모델 평가
학습 목표
이 유닛을 완료하면 다음을 수행할 수 있습니다.
- 모델이 무엇이고 어디에서 비롯되는지 설명할 수 있습니다.
- 모델 품질을 이해하기 위해 모델 메트릭을 사용하는 이유를 서술할 수 있습니다.
모델, 변수 및 관측치
이 모듈의 앞부분에서 알아본 내용을 되돌아보면, 모델은 과거 성과에 대한 포괄적이고 통계적인 이해를 기반으로 하며 정교한 수학적 사용자 정의 구성입니다. Einstein Discovery는 데이터를 기반으로 모델을 생성(훈련)합니다. Einstein은 모델을 사용하여 진단적 인사이트와 비교적 인사이트를 생성합니다. 모델을 프로덕션에 배포한 후 라이브 데이터에 대한 예측 및 개선 사항을 얻기 위해 사용할 수 있습니다.(자세한 내용은 뒷부분에서 살펴보죠!) .
변수
모델에 대해 더 자세히 알아보겠습니다. 우선 모델이 변수를 기준으로 데이터를 정리한다는 사실을 알면 유용합니다. 변수는 데이터 범주이며, CRM Analytics 데이터 집합의 열이나 Salesforce 개체의 필드와 유사합니다. 모델에는 두 가지 종류의 변수인 입력(예측 변수)과 출력(예측)이 있습니다.
관측치
예측은 관측 단계에 발생합니다. 관측치는 정형화된 데이터 집합이며, CRM Analytics 데이터 집합의 채워진 행이나 Salesforce 개체의 레코드와 유사합니다.

각 관측치에 대해, 모델은 하나의 예측 변수 집합을 입력(1)으로 받아들이고 해당하는 예측(2)을 출력으로 반환합니다. 요청되는 경우, 모델이 상위 예측 변수 및 개선 사항도 반환할 수 있습니다. 이 그림에서 실제 성과(IsWon)는 아직 알 수 없습니다.
어디에나 있는 모델
모델이 Einstein Discovery나 Salesforce에만 있는 것은 아닙니다. 실제로 예측 모델은 전세계의 여러 산업, 조직 및 분야에서 광범위하게 사용되며, 일상 생활의 여러 측면과 관련이 있습니다. 데이터 과학자들과 기타 전문가들은 그들의 탁월한 재능을 매우 정확하고 유용한 예측을 생성할 수 있는 양질의 모델을 설계하고 만드는 데 이용합니다.
하지만 많은 조직은 모델을 잘 만든 후 프로덕션 환경 안에서 구현하고 운영과 원활하게 통합하여 운영에 의도한 유익을 가져오기 어려울 수 있다는 일반적인 문제에 직면합니다. 이제는 Einstein Discovery를 사용해 모델을 만들고 프로덕션에 배포한 후 예측을 얻고 라이브 데이터를 사용해 더 나은 비즈니스 결정을 곧바로 내리는 등 운영에 빨리 적용할 수 있습니다. Einstein Discovery에 업로드하는 외부에서 만든 모델을 운영에 적용할 수도 있습니다.
좋은 모델이란 무엇인가요?
모델이 생성하는 예측을 토대로 비즈니스 결정을 내릴 계획이라면 당연히 성과를 예측하는 데 매우 뛰어난 모델을 원할 것입니다. 적어도 모델이 없어 단순히 임의적인 추측에만 의존함으로 인해 데이터 없이 결정을 내리는 경우보다는 성과를 더 잘 예측하는 모델을 원할 것입니다.
그렇다면 좋은 모델의 요소는 무엇일까요? 좋은 모델은 대체로 성과 개선 목표를 지원할 수 있을 만큼 정확한 예측을 생성하여 솔루션 요구 사항을 충족합니다. 간단히 말해, 모델의 예측 성과가 실제 결과와 얼마나 가깝게 일치하는지 알아야 합니다.
