创建模型
学习目标
完成本单元后,您将能够:
- 说明 Einstein Discovery 模型是什么,为什么应该使用这一模型。
- 介绍 Einstein Discovery 模型中的关键要素。
- 在 Einstein Discovery 中配置和创建一个模型。
什么是模型?
模型是一个复杂的自定义公式,基于对过去结果的综合统计理解,用于预测未来结果。Einstein Discovery 模型是性能指标、设置、预测和数据见解的总合。Einstein Discovery 会根据您想要改进的结果(模型的目标)、为此目的收集的数据(在 CRM Analytics 数据集中)以及告诉 Einstein Discovery 如何进行分析和传达其结果的其他设置,引导您完成创建模型的步骤。
创建模型
这里介绍了如何使用您在上一个单元中准备的 CRM Analytics 数据集创建预测模型。
- 如果仍在查看上一单元加载的数据集,请单击 Create Model(创建模型),并转到步骤 4。如果没有,在 Analytics Studio 的主页上,单击 Create(创建)并选择 Model(模型)。

- 在 New Model(新建模型)屏幕中,单击 Create from Dataset(创建自数据集)并单击 Continue(继续)。

- 选择您在上一个单元中创建的 opportunity_history 数据集,然后单击 Next(下一步)。

- 在“创建模型”屏幕中,指定您的目标。目标定义了您要分析的结果并训练模型进行预测。指定是否要将结果输出最大化或最小化。
在本模块中,目标是最大化业务机会的成功率 为 I Want to Predict(我要预测)选择 IsWon,在 Maximize(最大化)旁,改为 IsWon:TRUE。接受所有其他默认设置,然后单击下一步。

- 在 Configure Model Columns(配置模型列)屏幕中,接受默认设置(Automated(自动))并单击 Create Model(创建模型)。

Einstein 开始使用统计分析、机器学习算法和人工智能来构建预测模型。

完成后,Einstein 显示模型的性能概览。
调查数据质量警报
在分析和训练期间,Einstein Discovery 会检查您的数据是否存在质量问题,例如重复影响(称为多重共线性数据警报)、潜在偏差或经常缺失的值,或其他数据质量问题。一旦检测到潜在的数据质量问题,Einstein 将通过数据警报通知您。要了解有关数据警报的更多信息,请查看处理质量警报。
在模型性能概览中,查看“评估部署准备情况”并单击查看所有警报按钮,检查有关您的模型的所有警报。

“数据警报”面板会向您显示每个事件,并让您选择采取措施或忽略警报。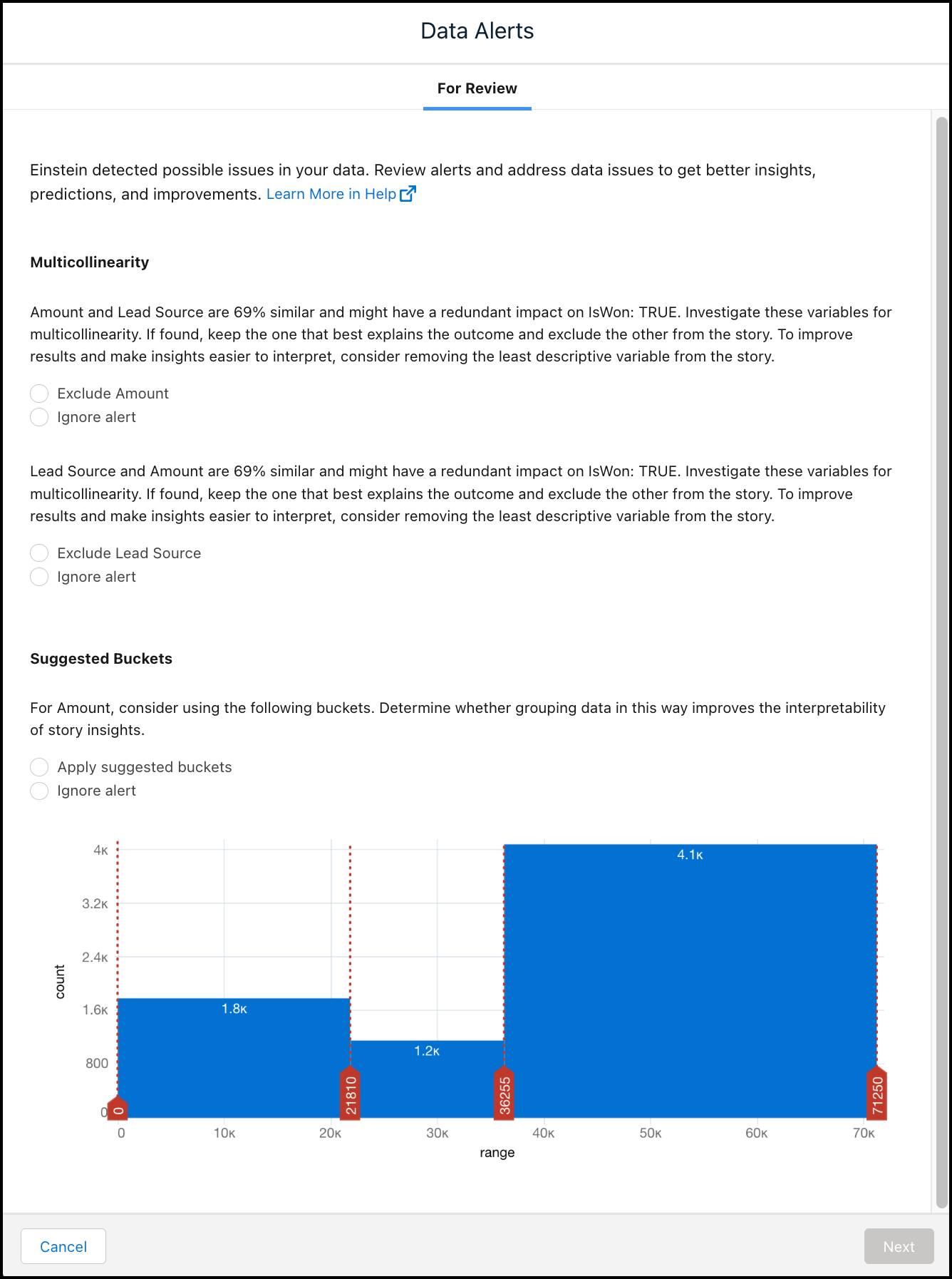
在我们的模型中,Einstein 在数据中检测到多重共线性。问题是两个或多个变量(金额和潜在客户来源)彼此之间高度相关,并且可能对结果产生重复影响。对于此模块,请继续并为“金额”和“潜在客户来源”选择忽略警报。
