Aumento de agentes e prompts com conhecimento de negócios relevante
Objetivos de aprendizagem
Após concluir esta unidade, você estará apto a:
- Explicar por que a geração aumentada por recuperação (RAG) melhora a precisão e a relevância das respostas do LLM em agentes e modelos de prompts.
- Descrever como configurar e usar a RAG em sua organização do Salesforce.
O que é a geração aumentada por recuperação?
A geração aumentada por recuperação (RAG) é uma forma muito utilizada para fundamentar solicitações de prompt a grandes modelos de linguagem (LLMs). A fundamentação adiciona conhecimento específico do domínio ou informações do cliente ao prompt, fornecendo ao LLM contexto para responder com mais precisão a uma pergunta ou tarefa.

Resumindo, a RAG:
-
Recupera informações relevantes de um banco de conhecimento que contém conteúdo estruturado e não estruturado.
-
Aumenta o prompt, combinando essas informações com o prompt original.
- Com o prompt aumentado, o LLM gera uma resposta.
Muitos LLMs são geralmente treinados na Internet com conteúdo estático e disponível publicamente. A RAG adiciona informações específicas do domínio para ajudar os LLMs a fornecer respostas melhores aos seus prompts. Com a RAG, você pode extrair informações úteis de todos os tipos de conteúdo, como respostas de atendimento, casos, artigos do Knowledge, transcrições de conversas, respostas a pedido de propostas (RFP), emails, notas de reuniões, perguntas frequentes (FAQs) e muito mais.
Soluções do Agentforce de início rápido usando o Criador do Agentforce e a biblioteca de dados do Agentforce
O Criador do Agentforce permite que você escolha facilmente artigos do Knowledge ou carregue arquivos para que os agentes possam recuperá-los com apenas alguns cliques. Você pode fazer isso selecionando ou criando uma biblioteca de dados do Agentforce, que é uma biblioteca de conteúdo que o agente usa para responder perguntas. Selecione a fonte da qual a biblioteca de dados extrai informações relevantes: Base de conhecimento do Salesforce, arquivos que você carregou (texto, HTML e PDFs) ou uma pesquisa na Web. Em tempo de execução, seu agente usa essas informações para fundamentar os prompts do LLM e produzir respostas melhores, mais precisas e relevantes do LLM.
