使用 Einstein Discovery 检测和防止模型中的偏见
学习目标
完成本单元后,您将能够:
- 解释敏感类别以及如何选择它们。
- 定义和解释差别性影响。
- 定义和解释代理变量。
- 解释模型卡。
偏见的问题
Einstein Discovery 让各企业能够探索历史数据中的模式、关系和相关性。借助机器学习和人工智能的力量,Einstein 还可以预测未来的结果,从而使企业用户能够确定工作负载的优先级并做出由数据驱动的决策。
伴随这种预测能力的种种好处而来的是制作合乎道德和负责任模型的责任。建立在有偏差的历史数据基础上的模型可能会导致偏斜的预测。幸运的是,Einstein Discovery 可以帮助您检测数据中的偏见,以便您可以消除其对模型的影响。

本快速了解探索了 Einstein Discovery 的保护措施,这些保护措施可以帮助您在设计模型时识别和减轻潜在的偏见。我们的示例使用历史发票数据来最大限度地减少延迟付款的可能性。在该示例中,我们研究了邮政编码变量如何无意中将偏见引入我们的模型。
选择敏感变量分析偏见
使用敏感变量时,您可以在模型中标记变量以进行偏见分析。例如,在美国和加拿大,与年龄、种族和性别等受法律保护的类别相关的变量在使用上受到限制。在就业和雇用、贷款和医疗保健等受监管行业,对这些类别的歧视是非法的。
有时,敏感变量不像种族或性别那样明显。在我们的示例中,发票支付数据集包括邮政编码,这通常与种族相关。20 世纪 30 年代的红线政策对美国的住房存量进行了种族隔离,现在仍影响着某些邮政编码区的种族和经济构成。让我们将邮政编码标记为敏感变量,看看它如何影响我们的模型。
通过选中偏见分析复选框,Einstein Discovery 会标记您所选变量与数据集中其他变量之间的相关性。

选择复选框后,单击 Create Model(创建模型)(或者,如果您已创建模型,Train Model(训练模型))。根据对邮政编码的分析,Einstein Discovery 报告了在差别性影响和代理变量上的发现。让我们讨论一下这些术语的含义。
理解差别性影响
如果 Einstein Discovery 在您的数据中检测到差别性影响,则意味着该数据反映了针对特定人群的歧视性做法。例如,您的数据可以揭示起薪方面的性别差异。Einstein Discovery 会计算非歧视性的阈值,并根据该阈值对其他组进行评分。受监管行业的差别性影响计算值需要至少达到 80%。从您的模型中删除检测到的变量可以制作出更负责任和合乎道德的模型,进而可以产生公平公正的预测。
对于我们的发票数据,Einstein Discovery 将参照组确定为延迟支付发票的客户百分比最高的邮政编码。该值被认为具有 100% 的不良率。Einstein Discovery 根据参考值计算每个邮政编码延迟付款的可能性。例如,假设参考值是邮政编码 A 中 75% 的客户延迟支付发票。在邮政编码 B 中,45% 的客户延迟支付。要计算邮政编码 B 的不良率,请用 45 除以 75。比率为 60%。
除了参照组之外,差别性影响图还突出显示了低于 80% 阈值的邮政编码。与参照组相比,这些地区的客户与延迟付款相关的可能性要小得多。邮政编码可能会造成差别性影响;将它包含在我们的模型中可能会引入偏见。

