Seguir a jornada da resposta
Objetivos de aprendizagem
Após concluir esta unidade, você estará apto a:
- Descrever a jornada da resposta.
- Explicar a zero retenção de dados.
- Discutir por que a detecção de linguagem tóxica é importante.

Uma rápida revisão da jornada do prompt
Você já pode ver quantas etapas de cuidado o Salesforce aplica com o Einstein Trust Layer para proteger os dados dos clientes da Jéssica e os dados da empresa. Antes de saber mais, faça uma rápida revisão da jornada do prompt.
- Um modelo de prompt foi extraído automaticamente do recurso Respostas de atendimento para ajudar no caso de atendimento ao cliente da Jéssica.
- Os campos de mesclagem do modelo de prompt foram preenchidos com dados confiáveis e seguros da organização da Jéssica.
- Artigos de conhecimento relevantes e detalhes de outros objetos foram recuperados e incluídos para dar mais contexto ao prompt.
- As informações de identificação pessoal (PII) foram mascaradas.
- Proteções de segurança extras foram aplicadas ao prompt para protegê-lo ainda mais.
- Agora, o prompt está pronto para passar pelo gateway seguro até o LLM externo.
O gateway seguro do LLM
Preenchido com dados relevantes e medidas de proteção em vigor, o prompt está preparado para deixar o Salesforce Trust Boundary, passando pelo gateway seguro do LLM até os LLMs conectados. Nesse caso, o LLM ao qual a organização da Jéssica está conectada é o OpenAI. O OpenAI usa esse prompt para gerar uma resposta relevante e de alta qualidade para Jéssica usar na conversa com seu cliente.
Zero retenção de dados
Se Jessica estivesse usando uma ferramenta LLM destinada a consumidores, como um chatbot de IA generativa, sem uma camada de confiança robusta, o prompt, incluindo todos os dados do cliente, e até mesmo a resposta do LLM, poderiam ser armazenados pelo LLM para treinamento de modelo. Mas, quando o Salesforce age em parceria com um LLM baseado em API externa, nós exigimos um contrato para manter a interação inteira segura; isso se chama zero retenção de dados. Nossa política de zero retenção de dados significa que nenhum dados do cliente, incluindo o texto do prompt e as respostas geradas, ficam armazenados fora do Salesforce.

Veja como funciona. O prompt de Jéssica é enviado para um LLM; lembre-se, esse prompt é uma instrução. O LLM aceita esse prompt e, seguindo as instruções e adotando as proteções, gera uma ou mais respostas.
Normalmente, o OpenAI deseja reter os prompts e as respostas dos prompts por um período de tempo para monitorar abusos. Os LLMs incrivelmente poderosos do OpenAI verificam se algo incomum está acontecendo nos modelos, como os ataques de injeção ao prompt vistos na última unidade. Mas nossa política de zero retenção de dados impede que os parceiros de LLM retenham quaisquer dados da interação. Nós chegamos a um acordo no qual nós fazemos essa moderação.
Não permitimos que o OpenAI armazene nada. Portanto, quando um prompt é enviado ao OpenAI, o modelo esquece o prompt e as respostas assim que a resposta é enviada de volta ao Salesforce. Isso é importante porque permite que o Salesforce lide com seu próprio conteúdo e faça a moderação de abusos. Além disso, usuários como Jéssica não precisam se preocupar com a retenção e o uso dos dados dos clientes pelos provedores de LLM.
A jornada da resposta
Ao apresentarmos Jéssica, mencionamos que ela estava um pouco apreensiva porque as respostas geradas por IA poderiam não corresponder ao seu nível de meticulosidade. Ela realmente não tem certeza do que esperar, mas não precisa se preocupar, porque o Einstein Trust Layer cuida disso. Ele contém diversos recursos que ajudam a manter a conversa personalizada e profissional.