Einstein Discovery는 일반적인 모델 성능 측도를 시각화하는 모델 메트릭을 제공하여 모델의 성능을 판단하는 데 도움이 됩니다. (데이터 과학자들은 이를 모델의 예측이 실제 데이터에 얼마나 잘 맞는지 수량화하는 적합도 지수라고 합니다.) 모델은 실세계의 추상적인 근사치이므로 필연적으로 어느 정도 부정확할 수밖에 없음을 기억하세요. 실제로 ‘완벽한’ 모델은 희망을 주지 않고 오히려 의구심을 더 자아냅니다. 이에 대해서는 나중에 설명하겠습니다.
자주 인용되는 ‘모든 모델은 틀리지만 일부 모델은 유용하다’라는 통계학자 George Box의 말을 떠올리면 모델을 이해하는 데 도움이 됩니다.
모델이 얼마나 유용할 수 있는지 알아보겠습니다.
모델 성과 탐색하기
Einstein Discovery에서 모델 성과는 모델의 품질 측도와 관련 세부 사항을 나타냅니다. 모델 성과는 모델의 성과 예측 능력을 평가하는 데 활용할 수 있습니다. 모델 성과 메트릭은 모델을 학습시키는 데 사용하는 CRM Analytics 데이터 집합의 데이터를 사용하여 계산됩니다. 알려진 (관측된 또는 실제) 성과가 있는 데이터 집합의 모든 관측치에 대해, Einstein Discovery는 예측을 계산한 후 예측된 성과를 실제 성과와 비교하여 예측의 정확도를 결정합니다.
중요: Einstein Discovery는 사용자를 위해 만든 모델을 설명하는 여러 가지 메트릭을 제공하는데, 이런 메트릭은 너무 많아서 이 모듈에서 모두 설명할 수 없습니다. 하지만 일부 또는 대부분의 메트릭은 몰라도 되는 것이니 걱정하지 마세요. 여기서는 가장 중요한 메트릭에 대해서만 설명합니다.
Einstein Discovery는 포괄적인 메트릭 집합을 제공하여 다양한 관점에서 모델의 성능을 평가하는 여러 가지 방법으로 모델의 완전한 투명성을 보장합니다. 따라서 솔루션에 가장 적합한 메트릭(이 유닛에서 다루지 않은 메트릭 포함)을 사용해 모델의 품질을 평가할 수 있습니다.
Einstein Discovery를 사용하면 이런 메트릭을 계산하는 데 필요한 세부 사항과 수학을 모두 이해하지 않아도 해석할 수 있습니다. 이 유닛에서 다루지 않는 특정 메트릭 또는 화면에 대해 자세히 알아보려면 정보 버블 또는 자세히 알아보기