Einstein 还检测到一个按不同范围(存储桶)对 Amount(金额)值进行分类的业务机会。在 Suggested Buckets(建议存储桶)下,选择 Apply suggested buckets(应用建议的存储桶)。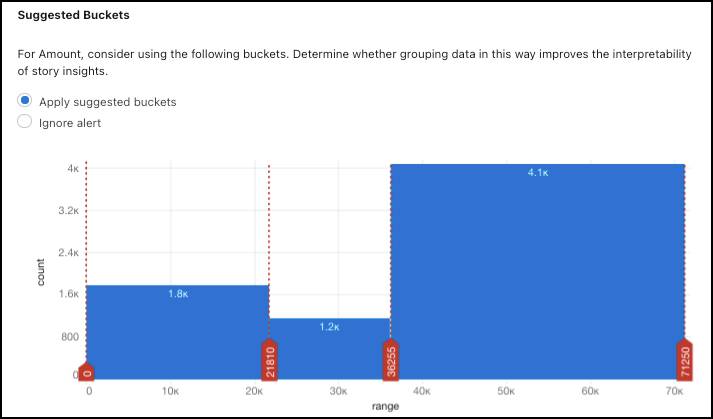
创建模型版本
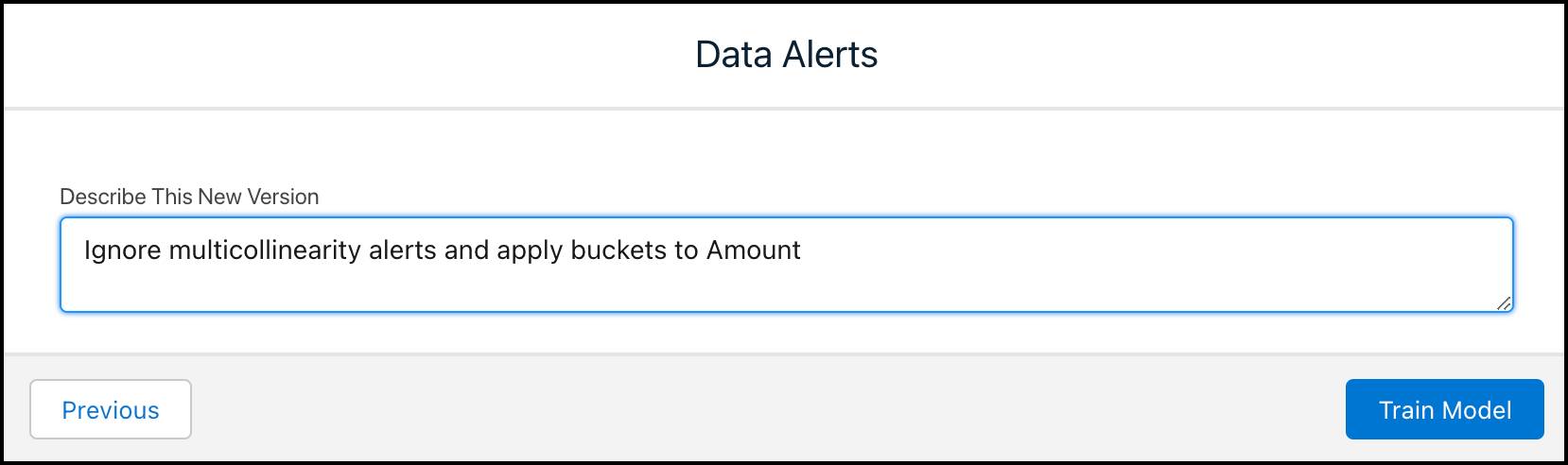
单击下一步。Einstein Discovery 会提示您描述新的模型版本。
每次对模型进行更改时,都需要通过创建新版本来重新运行分析和重新训练模型。对于我们的情况来说,需要新版本是因为 Einstein 需要使用最新设置再次分析您的数据。在本模块的前面部分,您了解到开发 Einstein Discovery 解决方案是一个迭代过程。模型版本可帮助您跟踪每次迭代。
在方框中键入 Ignore multicollinearity alerts and apply buckets to Amount(忽略多重共线性警报并将存储桶应用于金额),然后单击 Train Model(训练模型)。
Einstein 在新版本中重新分析和训练模型。新版本完成后,您将再次看到模型性能概览。在新版本中,您将看到新的版本编号,不再有需要查看的警报。
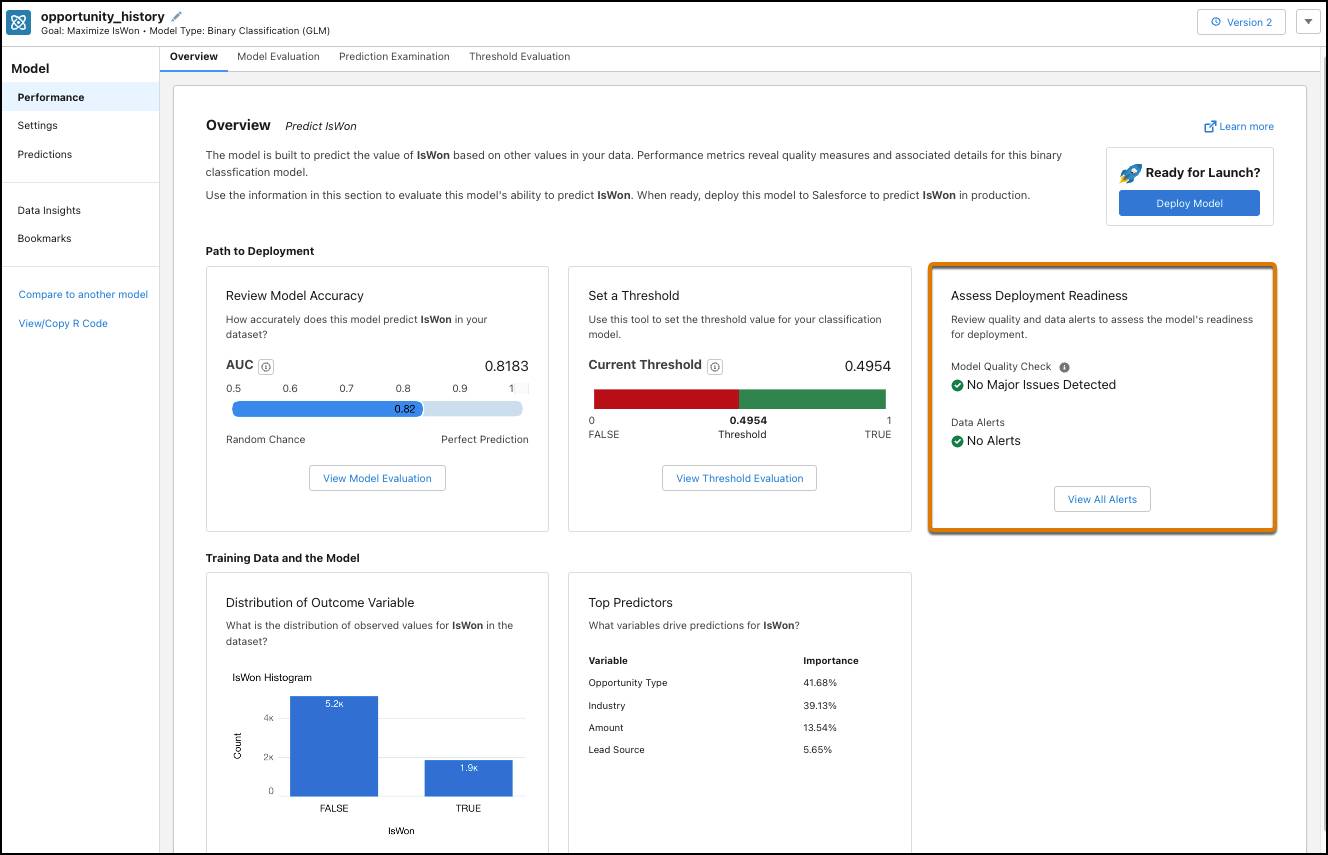