Ao adicionar uma biblioteca de dados, você cria automaticamente todos os elementos necessários para uma solução funcional baseada em RAG. Se desejar, você pode personalizar esses elementos para ajustar as soluções de RAG aos seus casos de uso. Falaremos sobre isso mais tarde.
Obter conhecimento de negócios relevante em agentes
Os agentes obtêm conhecimento relevante de uma biblioteca de dados usando a ação padrão Answer Questions with Knowledge (Responder a perguntas com o Knowledge). Esta ação recupera dinamicamente o conteúdo de conhecimento ou do arquivo que você especificou ao criar ou selecionar uma biblioteca.
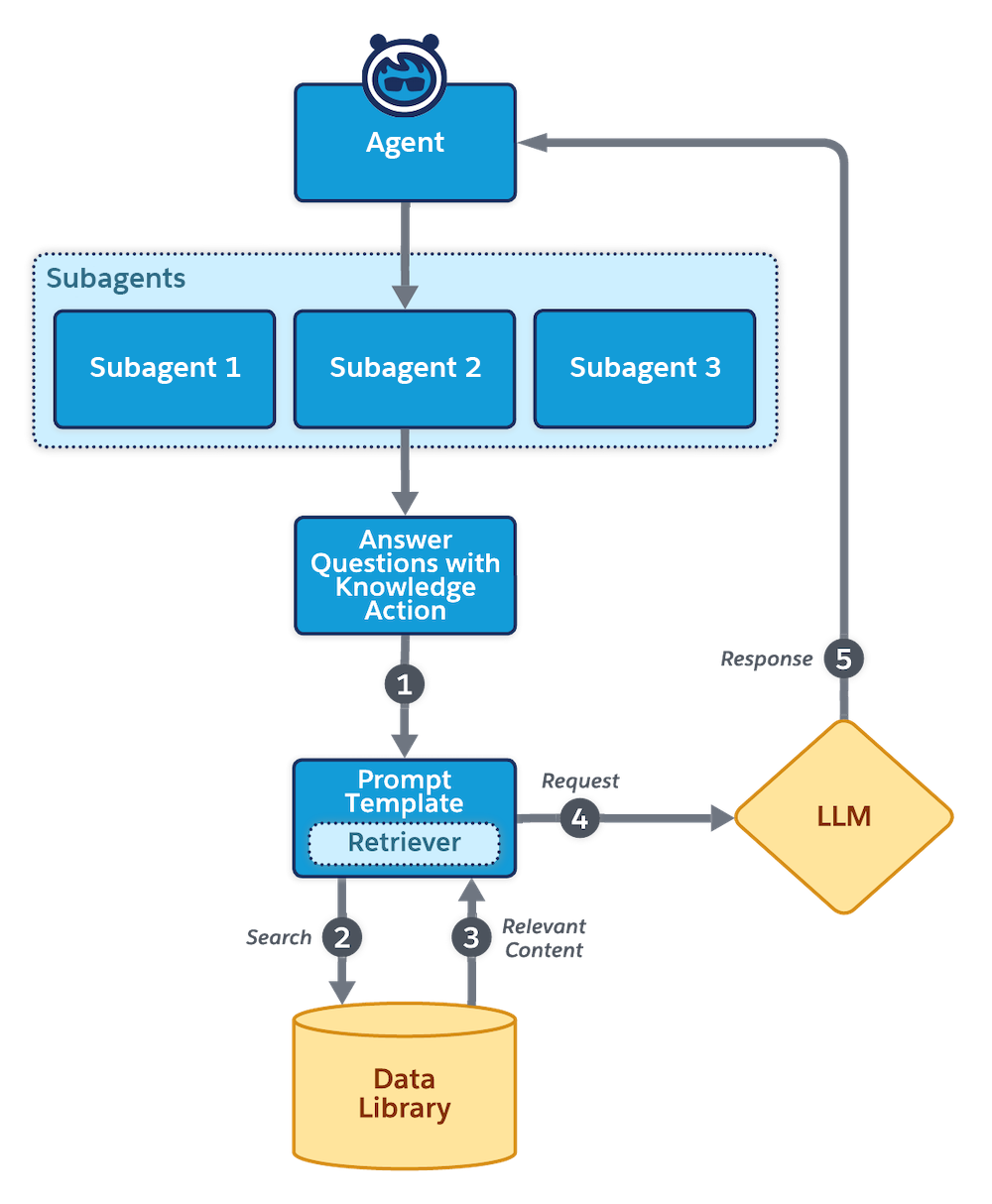
Sempre que a ação Answer Questions with Knowledge (Responder a perguntas com o Knowledge) é executada:
- A ação executa o modelo de prompt associado. O recuperador é invocado com uma consulta dinâmica.
- A consulta pesquisa a biblioteca de dados.
- A consulta recupera o conteúdo relevante.
- O prompt original é preenchido com informações recuperadas da biblioteca de dados e, em seguida, enviado para o LLM.
- A resposta gerada pelo LLM é encaminhada para o agente.
Obter conhecimento de negócios relevante em prompts
Em tempo de execução, os modelos de prompts extraem informações relevantes da sua biblioteca de dados para fundamentar os prompts do LLM, produzindo respostas mais precisas do LLM. Se você estiver usando um modelo de prompt personalizado, no Criador de prompts, basta integrar um recuperador selecionado ao inserir um recurso. Você também pode usar um recuperador personalizado que ajusta as configurações de pesquisa para qualquer prompt específico.
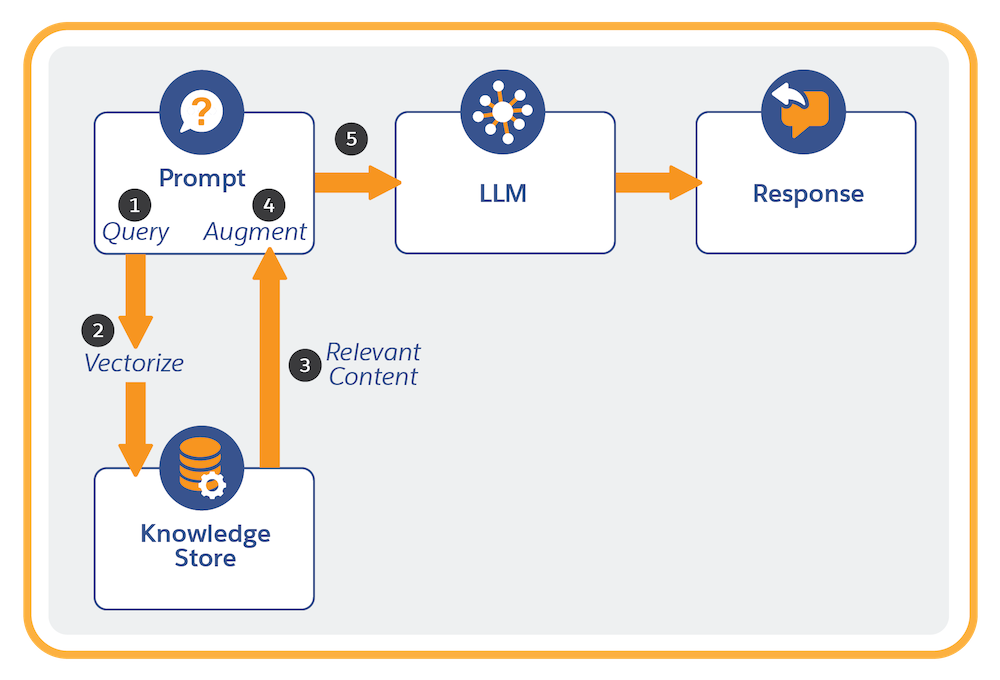
Sempre que um modelo de prompt com um recuperador é executado:
- O recuperador é invocado com uma consulta dinâmica iniciada a partir do modelo de prompt.
