Store and Retrieve Data with AWS
Learning Objectives
After completing this unit, you’ll be able to:
- Describe the function of AWS storage services.
- Identify the differences between Amazon S3 Storage Classes.
- Explain Object Lifecycle Management.
- Explain the features of Amazon Elastic Block Store.
- Explain the features of Amazon Elastic File System.

In the previous unit, you learned about AWS Compute services, but what good is compute without data? Cloud storage holds information used by applications.
Imagine you are the technical manager of an enterprise data center. For years, the company has been using a legacy system to back up data, archiving everything from employee records to sales history. You discover that it’s at risk for failure. On top of that, the cost of maintenance and ownership has become hard to justify.
With AWS storage services, you can store the company’s short-term and archival data securely and save on operational costs by eliminating the need to replace outdated servers.
Get to Know Amazon Simple Storage Service (Amazon S3)

Amazon S3 is storage for the Internet.
Amazon S3 stores data as objects, which contain a file and metadata. Objects are uploaded and stored in buckets. Each object can be up to 5 terabytes in size, and you can store an unlimited number of objects in a bucket. Each bucket is located in an AWS Region you specify. Once your objects are stored in a bucket, you can access them from anywhere on the web using HTTP or HTTPS endpoints.
Given that you can access it anywhere on the web, it’s important to consider latency optimization, cost minimization, or regulatory compliance when choosing the AWS Region that hosts your bucket.
Amazon S3 offers a variety of features.
- Control access to both the bucket and the objects—for example: control who can create, delete, and retrieve buckets or objects in buckets.
- Support Secure Sockets Layer (SSL) for data in transit and encryption for data at rest.
- View access logs for the bucket and its objects.
- Configure an Amazon S3 bucket to host a stand-alone static website.
- Use versioning to preserve, retrieve, and restore every version of every object stored in your Amazon S3 bucket.

What Is Amazon S3 Glacier?