编辑模型设置
要开始自定义模型,单击 Settings(设置)。

现在您可以检查模型设置。
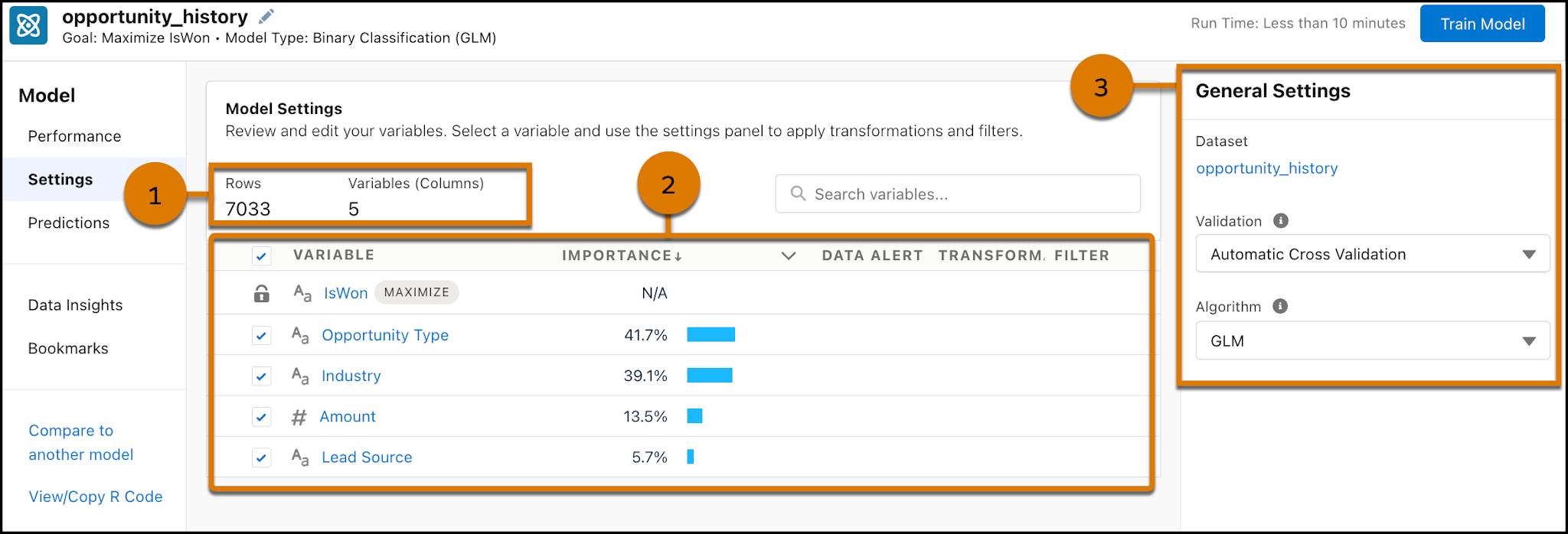
数据集详细信息
您会看到数据集中的行数和列数 (1)。在 Einstein Discovery 中,我们将数据集中的每一行称为一个观察,将每一列称为一个变量。
变量表
变量表 (2) 展示模型中的变量。
- 第一个变量 (IsWon) 是您的结果变量,即您试图改善的业务成果。您的目标是最大化 IsWon。
- 接下来是解释性变量,您浏览这些变量以确定它们是否可以,以及在多大程度上影响您的模型的结果变量。
-
重要性是变量对模型预测结果的相对影响力。重要性表示模型在预测结果时选择使用变量的程度。重要性的级别被量化为百分比。百分比越高,影响越大。重要性是一种考虑变量之间相互作用的高级度量。如果两个变量高度相关并且包含相似的信息,则模型选择更好的变量来使用。
- 使用列下拉列表显示相关性而不是重要性。相关性就是指解释性变量和结果变量之间的统计性关联,或“相互关系”。相关性的强度被量化为百分比。百分比越高,相关性越强。切记相关性不是因果关系。相关性只描述变量之间的关联强度,而不是它们是否从因果上影响彼此。可以将相关性视为衡量该字段本身能够预测结果的程度。
- 如果 Einstein Discovery 检测到数据中可能存在需要引起特别注意的问题,则会出现数据警报。
一般设置