Até agora, vimos o modelo de prompt da conversa de Jéssica com seu cliente ser preenchido com informações relevantes do cliente e contexto útil relacionado ao caso. Agora, o LLM digeriu esses detalhes e entregou uma resposta ao Salesforce Trust Boundary. Mas ainda não está pronto para Jéssica ver. Embora o tom seja amigável e o conteúdo preciso, a resposta ainda precisa ser verificada pelo Trust Layer quanto a resultados não intencionais. A resposta também ainda contém blocos de dados mascarados, e Jéssica acharia isso muito impessoal para compartilhar com seu cliente. O Trust Layer ainda tem mais algumas ações importantes a executar antes de compartilhar a resposta com ela.
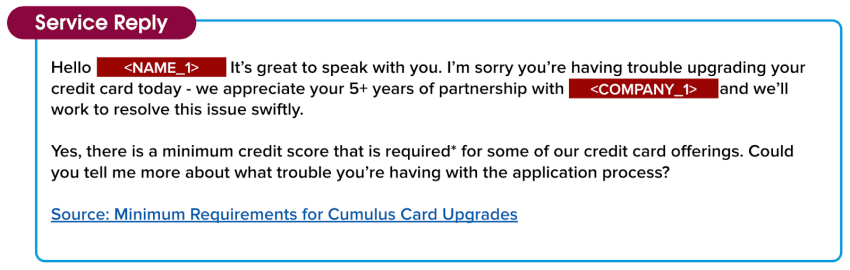
Oi <NAME_1>! É muito bom falar com você. Lamento que você não esteja conseguindo fazer o upgrade do seu cartão de crédito. Agradecemos seus mais de 5 anos de parceria com <COMPANY_1> e faremos tudo para resolver esse problema rapidamente.
Sim, há uma pontuação de crédito mínima exigida* para algumas de nossas ofertas de cartão de crédito. Você pode me contar mais sobre o problema que está tendo com o processo de inscrição?
Fonte: Requisitos mínimos para upgrades de cartões Cumulus
Detecção de linguagem tóxica e desmascaramento de dados
Duas coisas importantes acontecem quando a resposta à conversa de Jéssica retorna do LLM ao Salesforce Trust Boundary. Primeiro, a detecção de linguagem tóxica protege Jéssica e seus clientes de toxicidade. Você não sabe o que é isso? A Camada de confiança usa modelos de aprendizado de máquina para identificar e sinalizar conteúdo tóxico em prompts e respostas, em cinco categorias: violência, sexo, profanação, ódio e integridade física. O índice geral de toxicidade combina as pontuações de todas as categorias detectadas e produz uma pontuação geral que varia de 0 a 1, sendo 1 a mais tóxica. A pontuação da resposta inicial é enviada de volta ao aplicativo que a chamou, nesse caso, o recurso Respostas de atendimento.
Em seguida, antes que a resposta gerada seja compartilhada com a Jéssica, o Trust Layer (Camada de confiança) precisa revelar os dados mascarados sobre os quais falamos anteriormente, para que a resposta seja pessoal e relevante para o cliente da Jéssica. O Trust Layer usa os mesmos dados tokenizados que salvamos quando mascaramos originalmente os dados para desmascará-los. Depois que os dados são desmascarados, a resposta é compartilhada com a Jéssica.
Além disso, observe que há um link da fonte na parte inferior da resposta. A Criação de artigos de conhecimento confere credibilidade às respostas, incluindo links para artigos de fontes úteis e importantes.
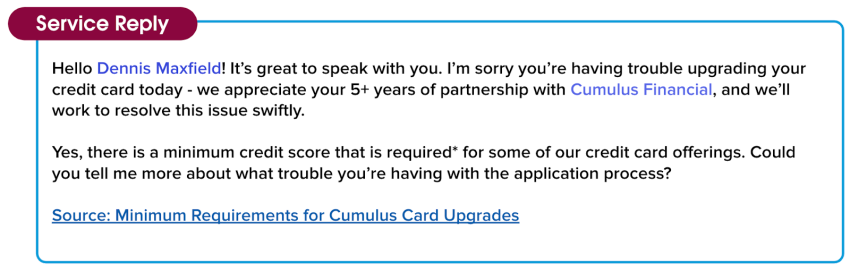
Oi Dennis Maxfield! É muito bom falar com você. Lamento que você não esteja conseguindo fazer o upgrade do seu cartão de crédito. Agradecemos seus mais de 5 anos de parceria com a Cumulus Financial e faremos tudo para resolver esse problema rapidamente.
Sim, há uma pontuação de crédito mínima exigida* para algumas de nossas ofertas de cartão de crédito. Você pode me contar mais sobre o problema que está tendo com o processo de inscrição?
Fonte: Requisitos mínimos para upgrades de cartões Cumulus
Estrutura de feedback
Agora, vendo a resposta pela primeira vez, a Jéssica sorri. Ela está impressionada com a qualidade e o nível de detalhe da resposta que recebeu do LLM. Ela também está satisfeita com o nível de alinhamento com o seu estilo pessoal de tratamento de casos. Conforme Jéssica analisa a resposta antes de enviá-la ao cliente, ela percebe que pode optar por aceitá-la como está, editá-la antes de enviar ou ignorá-la.
Ela também pode dar um feedback qualitativo na forma de polegar para cima ou para baixo e, se a resposta não foi útil, ela pode especificar o motivo. Esse feedback é coletado e, no futuro, pode ser usado com segurança para melhorar a qualidade dos prompts.

Trilha de auditoria
Há uma última parte do Trust Layer para mostrar a você. Lembra-se da política de zero retenção de dados da qual falamos no início desta unidade? Como o Trust Layer lida internamente com pontuação e moderação de linguagem tóxica, monitoramos cada etapa que acontece durante toda a jornada do prompt até a resposta.
Tudo o que aconteceu durante toda essa interação entre a Jéssica e o cliente são metadados com carimbo de data/hora que coletamos em uma trilha de auditoria. Isso inclui o prompt, a resposta original não filtrada, quaisquer pontuações de linguagem tóxica e feedback coletado durante o processo. A trilha de auditoria do Einstein Trust Layer confere um nível de responsabilidade para que Jessica possa ter certeza de que os dados de seus clientes estão protegidos.

Muita coisa aconteceu desde que Jéssica começou a ajudar seu cliente, mas tudo aconteceu num piscar de olhos. Em segundos, sua conversa passou de um prompt chamado por um chat, passando pela segurança de todo o processo do Trust Layer, até uma resposta relevante e profissional que ela pode compartilhar com um cliente.
Ela encerra o caso, sabendo que seu cliente está satisfeito com a resposta e o atendimento que recebeu. E o melhor de tudo, ela está animada em continuar usando o poder do recurso Respostas de atendimento da IA generativa, porque está confiante de que isso a ajudará a encerrar seus casos mais rapidamente e vai agradar seus clientes.
Cada uma das soluções de IA generativa da Salesforce passa pela mesma jornada do Trust Layer. Todas as nossas soluções são seguras. Então, você pode ter certeza de que seus dados e os dados dos seus clientes estão seguros.
Parabéns, você acabou de aprender como funciona o Einstein Trust Layer! Para saber mais sobre o que a Salesforce está fazendo em relação a confiança e IA generativa, ganhe o emblema do Trailhead Criação responsável de inteligência artificial.
Recursos
- Trailhead: Criação responsável de inteligência artificial
- Salesforce Help: Einstein Generative AI & Trust (Ajuda do Salesforce: IA generativa e Trust do Einstein)