Explore Data Processing Engine
Learning Objectives
After completing this unit, you’ll be able to:
- List the predefined Data Processing Engine templates available for forecasting and their use.
- Describe how the Data Processing Engine transforms data in your org for forecasting.
- Clone a Data Processing Engine template.
- Explore the DPE builder and the different elements in it.
- Compare the two approaches to customizing DPE definitions.
Unbox the Templates
Cindy refreshes her memory on the provided DPE templates. Four DPE templates come with Advanced Account Forecasting, and each one is used at a different time in the forecast lifecycle.
Data Processing Engine Template |
What Does It Do? |
|---|---|
Generate Account Forecast |
Generates an initial forecast for an account based on a forecast set. When you generate forecasts for the first time for a forecast set, use this definition. |
Recalculate Account Forecast |
Calculates the latest forecast values in a period. For Rayler Parts, this definition runs each month. Cindy can also trigger it for ad-hoc calculations, like when new products are introduced. |
Rollover Account Forecast |
Generates forecasts for new periods. At the end of each month, the forecast display rolls over to expire the forecast for the first period, and add another period to the display. |
Regenerate Account Forecast |
Expires the existing forecast records and creates a new forecast. When you edit the forecast set configurations or change the dimensions and period groups, run this definition to generate forecasts based on the updated parameters. |
Transform Your Data Using DPE Templates
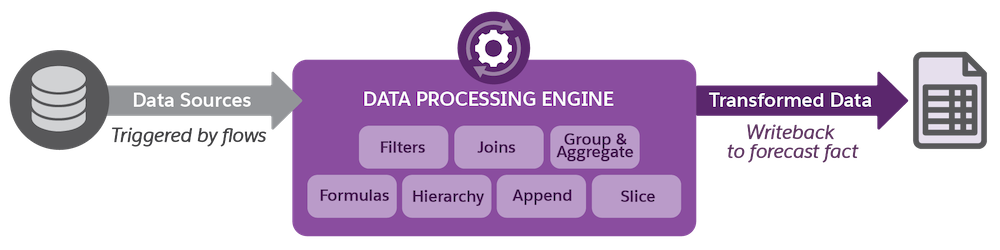
Cindy wants to create definitions that are specific to Rayler Parts’s business requirements, so she clones the DPE templates and customizes the cloned copies. She can then run these definitions with a scheduled flow at regular intervals. The definitions then calculate the forecast values based on the logic specified in the nodes of the definition. The calculated values are written back as new and updated Advanced Account Forecast Fact records. Finally, the forecast set configurations are applied to display the forecast values for each account.
Here’s an example to explain better. Lets say, Cindy defines the forecast frequency and the rollover frequency as monthly in a forecast set. She then creates a flow to schedule a monthly job to run the Recalculate Account Forecast DPE definition. The flow triggers the DPE job and the forecast calculations are created. Let’s look more closely at what happens when a DPE job runs.
The Recalculate Account Forecast DPE job treats all the new data in Orders, Opportunities, Sales Agreements, and other data sources as the input. The job then applies the transformations, such as grouping and aggregating by the dimensions, and finally writes back the data to the Advanced Account Forecast object. The display specifications in the forecast set where the DPE definition is referenced determines what the account manager sees in the forecast. The actual forecast data can be viewed on an Advanced Account Forecast Partner Set record.
Remember that the Advanced Account Forecast Partner Set represents the junction between an advanced account forecast set and an account. It holds the forecast data that’s displayed in the forecast grid. So for example, if Forecast Set X specifies the forecast configurations for accounts 1, 2, and 3, the Partner Set record is a unique combination like X1, X2, and X3.
DPE Template Clones
Cindy clones the Generate Account Forecast template definition and saves the cloned copy. She will use this template to experiment with the customizations that the account managers at Rayler Parts have been requesting for. For more details, see Clone Data Processing Engine Templates.
By cloning the Generate Account Forecast template, Cindy has ensured that she can make updates to the new definition without breaking anything that’s already working. All the nodes with their objects and fields are carried over during cloning, so Cindy doesn’t need to start from scratch.
Take a Tour of the DPE Builder
With the builder open, Cindy reviews what she can do.
- Header (1): You can edit the name, API name, description, and process type for the definition.
- Quick Actions
-
Activate (2): To run a Data Processing Engine definition, you activate it. To edit an activated Data Processing Engine definition, deactivate it first.
-
Save As (3): Make a copy of the Data Processing Engine definition.
-
Save (4): After you define all the nodes, save the definition.
- Left Panel Tabs
-
Nodes (5): Lists all the nodes that you add to your definition.
-
Input Variables (6): Lists all the input variables that you define. Input variables are used in Filter and Formula type nodes.
- Left Panel Actions
-
New Node (7): Create a node and specify its type.
-
New Input Variable: Create an input variable.
-
Search Nodes (8): Search for nodes and variables by their names and descriptions.
- Blank Canvas: After you create a node or an input variable, you can define the details here.

JSON or UI?
A Data Processing Engine definition can be edited in two ways.
- As a JSON file
- By traversing the nodes in a builder
Cindy wants to understand both approaches before deciding which one suits her requirements.
Each DPE definition can be edited as a JSON file. There are two actions available in the builder.
-
 to download an existing definition as a JSON file on your local system.
to download an existing definition as a JSON file on your local system.
-
 to upload the changed JSON file from your local system.
to upload the changed JSON file from your local system.
The JSON-based approach is best suited in the following situations.
- When you have to add the same field to multiple nodes.
- When you have to delete the same field from multiple nodes where the field is referenced.
- When you have to change the alias of a field in multiple nodes where the field is referenced.
To understand the steps involved, see Create or Edit a Data Processing Engine Definition in a JSON File.
A DPE definition can also be edited by traversing the nodes in the builder. At the bottom of each node’s details, a hyperlink helps you navigate to the next node in the reference structure. If a node is referenced in multiple downstream nodes, the hyperlink shows the count and the list of referenced nodes.

In other words, you can quickly find the list of nodes where a particular node is used as a source node. Start with a top-level node, like a Data Source, and then follow the trail of referenced nodes until you reach the last writeback node.
This approach is best suited for the following situations.
- You are unsure about the path of nodes to follow when you’re adding a field and not all nodes need updates.
- The changes are minimal or the change doesn’t affect other nodes.
- You have a written plan and it’s easier to visualize the changes in the builder.
Cindy now knows her way around the Data Processing Engine builder. She is confident about her knowledge regarding how DPE works in Agentforce Manufacturing. In the next unit, follow Cindy as she discovers a few other best practices and guidelines around customization of Data Processing Engine definitions.
Resources