모델 만들기
학습 목표
이 유닛을 완료하면 다음을 수행할 수 있습니다.
- Einstein Discovery 모델이 무엇이며 왜 사용하는지 설명할 수 있습니다.
- Einstein Discovery 모델의 주요 요소를 설명할 수 있습니다.
- Einstein Discovery에서 모델을 구성하고 만들 수 있습니다.
모델이란?
모델은 미래 결과를 예측하는 데 사용되는 과거 결과에 대한 포괄적이고 통계적인 이해를 기반으로 하며 정교한 맞춤형 방정식입니다. Einstein Discovery 모델은 성과 지표, 설정, 예측, 데이터 인사이트의 집합입니다. Einstein Discovery는 개선하려는 성과(모델의 목표), 해당 목적으로 수집한 데이터(CRM Analytics 데이터 집합), 그리고 분석을 수행하고 분석 결과를 전달하는 방법을 Einstein Discovery에 지시하는 기타 설정에 따라 모델을 만드는 단계를 하나씩 안내합니다.
모델 만들기
이전 유닛에서 준비한 CRM Analytics 데이터 집합을 사용하여 예측 모델을 만드는 방법은 다음과 같습니다.
- 이전 유닛에서 로드한 데이터 집합을 계속 보고 있는 경우 Create Model(모델 만들기)을 클릭하고 4단계로 이동합니다. 그렇지 않으면 Analytics Studio 홈 페이지에서 Create(만들기)를 클릭하고 Model(모델)을 선택합니다.
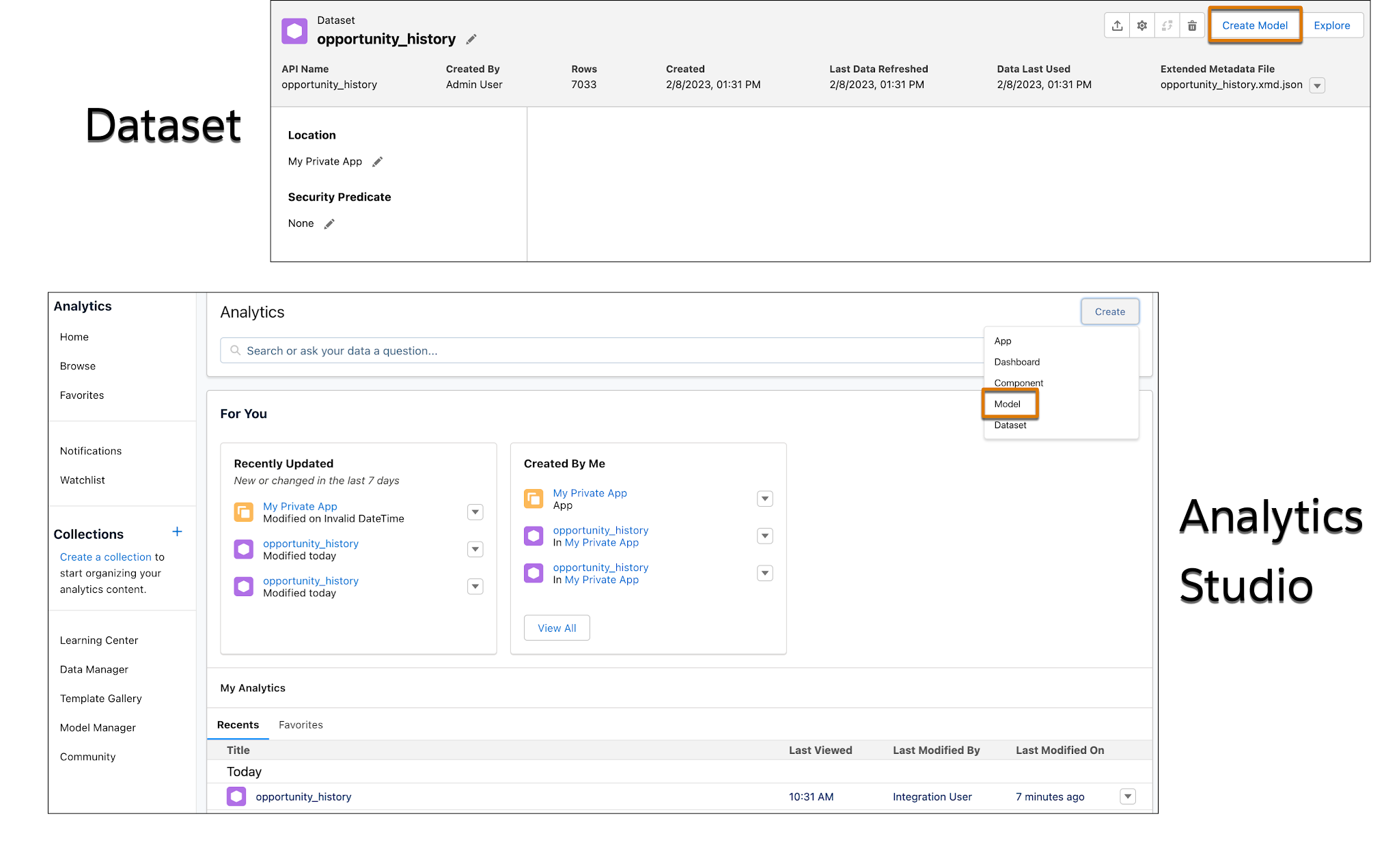
- New Model(새 모델) 화면에서 Create from Dataset(데이터 집합에서 만들기)를 클릭한 후 Continue(계속)를 클릭합니다.
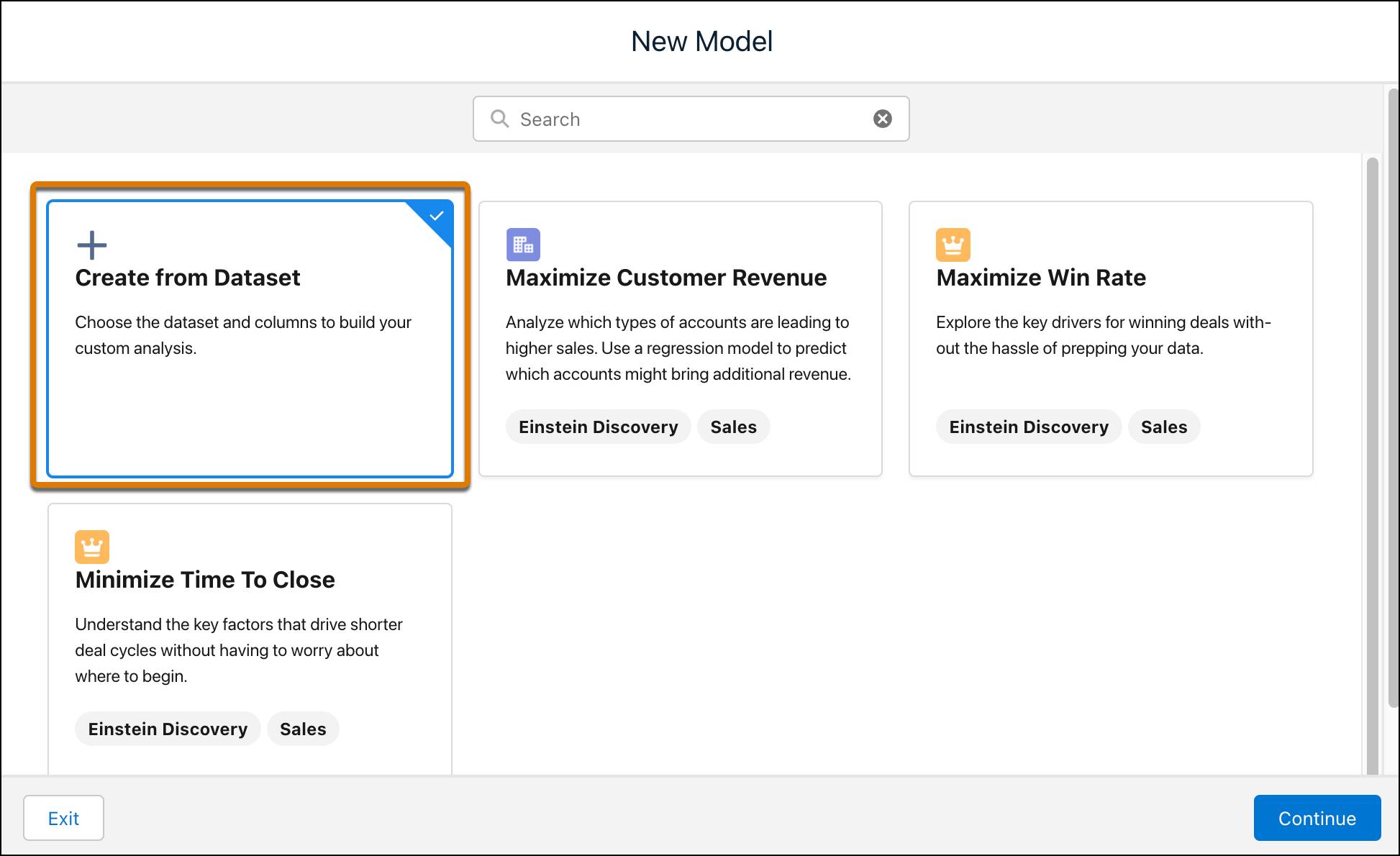
- 이전 유닛에서 만든 opportunity_history 데이터 집합을 선택한 후 Next(다음)를 클릭합니다.