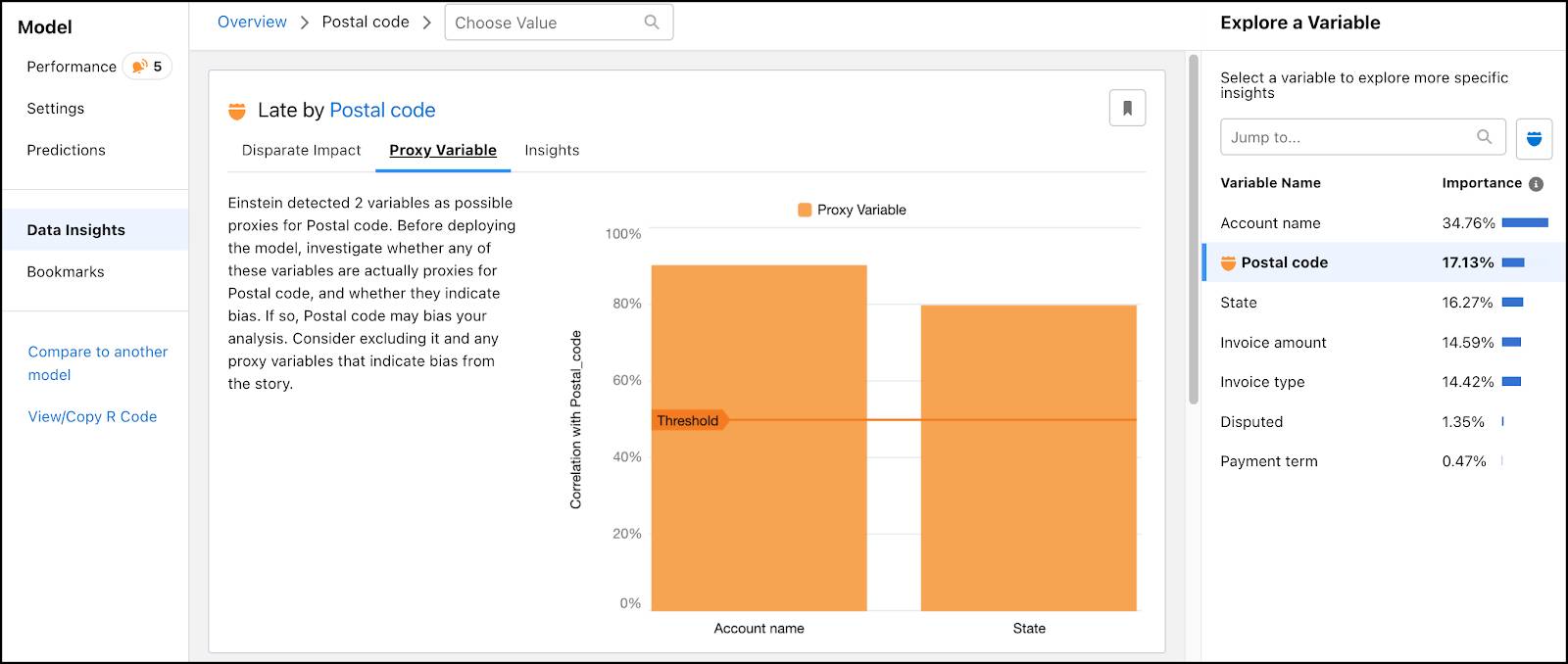
探索代理变量
代理值是数据集中与敏感变量相关的其他属性。在这里,“帐户名”是邮政编码的 90% 代理。从如此强的相关性中,我们可以推断,Einstein Discovery 确定的许多最有可能延迟付款的邮政编码是由于邮政编码与一个帐户名相关联。
用模型卡澄清预测
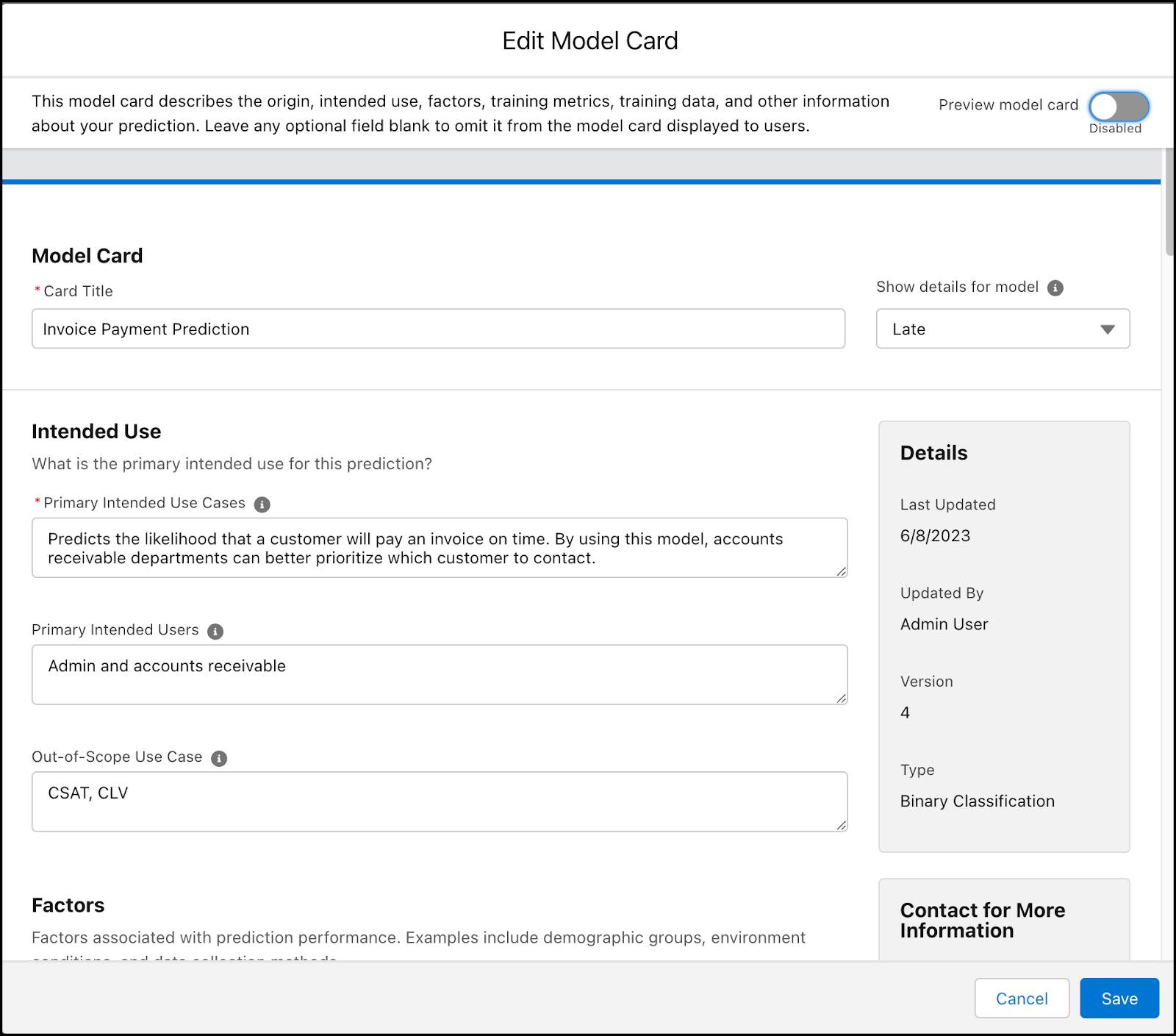
由于可用于进行预测的选项太多,因此很难区分哪种模型最适合特定环境。模型卡是一份简短的文档,其中包含有关预期用途、设计假设、受众、限制和与其训练数据相关的统计数据的重要详细信息。公开透明允许用户为他们想要做出的预测选择最合适的模型。
Einstein Discovery 会生成一个模型卡,作为模型的文档。该卡片是一个模板,您可以填写以突出显示构建模型时做出的决定,例如您删除的变量及其原因。该模板还包括与用于训练模型的数据相关的模型统计信息,例如模型质量评级、训练数据集中结果值的分布以及与结果的变量相关性。
要创建模型卡,请从模型管理器查看预测并单击 + Model Card(+ 模型卡)。

在模板中,填写要向用户显示的任何字段,例如“主要预期用例”和“道德考量”,然后保存您的工作。如果预测有多个模型,请从列表中选择一个模型以显示其详细信息。
模型卡的“道德考量”部分中会自动包含差别性影响图。还有一个空白处可用来分享任何其他信息。
要预览模型卡,请选择 Preview model card(预览模型卡)。仅显示已填写的字段——省略空白字段。

完成卡片后,单击 Save(保存)。要查看您的模型卡,请从模型管理器中选择您的模型。从 + Edit Model Card(+编辑模型卡)中选择 View Model Card(查看模型卡)。
这就是最终的模型卡。

结论
Einstein Discovery 中的模型可帮助您全面了解您的数据,其内容既包括业务结果也包括影响这些结果的政治和社会结构。借助敏感变量、差别性影响、代理变量和模型卡,Einstein Discovery 让您可以采取主动的方法来消除偏见,以构建既准确又公平的模型。
资源