 与客户对话的提示模板中填充了相关的客户信息和与该案例相关的有用上下文。现在,LLM 已经消化了这些详情,并将回复传递回 Salesforce Trust 边界内。但是,Jessica 还不能看到这些回复。虽然语气友好且内容准确,但它仍需要被信任层检查是否存在意外的输出内容。回复中仍然包含被屏蔽的数据块,而 Jessica 会认为这种回复完全体现不出个人风格,不适合与客户分享。信任层还需要执行一些更重要的操作才能将回复分享给她。

<NAME_1>,您好!很高兴和您交谈。很抱歉您今天在升级信用卡时遇到了麻烦——我们感谢您与 <COMPANY_1> 超过 5 年的合作关系,我们会尽快解决这个问题。
是的,我们的某些信用卡产品要求*有最低信用分数。您能告诉我更多关于您在申请过程中遇到的麻烦吗?
来源:Cumulus 卡片升级最低要求
有毒语言检测和数据解蔽
当针对 Jessica 对话的回复从 LLM 返回到 Salesforce Trust 边界内时,会发生两件重要的事情。首先,有毒语言检测可以保护 Jessica 和它的客户免受毒害。您问那是什么?信任层使用机器学习模型来识别和标记提示和响应中的有害内容,分为五类:暴力、性、脏话、仇恨和身体伤害。总体有害性分数结合了所有检测到的类别的分数,并生成一个范围从 0 到 1 的总体分数,1 表示最有害。初始回复的分数会连同回复一起返回给调用它的应用程序——本例中是服务回复。
接下来,在生成的响应分享给 Jessica 之前,信任层需要揭示之前提到的已屏蔽数据,以使回复对 Jessica 的客户而言具有个性化和相关性。信任层使用我们最初为屏蔽数据而保存的标记化数据对这些已屏蔽数据进行解蔽处理。将数据解蔽后,便将回复分享给 Jessica。
此外,请注意,回复底部有一个源链接。Knowledge 文章创建通过包含有帮助的源文章链接,增加了回复的可信度。

Dennis Maxfield,您好!很高兴和您交谈。很抱歉您今天在升级信用卡时遇到了麻烦——我们感谢您与 Cumulus Financial 超过 5 年的合作关系,我们会尽快解决这个问题。
是的,我们的某些信用卡产品要求*有最低信用分数。您能告诉我更多关于您在申请过程中遇到的麻烦吗?
来源:Cumulus 卡片升级最低要求
反馈框架
现在,当 Jessica 第一次看到回复时,她面露微笑。LLM 给出的回复的质量和详细程度让她印象深刻。她也对回复与她的个人处理风格非常契合感到满意。在将回复发送给客户之前,Jessica 在查看回复时发现她可以选择按原样接受、在发送前进行编辑或者将其忽略。
她还可以以点赞或点踩的形式提供定性反馈,以及如果回复没有帮助,则可以说明原因。这些反馈会被收集起来,将来可以安全地使用这些反馈来提高提示的质量。

审计跟踪
下面将向您展示信任层的最后一个部分。还记得我们在本单元开始时提及的零数据留存政策吗?由于信任层在内部处理有毒语言评分并进行管理,我们追踪整个提示到回复过程中发生的每一步。
在 Jessica 与其客户之间的整个互动过程中发生的一切都是带有时间戳的元数据,我们将其收集到审计跟踪中。这包括提示、未经筛选的原始回复、任何有毒语言分数以及在这个过程中收集的反馈。Einstein 信任层审计跟踪增加了一种责任追溯的方式,这样 Jessica 可以确保其客户的数据得到保护。
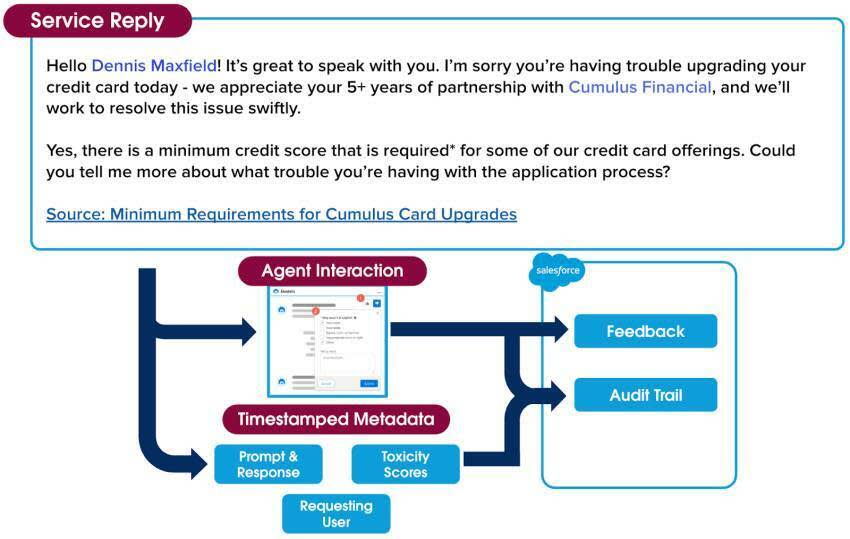
自 Jessica 为其客户提供帮助以来发生了很多事情,但这一切都发生在一眨眼之间。几秒钟内,她的对话从一个由聊天调用的提示,历经安全的完整信任层过程,变成了可与客户分享的具有相关性和专业性的回复。
她关闭了这个案例,知道她的客户对收到的回复和接受的客户服务体验感到满意。最重要的是,她很高兴能继续使用服务回复的生成式 AI 功能,因为她相信这将帮助她在更短的时间内关闭案例并让客户感到满意。
Salesforce 的每一个生成式 AI 解决方案都经历了相同的信任层过程。我们所有的解决方案都是安全的,因此您可以放心,您的数据和客户的数据也都是安全的。
恭喜,您已经了解了 Einstein 信任层的工作原理!要了解更多关于 Salesforce 在可信赖的生成式 AI 方面所做的工作,请赢得负责任地创建人工智能 Trailhead 徽章。
资源