또는 자세히 알아보기 를 클릭하세요.
를 클릭하세요.
모델 성과 개요
모델 성과는 모델을 열면 가장 먼저 보게 되는 페이지입니다. 모델 성과를 사용하여 모델의 품질을 평가하세요.
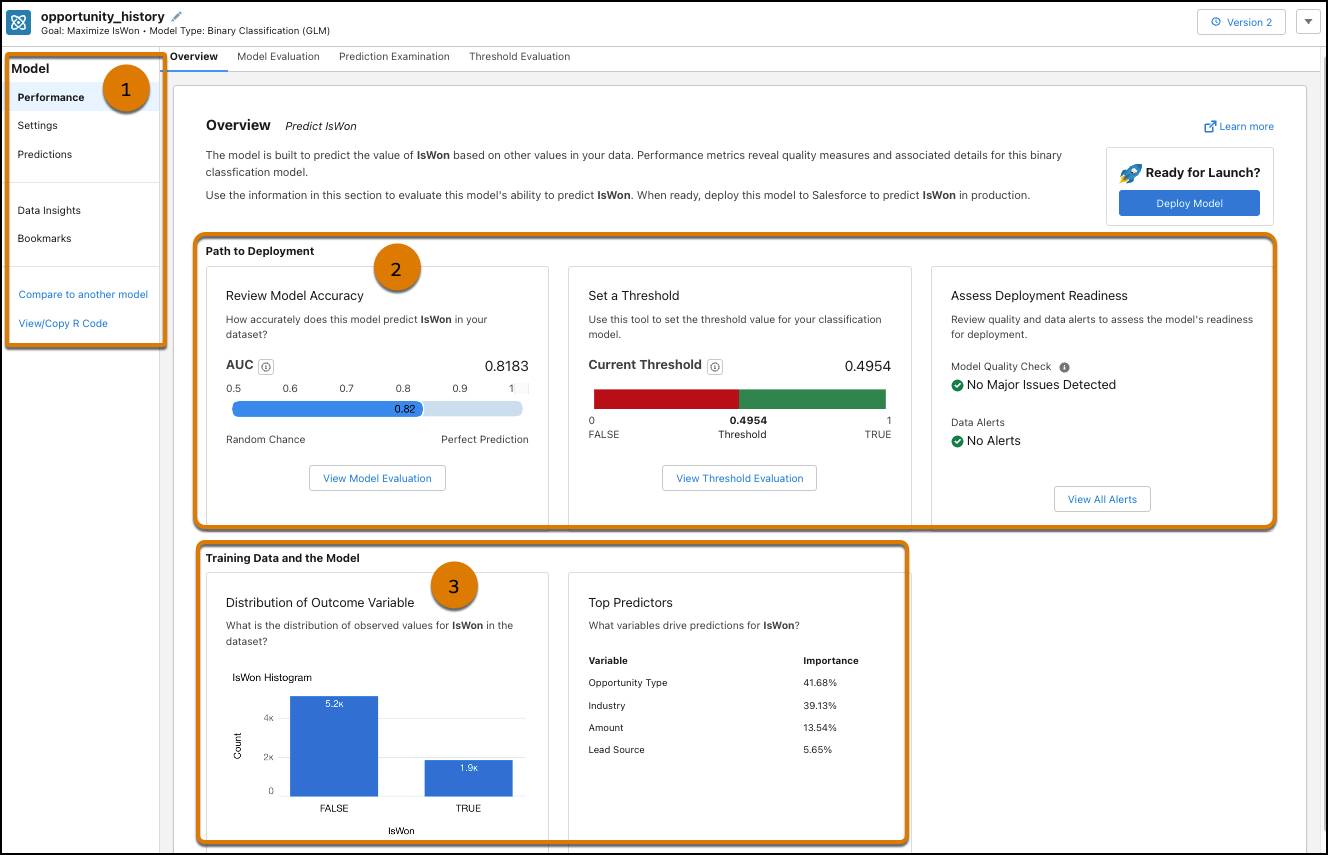
참고: 숫자 및 이진 분류 사용 사례의 모델 메트릭은 서로 다릅니다. 이 모듈에서는 이진 분류 사용 사례인 isWon 극대화를 위한 모델 메트릭에 초점을 맞춥니다.
왼쪽 패널(1)에는 다음이 표시됩니다.
- Navigation to Model(모델로 탐색) 섹션
- 데이터 인사이트 및 책갈피
- 다른 작업으로 연결되는 링크
Path to Deployment(배포 경로) 패널(2)에는 다음이 표시됩니다.
-
Review Model Accuracy(모델 정확성 검토): 이진 분류 솔루션의 경우, 모델 품질을 평가하려는 데이터 과학자들은 종종 AUC(곡선 아래 면적) 통계를 가장 먼저 확인합니다. 여기서는 0.5(무작위 기회)보다 크고 1.0(일반적으로 데이터 누출 문제가 있음을 의미하는 완벽한 예측)보다 낮은 AUC가 목표입니다. 모델의 AUC 값은 0.8183으로, 양호한 범위에 속합니다.
참고: 숫자 모델에서 이에 해당하는 지표는 R^2이며, 이는 회귀 모델이 결과의 변동을 얼마나 잘 설명하는지를 측정합니다. R^2의 범위는 영(0)(무작위 기회)부터 일(1)(완벽한 모델)까지입니다. 일반적으로 R^2가 높을수록 모델이 성과를 더 잘 예측합니다.
-
Set a Threshold(임계값 설정): 이진 분류 모델의 경우, 임계값은 0부터 1 사이의 숫자인 예측 점수를 기준으로 예측이 true 또는 false로 분류되는지 결정하는 값입니다. 이 예시에서 예측 점수가 0.4954 이상이면 예측 결과는 TRUE입니다. 임계값에 대한 자세한 설명은 이 모듈의 범위에 해당되지 않습니다. 솔루션 요구 사항에 따라 특정 성과를 다른 성과보다 선호하도록 모델을 조정할 수 있다고만 설명하겠습니다.
