评估模型
学习目标
完成本单元后,您将能够:
- 解释什么是模型以及它的来源。
- 描述您为什么使用模型度量来了解模型质量。
模型、变量和观察
复习一下您在本模块前面所学的内容,模型是复杂的自定义数学结构,基于对过去结果的综合统计性理解。Einstein Discovery 根据数据生成(训练)模型。Einstein 使用该模型来产生诊断性和比较性见解。将模型部署到生产中后,您可以用它来为您的实时数据得出预测和改进(稍后会详细介绍!) 。
变量
让我们来进一步探索模型。首先,模型是按变量来整理数据的,了解这一点会很有帮助。变量是一类数据。它类似于 CRM Analytics 数据集中的列或 Salesforce 对象中的字段。一个模型有两种变量:输入(预测变量)和输出(预测)。
观察
预测在观察级别发生。观察是一组结构化的数据。它类似于 CRM Analytics 数据集中的已填充行或 Salesforce 对象中的记录。
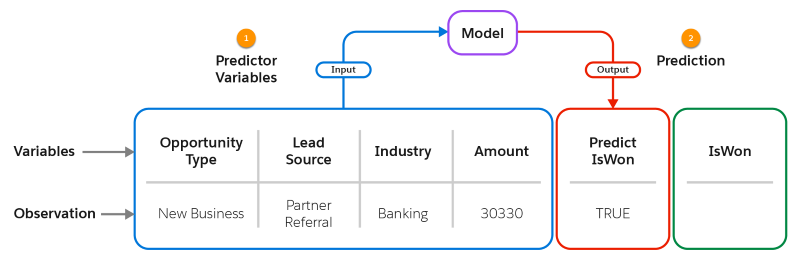
对于每个观察,模型接受一组预测变量作为输入 (1),并返回对应的预测 (2) 作为输出。如果需要,该模型也可以返回热门预测因素和改进。在该图中,实际结果 (IsWon) 尚不清楚。
模型无处不在
模型不是 Einstein Discovery 或 Salesforce 独有的。事实上,预测模型在世界各地广泛使用,跨不同行业、组织、学科并涉及日常生活的许多方面。数据科学家和其他专家运用他们强大的聪明才智,设计和构建可以生成非常准确和有用的预测的高质量模型。
然而,许多组织所面临的一个共同挑战是,精心设计的模型建成后,很难实施到生产环境中,也难以与应该从模型中受益的运营无缝集成。借助 Einstein Discovery,您现在可以快速实施模型:构建它们,将它们部署到生产中,随即开始使用实时数据获得预测并做出更好的业务决策。您甚至可以实施上传到 Einstein Discovery 的外部构建模型。
什么是好的模型?
