데이터 구성 방법 알아보기
학습 목표
이 유닛을 완료하면 다음을 수행할 수 있습니다.
- 잘 구조화된 데이터가 어떻게 구성되어 있는지 설명할 수 있습니다.
- 잘 구조화된 데이터와 제대로 형식화되지 않은 데이터를 구분할 수 있습니다.
소개
이전 유닛에서는 고품질의 유용한 데이터의 몇 가지 특성을 살펴봤습니다. 특히 데이터 구성과 관련된 두 가지 특성은 입체적으로 구조화되고 원자적입니다. 차원 구조화된 데이터는 차원(정성적 값)과 측정(정량적 값)의 두 가지 유형으로 구성됩니다. Tableau가 데이터를 해석할 때 사용하는 조직 구조입니다. 원자적인 데이터는 세밀하게 세분화되어 있어 다양한 세부 수준에서 데이터를 분석할 수 있습니다.
데이터가 구성되면 여러 가지 방법으로 조사, 요약, 검색 및 필터링할 수 있기 때문에 분석하기가 더 쉽습니다. 정리되지 않은 데이터는 종종 분석 방법이 제한됩니다. 예를 들어, 데이터가 이미 월별로 요약되어 있으면 일별 또는 주별 추세를 검사할 수 없습니다.
이 유닛에서는 데이터가 얼마나 잘 구성되어 있는지 알아봅니다.
데이터 구성
데이터는 행과 열로 구성됩니다.
- 열은 수직이며 각 열은 다른 변수(또는 필드)를 나타냅니다. 데이터 리터러시 기본 사항 모듈은 변수를 변하거나 변경될 수 있는 항목의 측정값, 속성 또는 특성으로 정의합니다. Tableau Platform에서 변수는 필드라고 합니다.
- 행은 수평이며 각 행은 하나의 분석 단위를 나타냅니다. Tableau Platform에서 분석 단위를 값이라고 합니다.
예를 살펴보겠습니다. 가족이나 친구 중 몇 명을 생각해보고 이름, 연령, 키, 좋아하는 음식 등의 변수(또는 필드)를 사용하여 표를 만듭니다. 표은 아래와 같이 생겼을 수 있습니다.
| 이름 | 기간 | Height (inches) | Favorite food |
|---|---|---|---|
|
Aliya |
8 |
50" |
Ice cream |
|
Miles |
12 |
63” |
Olive pizza |
|
Penny |
42 |
67” |
Corn on the cob |
|
Vince |
39 |
70” |
Pancakes |
보시다시피 변수(또는 필드)는 이름, 연령, 키 및 좋아하는 음식에 대해 각각 하나의 열로 구성됩니다. 각 행은 하나의 분석 단위(또는 값)를 나타냅니다. 이 경우 모든 행을 읽으면 한 사람의 이름, 연령, 키, 좋아하는 음식이 표시됩니다. 예를 들어, 알리야는 8살이고, 키는 50 "이고, 아이스크림을 좋아합니다.
"양질"의 데이터 구성
"양질"의 데이터는 잘 구조화된 데이터이며 이러한 방식으로 구성됩니다.
- 각 변수(필드)는 열 머리글이 있는 하나의 열에 있습니다.
- 해당 변수(값)의 각 다른 관찰은 다른 행에 있습니다.
예를 들어, 이 간단한 표를 보세요. 변수(필드)는 공급업체, 도시 및 주이며 각 변수는 열 머리글이 있는 자체 열에 있습니다. 각 행은 변수(값)의 관찰 내용을 나열하며, 이 경우 도시 및 주별 공급업체 이름과 위치를 나열합니다. 공급업체의 상태를 자체 열에 두면 상태별로 공급업체를 검색하고 필터링할 수 있습니다. 공급업체의 도시와 주를 하나의 필드로 결합하면 이러한 유형의 분석이 더 어려워집니다.