- A consulta é vetorizada (convertida em representações numéricas). A vetorização permite que a pesquisa encontre correspondências semânticas no índice de pesquisa (que já está vetorizado).
- A consulta recupera o conteúdo relevante dos dados indexados no índice de pesquisa.
- O prompt original é preenchido com as informações recuperadas do índice de pesquisa.
- O prompt é enviado ao LLM, que gera e retorna a resposta ao prompt.
Personalização avançada no Data 360
Quando você adiciona uma biblioteca de dados, seja no Criador do Agentforce ou em Setup (Configuração), o Salesforce cria automaticamente uma solução baseada em RAG usando as configurações padrão para todos os componentes: armazenamento de dados vetoriais, índice de pesquisa, recuperador, modelo de prompt e ação padrão. Você pode configurar e personalizar esses componentes individualmente.
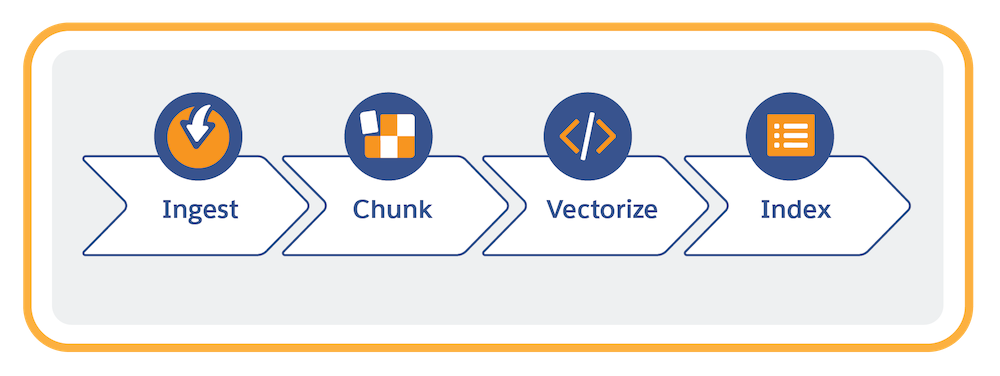
A preparação de dados envolve estas tarefas no Data 360.
- Conectar (ingerir) seus dados não estruturados.
- Criar uma configuração de índice de pesquisa que vetorize e divida o conteúdo em blocos. O Data 360 usa um índice de pesquisa para gerenciar conteúdo estruturado e não estruturado de maneira otimizada para pesquisa. Você tem duas opções de pesquisa: pesquisa de vetores e pesquisa híbrida. A pesquisa híbrida combina pesquisa de vetores + pesquisa por palavra-chave.
- A formação de blocos divide o texto em unidades menores, refletindo passagens do conteúdo original, como frases ou parágrafos.
- A vetorização converte blocos em representações numéricas do texto que capturam semelhanças semânticas.
- A formação de blocos divide o texto em unidades menores, refletindo passagens do conteúdo original, como frases ou parágrafos.
- Armazenar e gerenciar o índice de pesquisa.
Depois de criar um índice de pesquisa, crie um recuperador no recurso Modelos de IA (anteriormente Einstein Studio) para buscar informações relevantes desse índice de pesquisa para um caso de uso específico. Um recuperador é um recurso que você integra em um modelo de prompt para pesquisar e retornar informações relevantes do banco de conhecimento. Para dar suporte a uma variedade de casos de uso, você pode criar recuperadores diferentes que concentram sua pesquisa apenas no subconjunto relevante de informações a adicionar ao prompt. Para uma experiência prática, conclua o módulo RAG avançada com Data 360 e Agentforce.
Ver o RAG em ação
Este vídeo mostra como é fácil aumentar um modelo de prompt usando a RAG.
Conclusão
A biblioteca de dados do Agentforce e a RAG no Data 360 estão integradas na plataforma de IA generativa do Einstein. Incorpore nativamente a funcionalidade RAG em aplicativos prontos para usar, como o Criador do Agentforce e o Criador de prompts. Com a RAG, você pode fundamentar e aprimorar com segurança suas soluções do Agentforce com dados proprietários de um modelo de dados harmonizado.
Recursos
- Ajuda do Salesforce: Dados não estruturados no Data 360
- Ajuda do Salesforce: Data 360 – Formar blocos de dados e vetorizar dados
- Ajuda do Salesforce: Data 360 – Pesquisa de vetores
- Ajuda do Salesforce: Data 360 – Pesquisa híbrida
- Ajuda do Salesforce: Exemplo: RAG agêntica com configuração avançada do Data 360
- Trailhead: Noções básicas da biblioteca de dados do Agentforce
- Trailhead: Dados não estruturados no Data 360
- Trailhead: Tipos de índices de pesquisa no Data 360: início rápido
- Trailhead: Pesquisa híbrida para RAG: início rápido
- Blog do Salesforce: RAG – As três letras mais populares atualmente na IA generativa
- Blog do Salesforce: Agentforce e RAG: Melhores práticas para agentes melhores