当然了,如果您要根据模型产生的预测做出业务决策,那么您就需要一个非常擅长预测结果的模型。最低限度,您需要一个在预测结果方面比在没有模型的情况下做得更好的模型,而没有模型时只能随机猜测,导致决策缺乏数据!
那么,好的模型具备什么特点呢?从广义上讲,一个好的模型通过生成足够准确的预测来支持您的结果改进目标,从而满足您的解决方案要求。简而言之,您想知道模型的预测结果与实际结果的匹配程度如何。
为了帮助您确定模型的表现,Einstein Discovery 提供了模型度量来可视化模型性能的常见度量指标。(数据科学家认为这些是拟合统计数据,可以量化模型的预测与真实数据的拟合程度。) 请记住,模型是对现实世界的抽象近似,因此所有模型都不可避免地在某种程度上存在不准确。事实上,一个“完美”的模型应该引起您的怀疑,而不是希冀(稍后会详细介绍)。
在考虑模型时,思考一下统计学家 George Box 经常被引用的一句话会很有帮助:“所有模型都是错误的,但有些模型是有用的。”
因此,让我们来了解一下您的模型可以有多大用处。
探索模型性能
在 Einstein Discovery 中,模型性能显示模型的质量度量和相关详细信息。模型性能可帮助您评估模型预测结果的能力。模型性能度量是使用用于训练模型的 CRM Analytics 数据集中的数据进行计算。对于数据集中具有已知(观察到的或实际的)结果的每个观察,Einstein Discovery 都会计算预测,然后将预测结果与实际结果进行比较以确定其准确性。
重要提示:Einstein Discovery 提供了许多不同的度量指标来描述为您构建的模型,事实上,由于实在太多,本模块无法逐一涵盖。但别担心,您不需要知道所有、甚至大部分度量指标。我们在这里只介绍最重要的一部分。
通过提供一套全面的度量指标,Einstein Discovery 使您的模型完全透明,并可以通过多种方式从不同的角度评估性能。这样,您就可以使用对您的解决方案最有意义的度量指标来评估模型质量,包括本单元未涵盖的指标。
Einstein Discovery 还可以帮助您解读这些指标,而无需了解所有的细微差别以及计算它们所涉及的数学。如果您想了解有关本单元未涵盖的特定指标或屏幕的更多信息,请单击信息气泡  或了解详细信息