- Create Model(모델 만들기) 화면에서 목표를 지정합니다. 목표는 예측할 모델을 분석하고 학습시키려는 결과를 정의합니다. 결과를 최대화 또는 최소화할지 여부를 지정합니다.
이 모듈에서 목표는 기회 성공을 극대화하는 것입니다. I Want to Predict(예측 대상)로 IsWon을 선택하고 Maximize(극대화) 옆의 IsWon:TRUE를 변경합니다. 그 외 기본 설정을 모두 그대로 사용하고 Next(다음)를 클릭합니다.
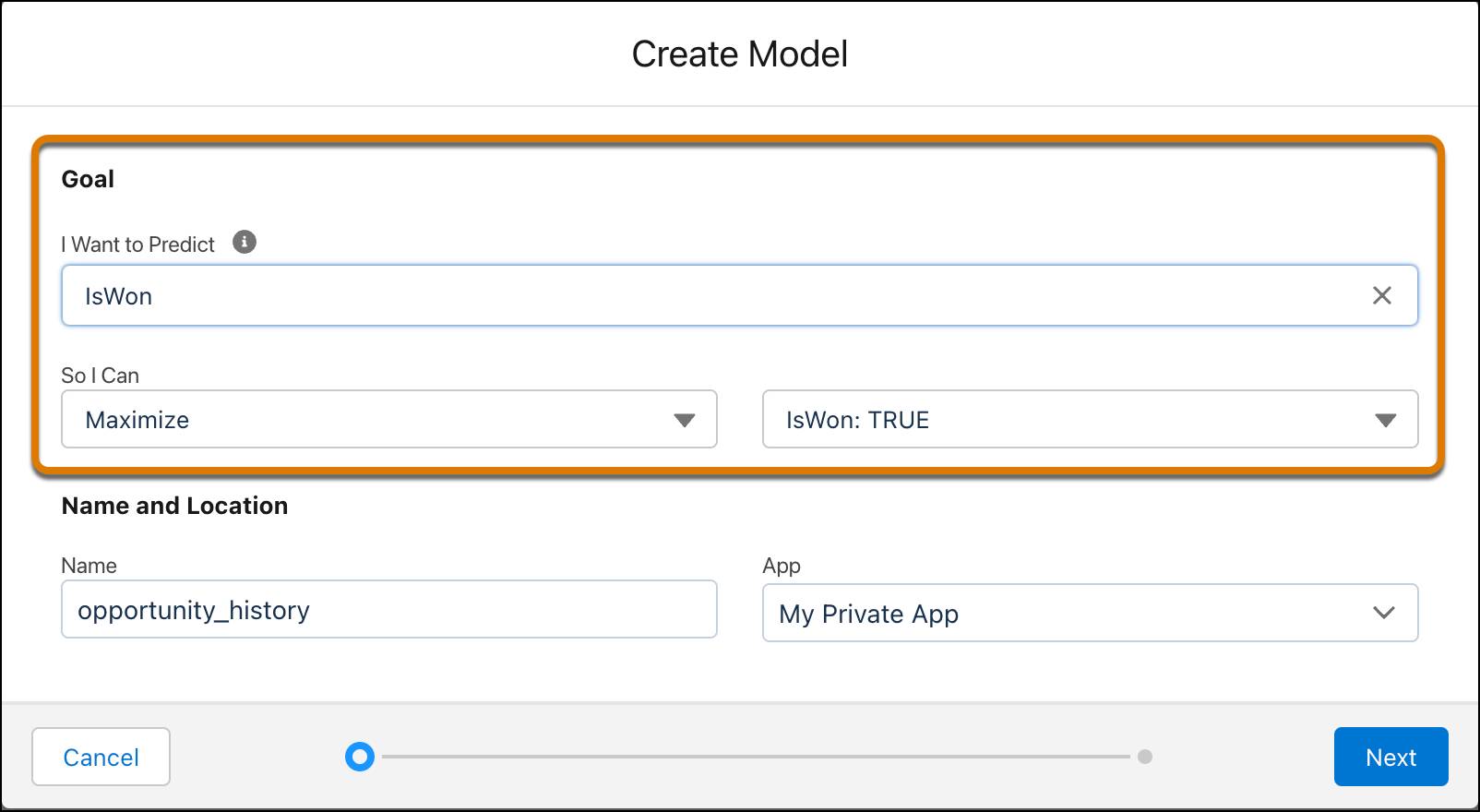
- Configure Model Columns(모델 열 구성) 화면에서 기본값(Automated(자동))을 그대로 사용하고 Create Model(모델 만들기)을 클릭합니다.