-
Assess Deployment Readiness(배포 준비 평가): Einstein Discovery는 모델 품질 검사를 수행하고 발견된 문제를 여기에 표시합니다. 예에는 데이터 경고가 없습니다. 이전 유닛에서 경고를 이미 해결했기 때문입니다.
Training Data and the Model(학습 데이터와 모델) 패널(3)에는 다음이 표시됩니다.
-
Distribution of the Outcome Variable(성과 변수 분포): 학습 데이터에 TRUE 및 FALSE 관측치(실제 성과)가 몇 개 있는지 표시합니다.
-
Top Predictors(상위 예측 변수): 성과와 상관 관계가 가장 높은 예측 변수를 표시합니다. 샘플 데이터에서는 Opportunity Type(기회 유형)의 상관 관계가 가장 높고, Industry(산업)가 그 다음으로 높습니다.
예측 검사
Prediction Examination(예측 검사) 탭을 클릭합니다.

오른쪽의 Einstein 예측 패널은 학습 데이터의 선택된 행에 대해 예측된 성과를 실제 성과와 비교하고 예측된 성과에 기여한 상위 요인과도 비교합니다. 행을 클릭하면 이 패널이 업데이트됩니다.
이 화면은 주행 테스트와 비슷합니다. 모델이 배포된 후 성과를 어떻게 예측할지 미리 보면 유용합니다. AUC는 모델의 집계 측정값을 제공했지만, 이 화면에서는 모델의 예측을 대화형으로 드릴다운 및 분석할 수 있습니다.