或了解详细信息  。
。
模型性能概览
打开模型后,您首先会看到模型性能页。用此页评估模型的质量。

备注:数字和二元分类用例具有不同的模型度量。在本模块中,我们侧重于让模型度量最大化 isWon,这是一种二元分类用例。
左侧面板 (1) 显示:
- 导航到模型部分
- 数据见解和书签
- 其他操作的链接
“部署的路径”面板 (2) 显示:
-
审核模型准确度:对于二元分类解决方案,ROC 曲线下与坐标轴围成的面积 (AUC) 统计数据通常是数据科学家首先评估模型质量的位置。我们的目标是使 AUC 大于 0.5(随机机会)且小于 1.0(完美预测,通常表明存在数据泄漏问题)。我们模型的 AUC 值为 0.8183,处于良好范围内。
备注:数值模型的一个可比较指标是 R^2,它衡量回归模型解释结果变化的能力。R^2 的范围从零(随机机会)到一(完美模型)。一般来说,R^2 越高,模型预测结果的能力就越好。
-
设置阈值:对于二元分类模型,阈值是根据预测分数(0 到 1 之间的数字)确定预测是真还是假的值。在我们的示例中,如果预测分数为 0.4954 或更高,则预测结果为 TRUE。深入了解阈值不在本模块范围内。可以这么说,根据您的解决方案要求,您可以调整模型以支持一种结果而不是另一种结果。
-
评估部署准备情况:Einstein Discovery 执行模型质量检查并在此处显示检测到的问题。在您的示例中,没有数据警报,因为您已经在上一个单元中解决了它们。
“训练数据和模型”面板 (3) 显示:
-
结果变量的分布:显示训练数据中有多少 TRUE 和 FALSE 观察值(实际结果)。
-
热门预测因素:显示与结果相关性最高的预测变量。在我们的示例数据中,“业务机会类型”的相关性最高,其次是“行业”。
预测检查
单击预测检查选项卡。
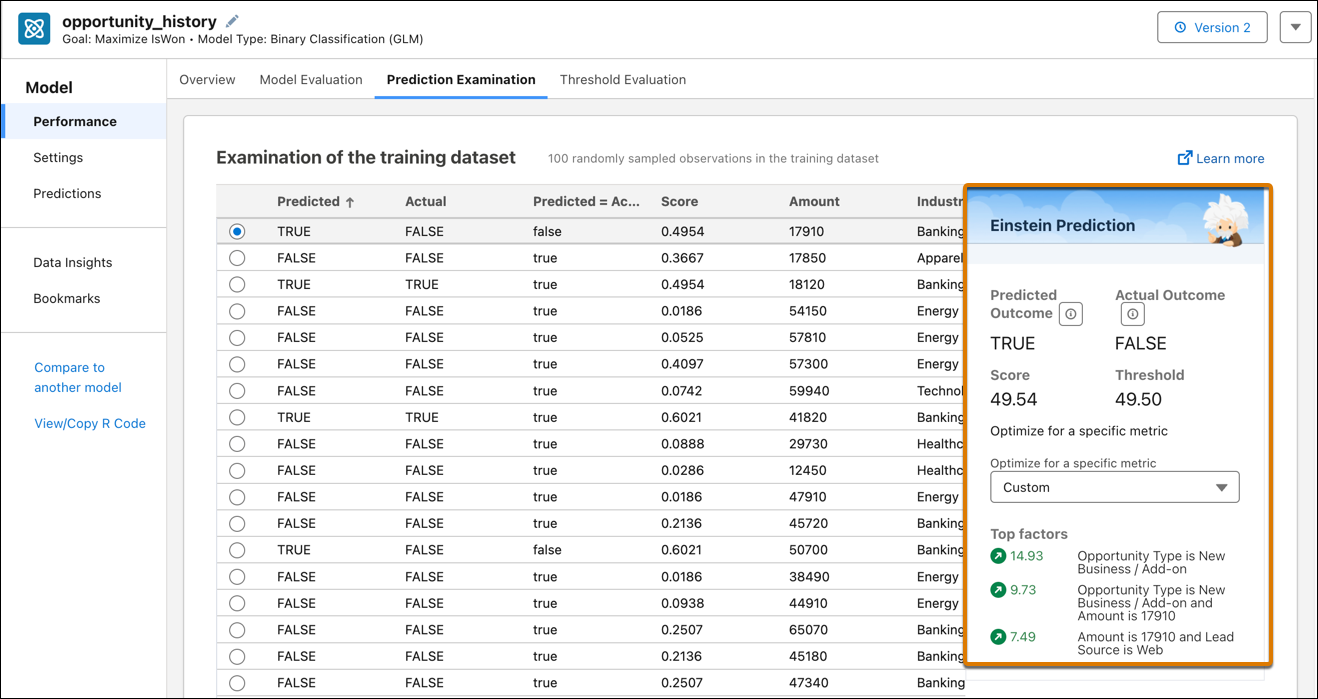
对于训练数据中的选定行,右侧的 Einstein 预测面板将预测结果与实际结果以及对预测结果有贡献的主要因素进行比较。单击任意行以更新此面板。