Einstein이 예측 모델을 구축하기 위해 통계 분석, 머신 러닝 알고리즘 및 AI를 사용하여 데이터를 분석하기 시작합니다.

완료되면 Einstein에서 모델의 성과 개요를 확인할 수 있습니다.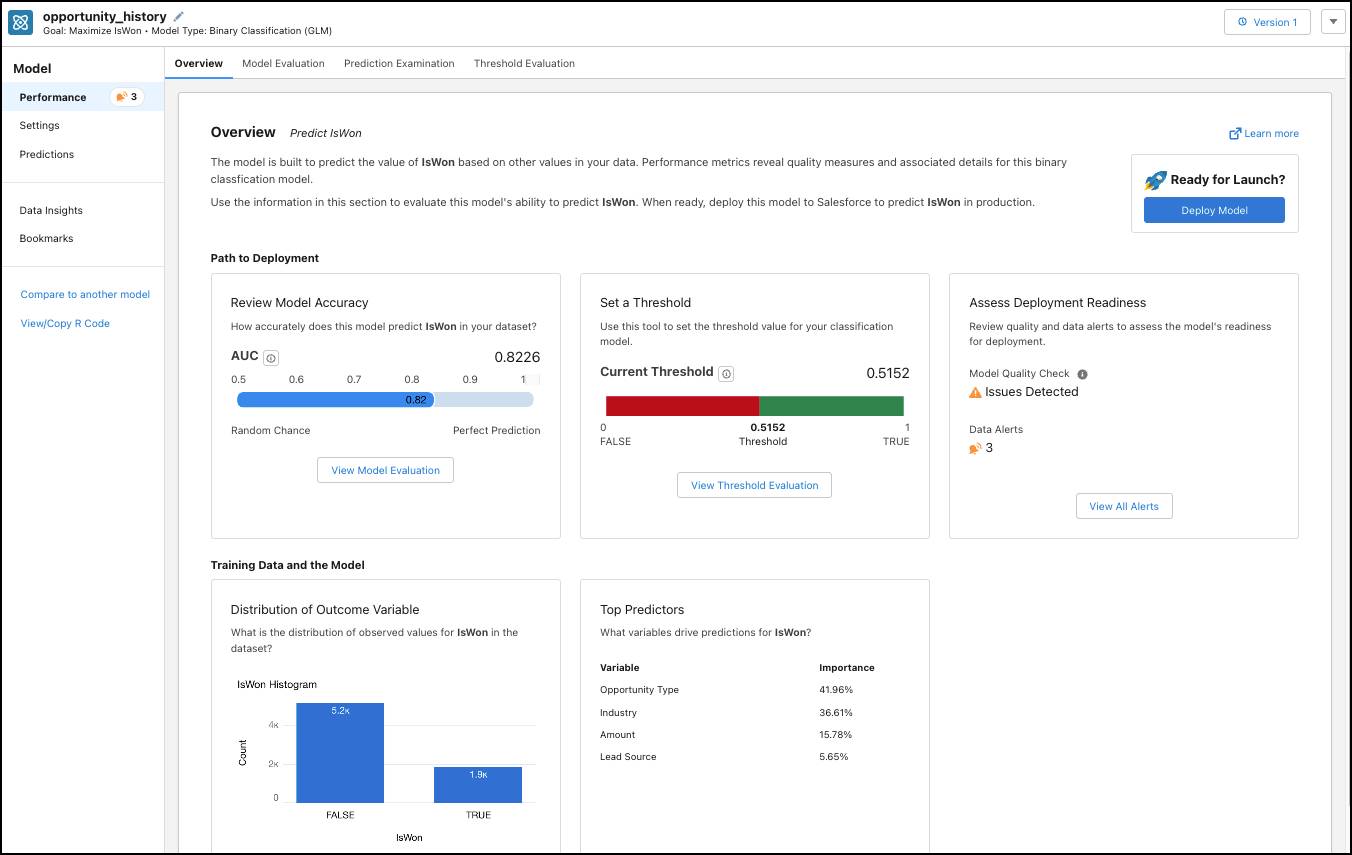
데이터 품질 경고 조사하기
분석 및 학습 중에 Einstein Discovery는 데이터에 중복 영향(다중공선성 데이터 경고라고 함), 잠재적 편차 또는 자주 누락되는 값 같은 품질 문제나 다른 데이터 품질 문제가 있는지 조사합니다. 잠재적 데이터 품질 문제가 감지될 때마다 Einstein은 데이터 경고를 통해 이를 알립니다. 