在右侧面板中,一般设置 (3) 显示模型使用的数据集。您还可以查看和更改模型的验证和算法。
编辑变量设置
在变量表中,单击 Industry(行业)。在右侧的面板中,为所选变量配置设置。
- 如果您怀疑变量可能指示偏差,则请选择分析偏差 (1),这将激活 Einstein Discovery 的偏差检测功能。要了解更多信息,请查看 Einstein Discovery 的道德模型发展:快速了解。
- 如果您想在分析过程中转换此变量的值,请选择可用的 Transform(转换) (2) 选项。选项包括模糊匹配、检测情绪,文本群集和替换缺少的值。转换仅更改模型中的数据 - 数据集中的值不变。例如,模糊匹配修复了文本值中的轻微排版差异(如拼写或打字错误),因此模型可以进行更准确的分类和更好的预测。
-
Include Only(仅包括) (3) 显示与变量关联的值,从最常见的值开始。如果您清除某个值旁边的复选框,Einstein 可能会在分析中忽略该值,也可能会将该值合并到“其他”类别中。
-
柱状图 (4) 显示值在数据集中出现的频率。
您还可以用模型做什么?
除了刚刚学习的模型的用途之外,您还可以:
- 查看版本历史记录,转到另一个版本。
- 为见解图加书签。
- 与其他模型比较。
- 查看和复制 R 代码。
- 为模型重命名。
- 更改保存模型的应用。
- 删除模型。
接下来做什么?
在本单元中,您创建了模型,解决了数据警报并创建了新版本的模型。在下一单元中,您将评估模型。
资源