| Vendor | 도시 | 주 |
|---|---|---|
|
Polly’s Lollipops |
Preston |
WA |
|
Lucy’s Lollies |
Lansing |
MI |
|
Carlo Callazo’s Candy |
Cambridge |
MA |
|
Ming’s Minty Meringues |
Madison |
WI |
제대로 서식이 지정되지 않은 데이터
제대로 서식이 지정되지 않은 데이터는 데이터에 혼란을 일으키거나 Tableau를 포함한 소프트웨어 프로그램이 데이터를 해석하기 어렵게 만드는 특정 특성을 포함합니다. 이러한 문제 중 일부는 다음과 같습니다.
- 변수(필드)는 열 머리글과 함께 각각 하나의 열에 있지 않습니다.
- 변수(값)의 각각의 다른 관찰 내용은 여러 행에 있지 않습니다.
- 제목은 열 머리글 위의 행 또는 추가 열로 서식이 지정됩니다.
- 여분의 열과 행이 있습니다.
- 열 머리글은 첫 번째 행이 아닌 자막으로 서식이 지정됩니다.
예를 들어, 2019년 캘리포니아와 뉴욕에서 16,000명의 표본이 본 평균 영화 수를 기록한 표입니다.
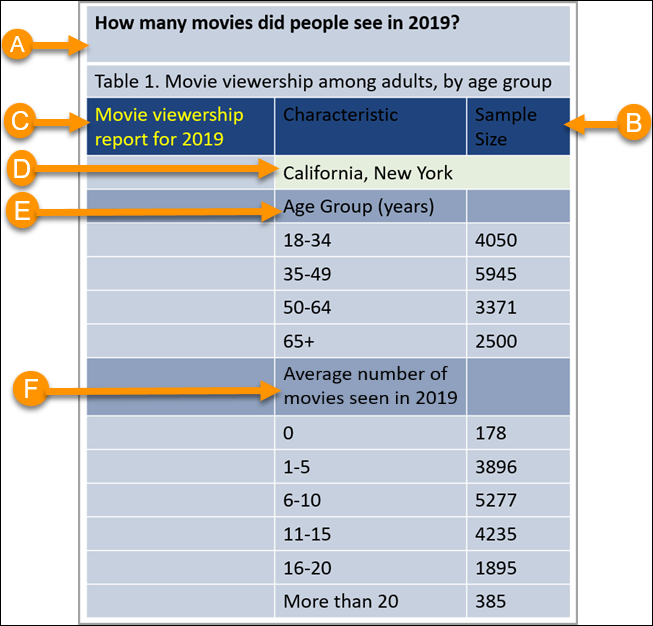
위에 나열된 제대로 서식이 지정되지 않은 데이터의 특징이 있나요?
- A. 행의 제목: 첫 번째 행에는 열 머리글만 포함되어야 합니다. 이 행과 아래 행은 열 머리글이 아닌 제목입니다.
- B. 세 번째 행의 열 머리글: 강조 표시되어 있음에도 불구하고 특성 및 표본 크기 셀은 Tableau를 포함한 대부분의 소프트웨어 프로그램에서 열 머리글로서 읽히지 않습니다.
- C. 추가 열: 보고서의 제목이지만 자체 열로 서식이 지정됩니다.
- D. 추가 행: 상태는 변수(필드)이며 행이 아닌 열 머리글이 있는 자체 열이어야 합니다.
- E. (및 F.) 자막으로서의 변수(필드): 자막(연령대, 2019년에 본 영화의 평균 수)은 자체 열에 존재해야 하는 변수(필드)입니다.

이제 데이터가 어떻게 구성되어 있는지, 그리고 잘 구조화되어 있는 데이터와 제대로 서식이 지정되지 않은 데이터의 차이점을 알 수 있습니다. 다음 유닛에서는 제대로 서식이 지정되지 않은 데이터를 재구성하는 몇 가지 방법을 살펴보겠습니다.