Conhecer os conceitos básicos de bancos de dados
Objetivos de aprendizagem
Após concluir esta unidade, você estará apto a:
- Identificar cinco marcos na história dos bancos de dados.
- Diferenciar os bancos de dados relacionais dos não relacionais.
- Definir “big data”.
História dos bancos de dados
“Está na nuvem”. Isso é algo que ouvimos o tempo todo. É claro que as imagens de névoa e algodão doce que vêm à mente não fazem sentido, já que a nuvem é apenas um data center físico cheio de servidores. A Salesforce tem vários deles em todo o mundo. Mas como todos esses dados são organizados e acessados? Bem, depende do banco de dados. Esta unidade é um curso rápido sobre os conceitos-chave do banco de dados.
Linha de tempo
Nossa história começa nos anos 60, na época em que um computador ocupava uma sala inteira.
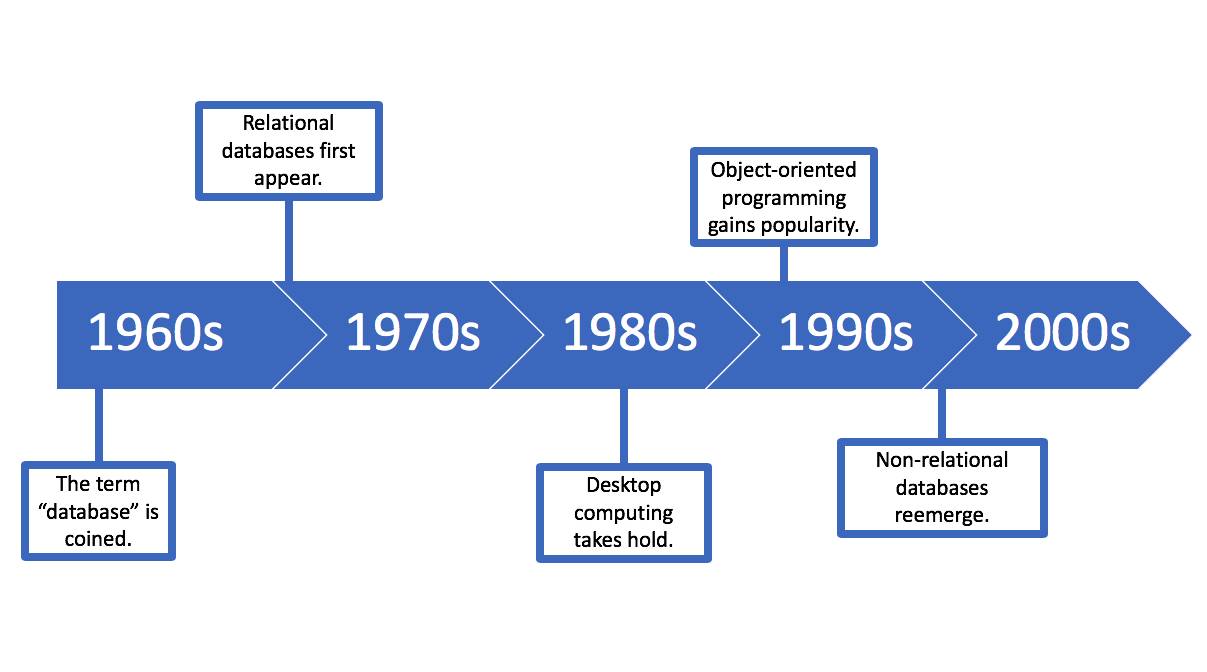
Década |
Marcos |
|---|---|
Anos 60 |
O termo “banco de dados” apareceu no início da década de 60, quando os discos substituíram o armazenamento baseado em fitas. Os primeiros bancos de dados eram não relacionais, o que significa que eles eram apenas listas vinculadas de registros em formato livre. Isso mudou ao longo da década. |
Anos 70 |
Nos anos 70, os bancos de dados relacionais apareceram e acabaram se tornando a norma. Diferentemente dos bancos de dados anteriores, eles ofereciam tabelas normalizadas, relacionadas e pesquisáveis. |
Anos 80 |
O computador pessoal tornou-se amplamente disponível na década de 80, além dos softwares comerciais fáceis de usar que interagiam com os bancos de dados subjacentes. |
Anos 90 |
Nos anos 90, a programação voltada para objetos (OOP) possibilitou a organização dos dados por classes e atributos em vez de apenas por tabelas e campos. |
Anos 2000 |
Os bancos de dados não relacionais ensaiaram uma volta nos anos 2000, na forma de bancos de dados NoSQL (not only SQL). Eles são simples e bastante dimensionáveis, ou seja, atendem às demandas de big data e aplicativos web em tempo real. |
Agora que acabamos a aula de história, vamos ver melhor duas grandes classificações de bancos de dados.