참고: Einstein Discovery는 데이터 집합에서 데이터 표본을 무작위로 추출하므로 화면에 이 스크린샷과 다른 데이터가 표시될 수 있습니다.
예측 및 개선 사항 탐색하기
Einstein Discovery의 기능을 이용하여 미래를 예측해 보겠습니다. 이 섹션에서는 시나리오를 선택하고 Einstein이 통계적으로 개연성이 있는 미래 결과와 결과를 개선하는 방법에 대한 제안을 계산하도록 하여 Einstein을 활용합니다.
참고: 이 유닛에서는 모델을 사용하여 가정 예측 및 개선을 탐구하는 방법에 대해 설명합니다. 나중에는 모델을 Salesforce에 배포하여 현재 레코드에 대한 예측과 개선 사항을 얻는 방법에 대해 알아봅니다.
왼쪽 탐색 패널에서 Predictions(예측)를 클릭합니다.

오른쪽 패널에서 모델에 입력할 사항을 선택합니다.
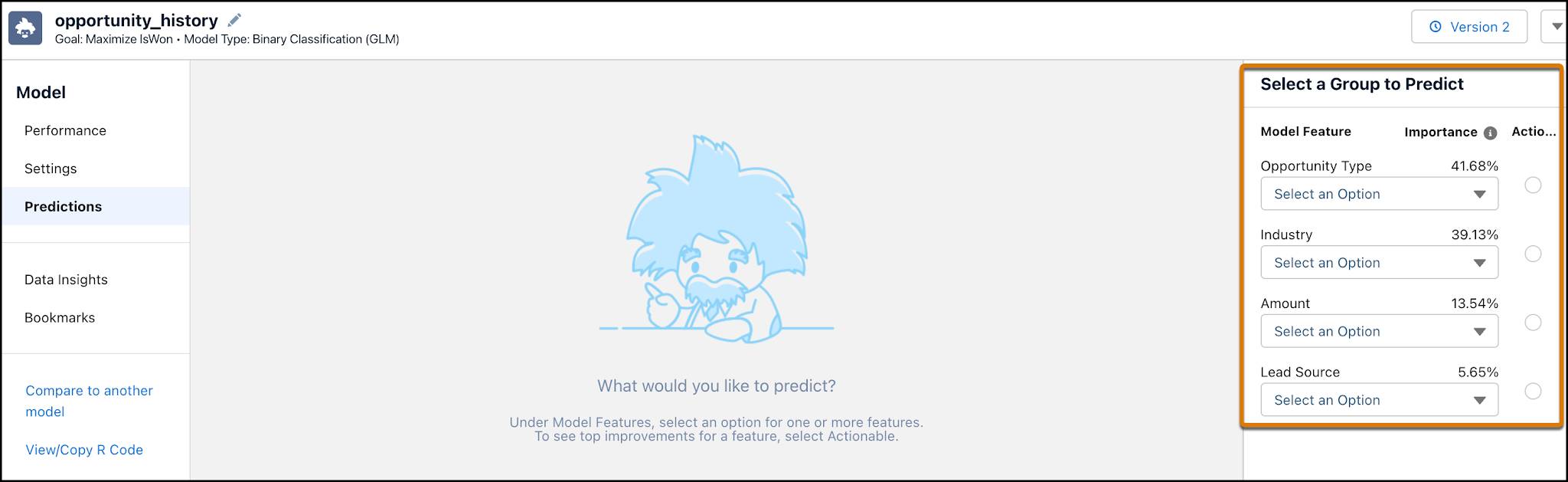
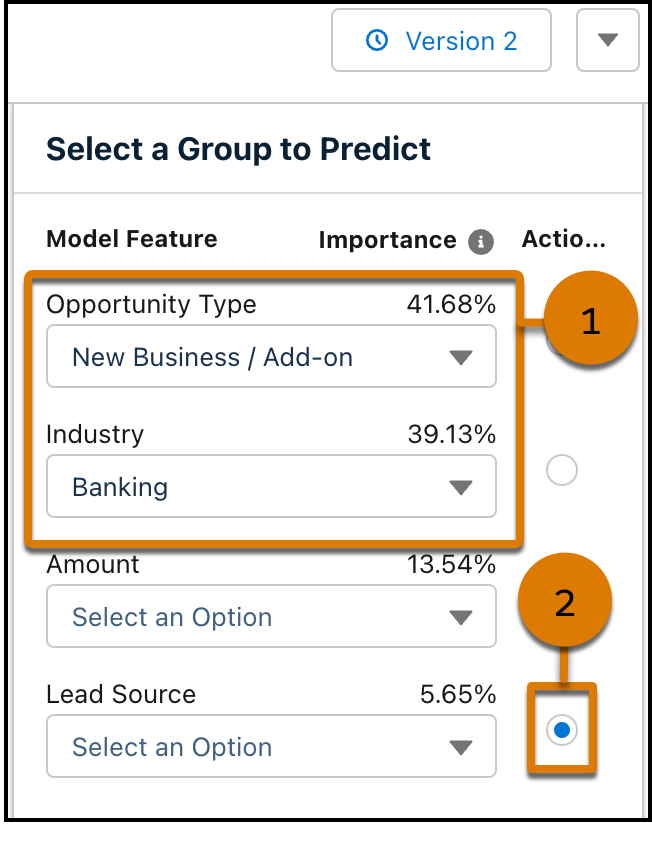
Select a Group to Predict(예측할 그룹 선택)에서 Opportunity Type(기회 유형)으로 New Business / Add On(새 비즈니스/추가)을 선택하고 Industry(산업)로 뱅킹(1)을 선택합니다. Lead Source(리드 소스)(2) 옆에 있는 Actionable(실행 가능) 버튼을 선택하여 개선 사항을 확인합니다.
메인 페이지에는 다음과 같은 패널이 보입니다(모든 패널을 보려면 아래로 스크롤해야 할 수 있음).