데이터 경고에 대해 자세히 알아보려면 Handle Quality Alerts(품질 경고 처리)를 확인해 보세요.
모델 성과 개요에서 Assess Deployment Readiness(배포 준비 평가)를 확인하고 View All Alerts(모든 경고 보기) 버튼을 클릭하여 모델에 대한 모든 경고를 조사하세요.

Data Alerts(데이터 경고) 패널에 발생한 경고가 각각 표시되고 조치를 취하거나 경고를 무시하는 옵션이 제시됩니다.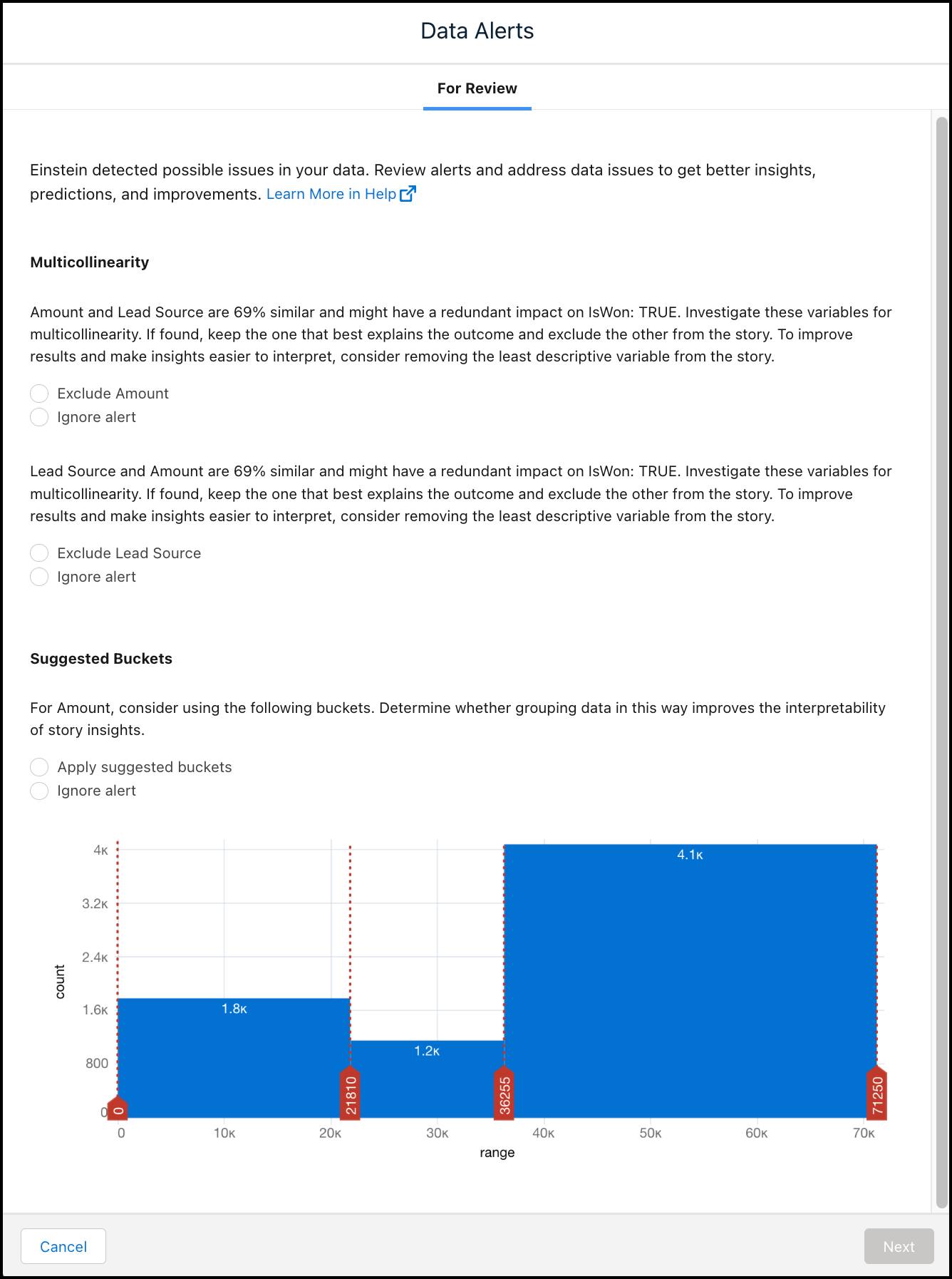
Einstein이 모델에서 데이터에 다중공선성이 있음을 발견했습니다. 