这个屏幕就像一个路试:它提供了模型在部署后如何预测结果的有用预览。AUC 提供了对模型的合计评测,但此屏幕可让您以交互方式逐层展开和分析模型的预测。
备注:Einstein Discovery 对数据集中的数据进行随机抽样,因此您的屏幕上的数据将与此屏幕截图不同。
探索预测和改进
我们来利用 Einstein Discovery 的力量预测未来。在本节中,通过选择一个场景,让 Einstein 来计算统计上未来可能出现的结果,并给出改进结果的建议。
注意:本单元介绍如何使用您的模型来探索假设预测和改进。稍后,您将学习如何将模型部署到 Salesforce 中,以获得对当前记录的预测和改进。
在左侧导航面板中,单击 Predictions(预测)。

右侧的面板是您选择模型输入的地方。

在“选择要预测的组”下,为“业务机会类型”选择 New Business / Add On(新业务/附加业务),为行业选择 Banking(银行业)(1)。选择“潜在客户来源”(2) 旁边的 Actionable(可操作)按钮。
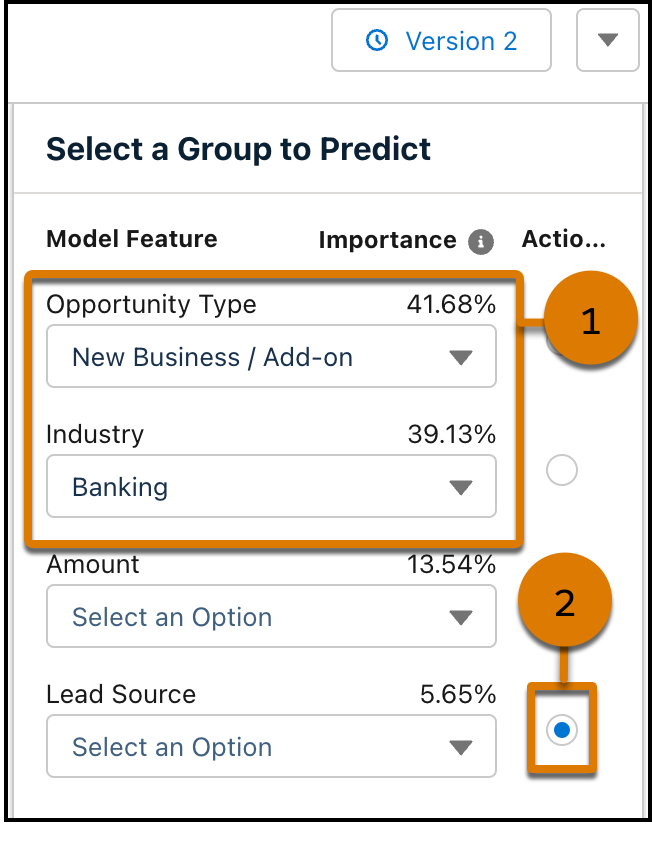
在主页面中您会看到这些面板(可能需要向下滚动才能看到所有内容)。
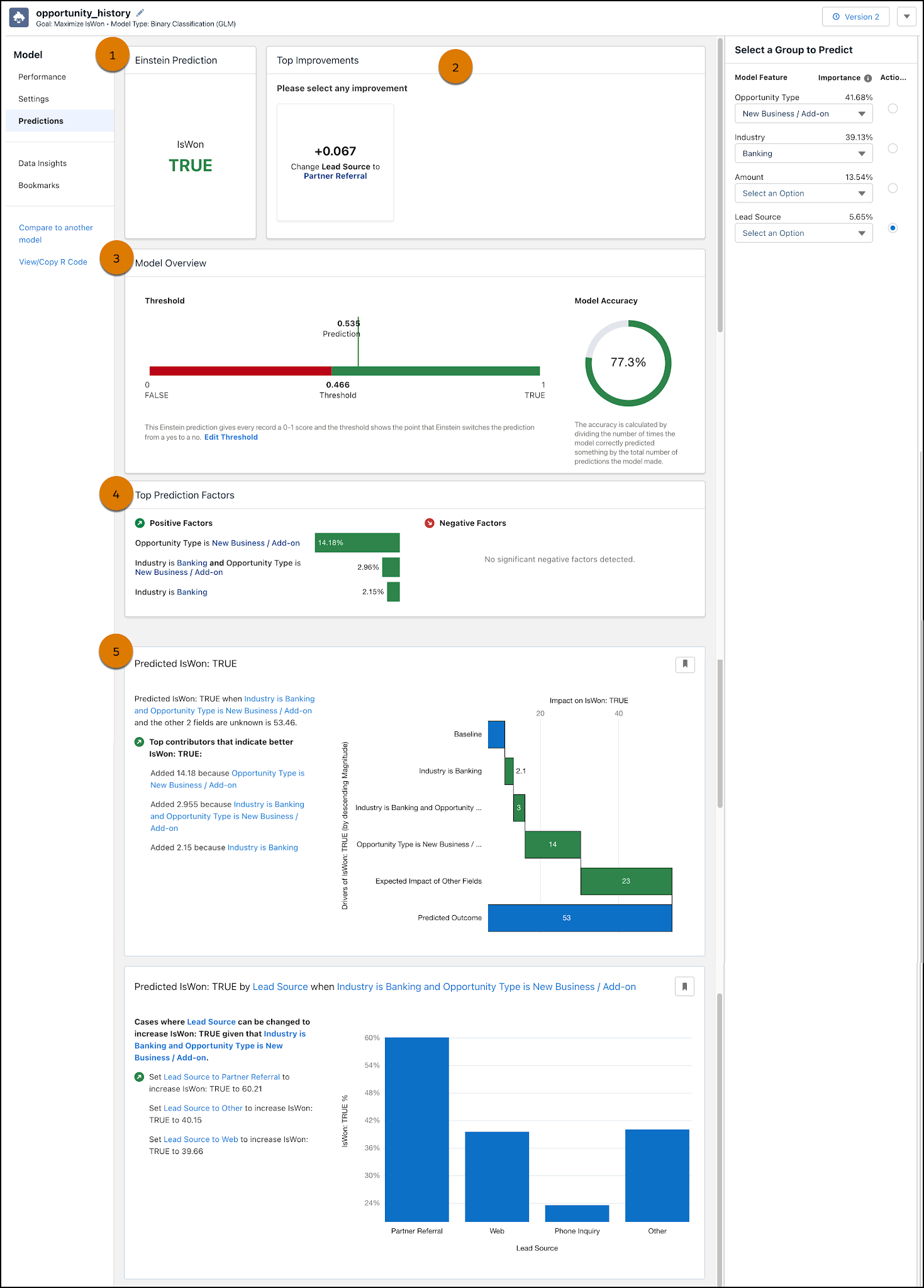
-
Einstein 预测 (1) 显示您的选择的预测分数。在此示例中,预测结果为 IsWon: True。
-
主要改进 (2) 显示您可以采取的建议操作,以改善预测结果。在此示例中,将业务机会的潜在客户来源改为“客户推荐”将预测结果提高了 0.067。
-
模型概览 (3) 显示模型的质量度量。
-
热门预测因素 (4) 显示与预测结果最密切相关的(有利和不利)解释性变量。在我们的示例中,“业务机会类型”为“新业务/附加业务”将预测结果提高了 14.18%。
-
见解 (5) 显示与您的选择相关的其他见解。
接下来做什么?
您已经评估了模型,我们来了解一下数据见解。
资源