Amazon S3 Glacier is a secure, durable, and low-cost cloud storage service for data archiving and long-term backup.
Unlike Amazon S3, data stored in Amazon S3 Glacier has an extended retrieval time ranging from minutes to hours. Retrieving data from Amazon S3 Glacier has a small cost per GB and per request.
Amazon S3 Glacier offers three options for retrieving data with varying access times and cost.
S3 Glacier Instant Retrieval: The fastest and most expensive option, with data typically available within milliseconds. It has a minimum storage duration of 90 days and is recommended for data that needs to be accessed quarterly. This storage class is ideal for performance-sensitive use cases such as image hosting, file-sharing applications, and storing medical records for access during appointments.
S3 Glacier Flexible Retrieval: Objects in this storage class are archived and can be available within minutes to 12 hours. This class has a minimum storage duration of 90 days. It’s recommended for data that needs to be accessed semi-annually. Some common use cases include backup and disaster recovery. With S3 Glacier Flexible Retrieval, there are three retrieval tiers: Expedited (1 to 5 minutes), Standard (3 to 5 hours), and Bulk (5 to 12 hours).
S3 Glacier Deep Archive: This storage class provides the most cost-effective option for retrieving objects, but with the slowest access time. With S3 Glacier Deep Archive, objects are available within 12 to 48 hours. This class is recommended for accessing data annually with the minimum storage duration of 180 days.
S3 Glacier Deep Archive has two retrieval tiers: Standard (9 to 12 hours) and Bulk (within 48 hours). They are ideal for retaining data sets for multiple years to meet compliance requirements and can also be used for backup or disaster recovery.
Use cases include:
- Media asset workflows
- Healthcare information archiving
- Regulatory and compliance archiving
- Scientific data storage
- Digital preservation
- Magnetic tape replacement
Understand Object Lifecycle Management and Amazon S3 Storage Classes
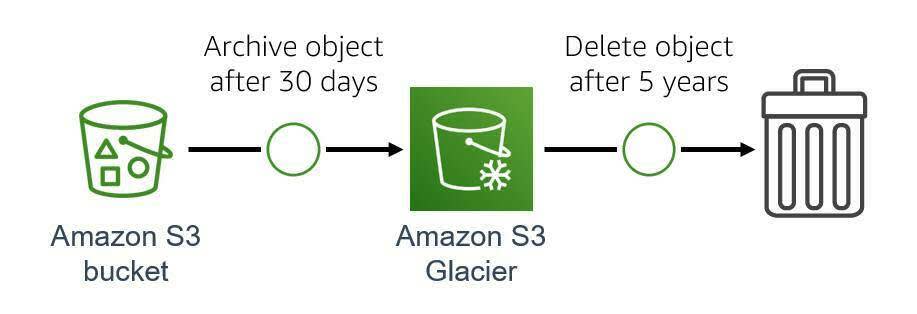
With lifecycle configuration rules, you can tell Amazon S3 to automatically transition objects to less expensive storage classes, archive, or delete them after a set period of time. For example, you can set an Amazon S3 bucket to archive objects to Amazon S3 Glacier after 30 days, and then delete them after 5 years.
Amazon S3 offers a range of storage classes designed for different use cases. Storage classes can be configured at the object level, and a single bucket can contain objects stored across S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and S3 One Zone-IA. More on these classes later. Before that, let’s discuss some terms.
Durability is the chance that you will be able to retrieve an object from storage. It’s important to note that all classes are designed for high durability.
All storage classes are designed for durability of 99.999999999% for objects across multiple availability zones (except Amazon S3 One Zone-Infrequent Access, which is in a single availability zone). This corresponds to an average annual expected loss of 0.000000001% of objects. For example, if you store 10,000,000 objects in Amazon S3, you can on average expect to incur a loss of a single object once every 10,000 years.
In addition, Amazon S3 Standard, S3 Standard-IA, and S3 Glacier are all designed to sustain data in the event of an entire S3 Availability Zone loss.
Availability describes the percentage of “uptime” when it is possible to retrieve an object at the moment you attempt to retrieve it.
S3 Storage Class |
Description |
|---|---|
Amazon S3 Standard (S3 Standard) |
|
Amazon S3 Standard-Infrequent Access (S3 Standard-IA) |
|
Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering) |
|
Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA) |
|
Amazon S3 Express One Zone |
|
Amazon S3 Glacier Instant Retrieval |
|
Amazon S3 Glacier Flexible Retrieval |
|
Amazon S3 Glacier Deep Archive |
|
Get Persistent Block Storage with Amazon Elastic Block Store (Amazon EBS)

Amazon EBS allows you to create persistent block storage volumes and attach them to Amazon EC2 instances. Without storage attached, EC2 instances use ephemeral storage that only lasts until the instance stops, terminates, or the underlying disk drive fails.
Each Amazon EBS volume is automatically replicated within its Availability Zone to protect you from component failure, offering high availability and durability. The Elastic Volumes feature enables you to increase or decrease capacity and change the type of an existing volume with no downtime or performance impact.
Different drive types are available, depending upon your specific needs.
Solid State Drives (SSD)
- Provisioned IOPS SSD (io1, io2, io2 Block Express) volumes
- General Purpose SSD (gp2, gp3) volumes
Hard Disk Drives (HDD)
- Throughput Optimized HDD (st1) volumes
- Cold HDD (sc1) volumes
Store Files with Amazon Elastic File System (Amazon EFS)

Amazon EFS provides a simple, scalable, fully managed, elastic file system. It automatically scales as you add or remove files, so you don’t need to worry about provisioning capacity to accommodate growth.
Amazon EFS makes it easy to migrate existing enterprise applications to the AWS Cloud. Use Amazon EFS for analytics, web serving and content management, application development and testing, media and entertainment workflows, database backups, and container storage.
Resources
- External Site: Amazon S3
- External Site: Hosting a Static Website on Amazon S3
- External Site: Amazon S3 Glacier & S3 Glacier Deep Archive
- External Site: Amazon S3 Storage Classes
- External Site: Amazon Elastic Block Store
- External Site: Amazon Elastic File System