변수 중 두 개 이상(금액 및 리드 소스)의 상관성이 매우 높고 이런 변수가 성과에 중복으로 영향을 미칠 수 있다는 것이 문제입니다. 이 모듈에서는 금액 및 리드 소스에 대해 Ignore Alert(경고 무시)를 선택합니다.
Einstein은 Amount(금액) 값을 여러 범위(버킷)에 따라 범주로 구분할 기회도 발견했습니다. Suggested Buckets(추천 버킷)에서 Apply suggested buckets(추천 버킷 적용)를 선택합니다. 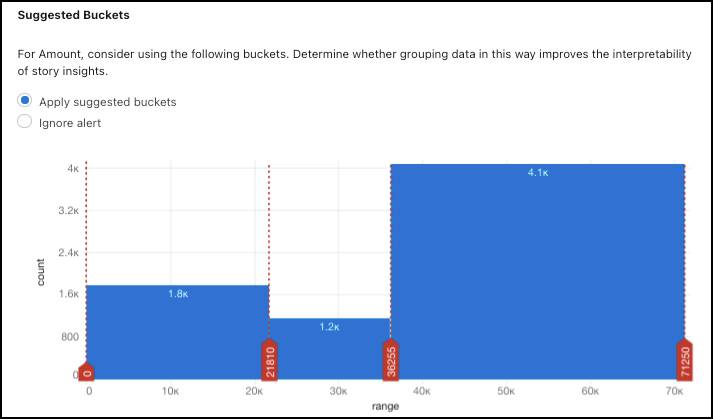
모델 버전 만들기
Next(다음)를 클릭합니다. 새 모델 버전을 설명하라는 Einstein Discovery 프롬프트가 표시됩니다.
