Identify and Evaluate Data Bias in AI
Learning Objectives
After completing this unit, you’ll be able to:
- Describe data bias and its importance in artificial intelligence systems.
- Recognize and evaluate data bias in AI applications.
- Recognize common sources of data bias in datasets.

What Is Data Bias?
Data bias plays a significant role in the artificial intelligence systems we use every day. It can lead to biased outputs that reflect human biases and potentially harmful outcomes. Data bias happens when the information you have is not a true reflection of what it should be. Imagine watching a video that withholds important details or gives inaccurate or incomplete facts. This can make you believe something that isn’t entirely true. And this is why recognizing and evaluating data bias is essential for ensuring fair and accurate outcomes in AI.
Data bias causes systematic deviation that can lead to inaccurate or unfair outcomes due to misrepresentation of the underlying population. In AI systems, data bias directly impacts the performance and decision-making capabilities of the models. Given this reach, biased data can lead to unfair outcomes and wrong recommendations with far-reaching consequences.

Different Types of Data Bias
In this section, you explore two major types of data bias—sampling bias and confirmation bias—and examine how they relate to human biases. Understanding these types of bias provides insight into how human biases can inadvertently influence data collection and analysis, leading to potentially unfair AI systems.
Sampling Bias
Sampling bias occurs when the data collection process favors certain groups or excludes other groups in a way that is not truly random or representative of the entire population. Sampling bias can lead to inaccurate AI model outcomes. Data scientists should always consider the entire population when selecting the sample data for AI models.
Take a facial recognition system that is trained to recognize faces for security purposes as an example. Because of sampling bias, an AI facial recognition system might not perform accurately for individuals outside the specific demographic group that had more representation in the training data. It can struggle to recognize the faces of older adults or individuals from different racial backgrounds. This means certain groups are more likely to experience misidentification or higher rates of false positives or negatives.
False positives occur when the system incorrectly identifies someone as a match when they are not. This can result in innocent individuals being mistakenly flagged as potential suspects. The consequences of false positives can be severe, as innocent people can face legal implications. It can lead to a loss of privacy, damage to personal and professional reputations, and a violation of individual rights. On the other hand, false negatives happen when the system fails to recognize a valid match. This means that individuals who should be identified can go undetected by the system. False negatives can result in missed opportunities to solve crime and can compromise public safety.
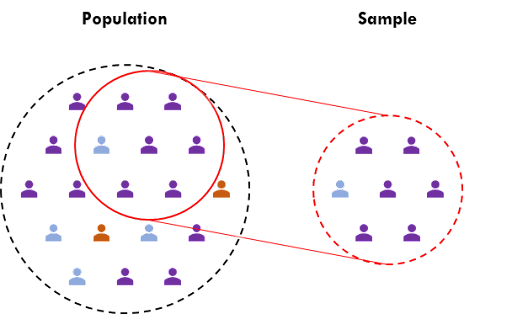
Here’s another example of sampling bias: Let’s say you want to know how many people in a city like ice cream. To find out, you survey people at the local ice cream shop. However, you only ask people who are already inside the shop and not those who are passing by or who don’t visit the shop. This creates a sampling bias because you’re only getting the opinions of a specific group of people who already like ice cream. You’re missing out on the opinions of people who don’t visit the shop or who have different preferences. This can lead to inaccurate conclusions about how much the entire city likes ice cream.
Confirmation Bias
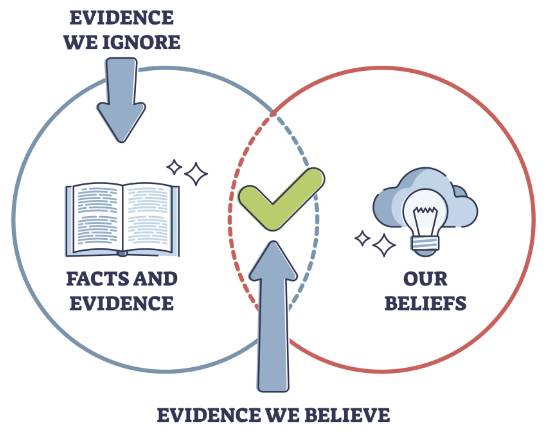
Confirmation bias is when a person’s tendency to process information is done by looking for information that is consistent with their existing beliefs while disregarding or ignoring conflicting evidence. It’s preferring information that supports what you already think without considering alternative viewpoints. It can influence decision-making and overlook alternative perspectives.
Imagine an AI model that’s trained to decide who should get approved for loans. If the data used to train the AI mostly includes loan approvals for specific groups of people, the AI can end up favoring those specific groups. This can lead to biased decisions, where the AI approves loans more often for people who are similar to those who were approved in the past, while overlooking qualified applicants from other groups. This confirmation bias in training data can lead to unfair outcomes by excluding certain individuals.
Latent Bias
Latent bias refers to biases that can happen in the future. We don’t plan errors or accidents, and yet they happen. The inadvertent introduction of bias can affect the quality of the data used to develop artificial intelligence and machine learning applications.
Common Sources of Data Bias
Bias can enter and affect data collection, consumption, and analysis in a variety of ways. Here are some biases to be aware of.
Human Biases
Data collection and analysis processes can be influenced by human biases. This can inadvertently shape data collection methods, questions asked, or interpretations made, leading to biased outcomes.
Data Collection Methods
Biases can be introduced through the methods used to collect data. For example, survey questions can be phrased in a way that elicits a particular response or targets a specific group. Biases can also arise from the selection criteria of respondents, leading to an unrepresentative sample.
Incomplete or Missing Data
Biases can emerge from incomplete or missing data, where certain groups are omitted. This can skew the analysis and limit the validity of the findings.
Systemic Biases
Data bias can stem from underlying systemic biases present in the data generation process. Historical inequalities, unequal power dynamics, or discriminatory practices can contribute to biased data.
Techniques to Identify and Evaluate Data Bias
Now that you know where data bias can come from, let’s look at some effective techniques to identify and evaluate data bias.
|
Tool
|
How to use it?
|
|---|---|
|
Statistical Analysis
|
Using descriptive statistics, such as means, medians, and standard deviations, can reveal potential discrepancies or outliers in the data. |
|
Data Visualization
|
Visualizing data through graphs, charts, or histograms can provide valuable insights into data bias. Visualization techniques, like box plots or scatter plots, can help identify patterns or anomalies that can indicate bias. |
|
Data Exploration
|
Exploring the data by conducting thorough data checks and examinations can help identify potential sources of bias. |
|
External Validation
|
Comparing the dataset with external or independent sources of information can provide an additional means of evaluating bias. |
|
Peer Review and Collaboration
|
Seeking input and feedback from colleagues, experts, or peers can enhance the evaluation of data bias. Collaborative efforts can help identify biases that might be overlooked individually and provide diverse perspectives. |
Resources