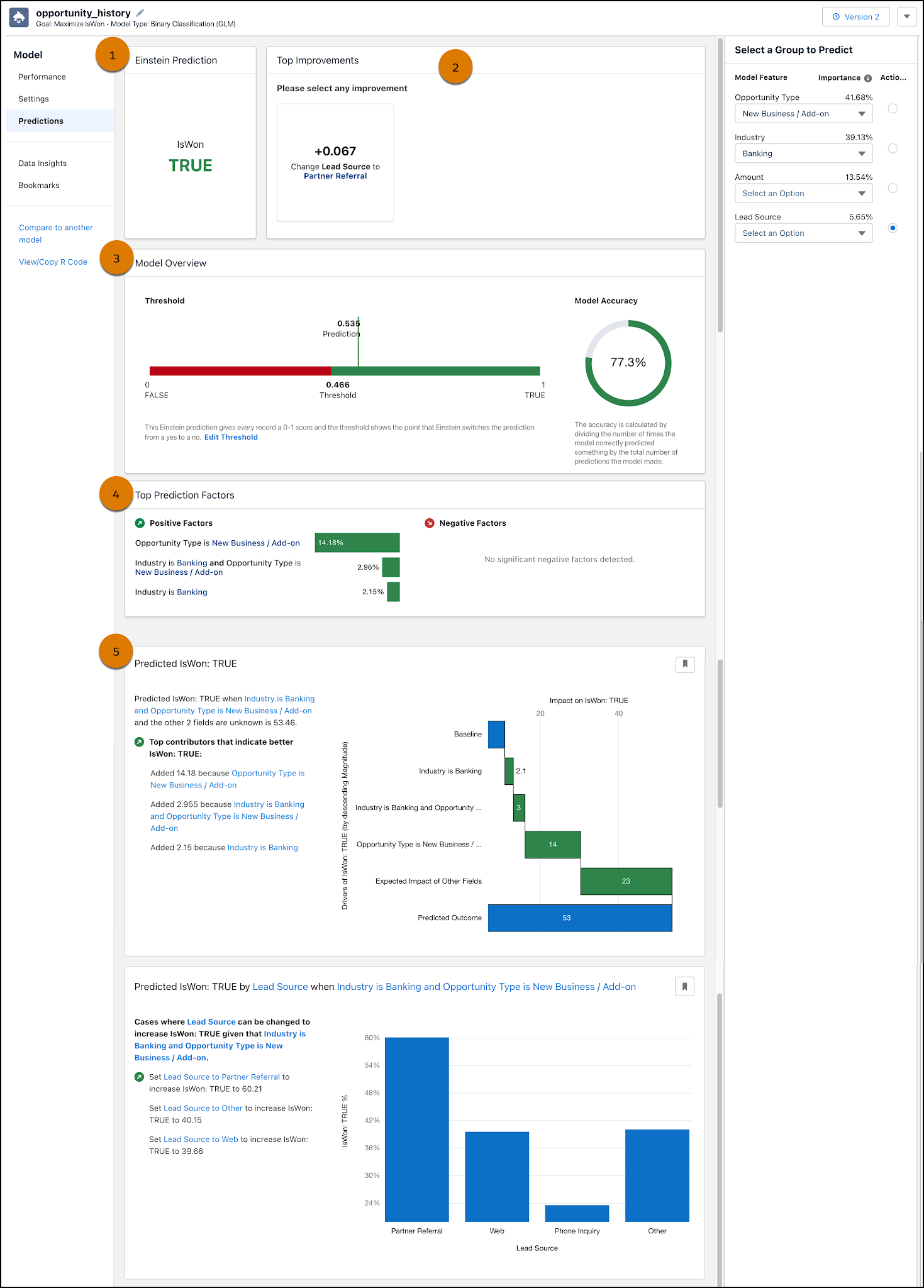
-
Einstein Prediction(Einstein 예측)(1)에는 선택 사항에 대한 예측 점수가 표시됩니다. 이 예에서 예측된 성과는 IsWon: True입니다.
-
Top Improvements(상위 개선 사항)(2)에는 예측된 성과를 개선하기 위해 취할 수 있는 추천 작업이 표시됩니다. 이 예에서 기회의 리드 소스를 파트너 소개로 변경하면 예측된 성과가 0.067만큼 개선됩니다.
-
Model Overview(모델 개요)(3)에는 모델에 대한 품질 메트릭이 표시됩니다.
-
Top Prediction Factors(상위 예측 요인)(4)에는 예측된 성과와 가장 강력한 연관 관계가 있는 유리하고 불리한 설명 변수가 표시됩니다. 이 예에서 Opportunity Type(기회 유형)이 New Business / Add-on(새 비즈니스/추가)인 경우는 예측된 성과를 14.18% 개선합니다.
-
Insights(인사이트)(5)에는 선택 사항과 관련된 추가 인사이트가 표시됩니다.
다음 단계
이제 모델을 평가했으니 데이터 인사이트를 살펴보겠습니다.
리소스