了解身份解析规则集
学习目标
完成本单元后,您将能够:
- 定义规则集。
- 创建匹配规则。
- 使用调整规则。
身份解析规则集
现在您已经审查了数据并了解了数据映射的重要性,让我们讨论一下如何在系统之间匹配数据。规则集使您能够配置特定对象(如个人)的匹配规则和调整规则。系统遵循这些规则将多个数据源关联起来形成一个统一简档。

无论您的帐户中使用何种对象,最好仔细审查数据要求,以确保源数据符合映射要求。在摄取之前修复数据流比在摄取之后更新数据流更容易。让我们首先回顾一下您的匹配规则选项,以便就什么适合您的帐户作出明智的决策。
匹配规则
匹配规则可根据您的业务需求进行自定义。

若要创建匹配规则,首先需要从以下任一对象中选择一个 (1):个人、联系点(电子邮件、App、电话和地址)、设备或当事人标识。然后选择字段 (2)。根据选定的对象选择可用属性。接下来,根据选定的对象和字段类型,选择匹配方法 (3)。让我们了解一下这些匹配方法的选项。
-
精确:根据完全匹配的词进行匹配。没有拼写错误或其他格式。
-
模糊:根据相似的匹配词进行匹配。拼写错误和拼写略有不同都是可行的。该选项仅适用于名字。
-
标准化:根据相同的精确信息进行匹配,不考虑格式。该选项适用于电子邮件、电话和地址。
选定后,您可以将其他条件添加到匹配规则中。您可以基于标准和自定义属性创建匹配规则的不同组合,以满足您的业务需求。确保为匹配规则指定一个描述性名称,如模糊名字和自定义字段 2。请注意,配置的规则越多,需要遵循的映射要求就越多。
调整规则
匹配规则用于将数据关联起来形成一个统一个人简档,而调整规则决定了数据选择的逻辑。例如,如果同一电子邮件地址可从两个数据源获得,则调整规则可让统一简档知道要显示哪一个。让我们了解一下调整规则的选项。
规则 |
描述 |
|---|---|
|
上次更新
|
该规则规定必须选择最近更新的值以包含在统一简档中。值得考虑的是,哪些数据最常被更新 - 是客户服务数据还是 Marketing Engagement 偏好数据? |
|
最频繁
|
该规则规定必须选择最常出现的值以包含在统一简档中。 |
|
源次序
|
此规则使您能够按照从最喜欢到最不喜欢的顺序对数据源进行排序,以确定要包含的值。基本上,它允许您基于对数据源的信任度进行选择。例如,您可以指定系统首先使用 Agentforce Commerce 数据,最后使用 S3 数据。 |
请务必注意,您可以在对象级别和字段级别选择调整规则。
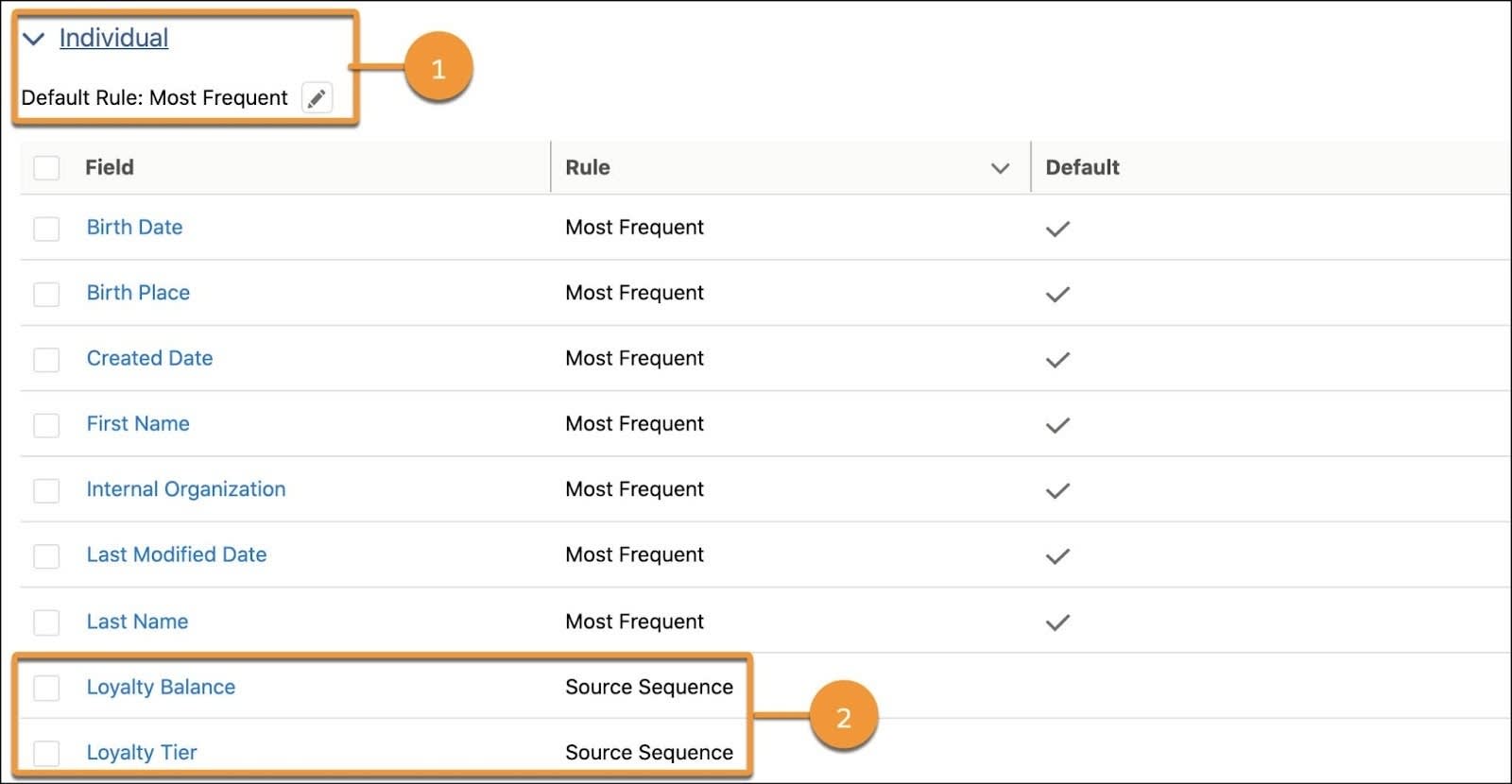
在这个示例中,忠诚度平衡和忠诚度等级使用源顺序规则 (2) 而非默认的最常见规则 (1)。
对于您没有选择用于统一简档的数据,会发生什么?假设您的个人简档具有两个电子邮件地址(就像 Agentforce Commerce 中的 Rachel 的信息)。无论选择显示哪个版本,所有唯一的电子邮件地址仍会存储在每个客户的记录中。因此,您不必担心重要数据会被删除。
下一个:用例
在下一单元中,我们将查看一个用例,并分享使用身份解析规则集的最佳实践。
资源