Relacional x Não relacional
Os bancos de dados relacionais dominaram o campo por décadas e ainda se mantêm relevantes. Eles dividem os dados entre várias tabelas relacionadas. As tabelas principais contêm linhas de identificadores exclusivos chamados “chaves primárias”. As tabelas secundárias fazem referência às chaves primárias com outros identificadores (“chaves externas”). No diagrama, a Tabela A é a principal e a Tabela B é a secundária.

Características dos bancos de dados relacionais
Os administradores e desenvolvedores normalmente acessam e manipulam dados em um banco de dados relacional usando linguagem de consulta estruturada (SQL, structured query language). As transações têm quatro características (que você pode lembrar com o acrônimo ACID). Os bancos de dados relacionais valorizam mais a consistência do que a disponibilidade.
- Atomicidade: todas as tarefas precisam ter êxito ou a transação volta ao princípio.
- Consistência: o estado do banco de dados precisa permanecer consistente durante a transação.
- Isolamento: cada transação é autônoma e não depende de outras.
- Durabilidade: os dados de uma transação com falha podem ser recuperados.
Os bancos de dados relacionais são ideais para análises e operações de dados complexas. Eles seguem uma estrutura rígida e os dados precisam se enquadrar nela.
Por outro lado, os dados às vezes não podem ser adequados a uma estrutura rígida. Essa situação começou a aparecer nos anos 90, quando a Internet virou um fenômeno e os aplicativos da web produziram dados que não se encaixavam em categorias específicas. Vimos um grande retorno dos bancos de dados não relacionais, agora chamados às vezes de “not only SQL” ou “NoSQL”.
Tipos de bancos de dados não relacionais

São quatro ao todo.
- Os pares chave-valor usam o modelo de matriz associativa, o que significa que os dados são representados como uma coleção de pares (chave+valor).
- Os repositórios voltados para colunas usam uma estrutura de tabela. As colunas em uma tabela podem mudar de linha para linha.
- Os sistemas voltados para documentos salvam as informações de cada documento como uma única instância no banco de dados. Os documentos podem ser aninhados.
- Os grafos organizam elementos, o relacionamento entre os elementos e os atributos atribuídos tanto aos elementos quanto aos relacionamentos.
Características dos bancos de dados não relacionais
Os bancos de dados não relacionais têm três características em comum (que você pode lembrar com o acrônimo inglês BASE). Eles valorizam a disponibilidade em detrimento da consistência, o oposto do que ocorre com bancos de dados relacionais.
- Basically available (disponível basicamente): o sistema fica disponível mesmo em caso de falha.
- Soft state (estado reversível): o estado dos dados pode ser alterado.
- Eventual consistency (eventual consistência): a consistência não é garantida no nível da transação, mas os dados são, em algum momento, sincronizados em todos os nós.
Os bancos de dados não relacionais são altamente dimensionáveis, já que é fácil modelar a estrutura. A consistência pode ser imperfeita, já que não há a garantia de que todos os clientes veem os mesmos dados ao mesmo tempo.
Vamos comparar.
Relacional |
Não relacional |
|---|---|
Normalizado |
Não normalizado |
SQL |
SQL limitado ou SQL assíncrono |
Dados estruturados |
Dados estruturados ou não estruturados |
Transações ACID |
Sem transações ou transações limitadas |
Não há uma opção claramente melhor que a outra, já que cada tipo de banco de dados atende melhor a requisitos comerciais diferentes. Em termos de grandes volumes de informação, o não relacional é a melhor opção.
Olá, Big Data
Parece majestoso, mas o que é isso? Big data se refere a conjuntos de dados que sejam muito grandes ou complexos para serem tratados por softwares de aplicativo de processamento de dados tradicionais. Estamos falando de centenas de milhões (ou até bilhões) de linhas. E big data é a coqueluche agora que o armazenamento ficou barato e o processamento é rápido. A inteligência artificial (IA) usa aprendizado de máquina para processar registros mais rapidamente do que qualquer humano seria capaz.
Levando em conta o quão barato e rápido ficou tudo isso, as empresas não querem jogar dados fora. Mas como elas podem escolher entre bancos de dados não relacionais (para gerenciar a quantidade e variedade maciça de dados) e relacionais (para lidar com lógica de negócios complexa)? A verdade é que elas precisam de arquitetura empresarial para isso. Várias tecnologias precisam ser integradas a uma única solução abrangente.
Agora que você sabe um pouco sobre bancos de dados e os desafios de big data, veremos como o Salesforce pode ser usado para armazenar dados na próxima unidade.