모델을 변경할 때마다 새 버전을 만들어 분석을 다시 실행하고 모델을 다시 훈련시켜야 합니다. 이 상황에는 Einstein이 최신 설정을 사용하여 데이터를 다시 분석해야 하므로 새 버전이 필요합니다. 이 모듈의 앞부분에서 Einstein Discovery 솔루션 개발이 반복 실행 프로세스임을 배웠습니다. 모델 버전은 각 반복 실행을 추적하는 데 도움이 됩니다.
상자에 Ignore multicollinearity alerts and apply buckets to Amount(다중공선성 경고를 무시하고 금액에 버킷 적용)를 입력한 후 Train Model(모델 훈련)을 클릭합니다.

Einstein은 새 버전에서 모델을 다시 분석하고 다시 훈련시킵니다. 새 버전이 완성되면 모델 성과 개요를 다시 볼 수 있습니다. 새 버전에 새 버전 번호가 표시되고 검토할 경고가 더 이상 없습니다.

모델 설정 편집하기
모델을 사용자 정의하려면 Settings(설정)를 클릭합니다.
이제 모델 설정을 살펴볼 수 있습니다.

데이터 집합 세부 사항
데이터 집합(1)의 행 및 열 수가 보입니다. Einstein Discovery에서는 데이터 집합의 각 행을 관측치라고 하고 각 열을 변수라고 합니다.
변수 테이블
변수 테이블(2)에는 모델의 변수가 표시됩니다.
- 첫 번째 변수(IsWon)는 개선하려는 비즈니스 성과인 성과 변수입니다. 목표는 IsWon 극대화입니다.
- 다음은 설명 변수입니다. 설명 변수는 모델의 성과 변수에 영향을 줄 수 있는지 여부와 영향의 정도를 파악하기 위해 살펴보는 변수입니다.
-
중요도는 모델의 예측 결과에 대한 변수의 상대적 영향입니다. 중요도는 모델이 결과를 예측할 때 변수를 얼마나 많이 사용하는지를 나타냅니다. 중요도는 백분율로 수량화됩니다. 백분율이 높을수록 영향력이 커집니다. 중요도는 변수 간의 상호 작용을 기반으로 하는 고급 지표입니다. 두 지표의 상관성이 높고 유사한 정보가 포함된 경우 모델은 사용하기에 더 나은 변수를 선택합니다.
- 중요도 대신 상관 관계를 확인하려면 열 드롭다운을 사용하세요. 상관 관계는 간단히 말해 설명 변수와 성과 변수의 통계적 연관성, 즉 ‘상관성’입니다. 상관 관계의 강도는 백분율로 수량화됩니다. 백분율이 높을수록 상관 관계가 더 강함을 의미합니다. 상관 관계는 인과 관계가 아니라는 점에 유의하세요. 상관 관계는 변수 간의 연관성 강도를 나타낼 뿐, 서로 간에 인과적 영향을 미치는지 여부를 나타내는 것이 아닙니다. 상관 관계를 해당 필드가 단독으로 성과를 얼마나 잘 예측할 수 있는지 가늠하는 척도라고 생각하세요.
- 데이터 경고는 Einstein Discovery가 데이터에서 특별히 주의를 기울여야 할 수 있는 문제를 발견하는 경우에 표시됩니다.
일반 설정
오른쪽 패널의 General Settings(일반 설정)(3)은 모델이 사용하는 데이터 집합을 보여 줍니다. 모델의 유효성 검증 및 알고리즘을 확인하고 변경할 수도 있습니다.
변수 설정 편집
변수 테이블에서 Industry(산업)를 클릭합니다. 오른쪽 패널에서 선택한 변수에 대한 설정을 구성합니다. 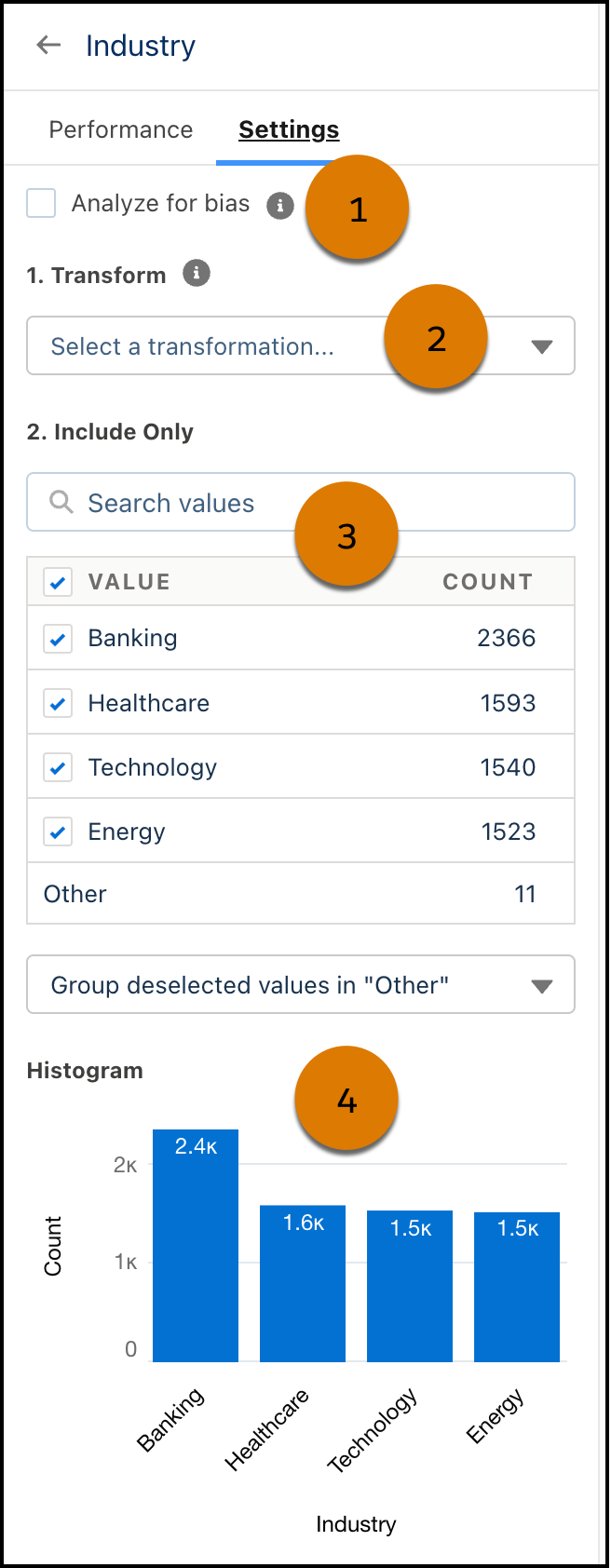
- 변수가 편차를 나타낼 수 있다고 의심되는 경우 Analyze for bias(편차 분석)(1)을 선택합니다. 그러면 Einstein Discovery의 편차 탐지 기능이 활성화됩니다. 자세히 알아보려면 Einstein Discovery로 윤리적인 모델 개발: 빠르게 살펴보기를 참조하세요.
- 분석 중에 이 변수의 값을 변환하려면 사용 가능한 Transform(변환) 옵션(2)을 선택합니다. 옵션에는 퍼지 일치, 관심도 감지, 텍스트 클러스터링, 누락 값 교체 등이 있습니다. 변환은 모델에 대해서만 데이터를 변경하고, 데이터 집합의 값은 변경되지 않습니다. 예를 들어 퍼지 일치는 텍스트 값의 작은 입력 차이(예: 철자 또는 오타)를 수정하므로, 모델이 더 정확한 범주화 및 더 나은 예측을 수행할 수 있습니다.
-
Include Only(포함만)(3)는 변수와 연관된 값을 가장 빈도가 높은 값부터 표시합니다. 값 옆의 확인란을 선택 해제하면 Einstein이 해당 값을 분석에서 생략하거나 해당 값을 ‘기타’ 그룹에 병합할 수 있습니다.
-
Histogram(히스토그램)(4)은 값이 데이터 집합에서 발생하는 빈도를 표시합니다.
모델로 수행할 수 있는 기타 작업
모델로 수행할 수 있는 지금까지의 모든 작업 외에, 다음 작업도 수행할 수 있습니다.
- 버전 내역을 확인하고 다른 버전으로 이동합니다.
- 인사이트 차트를 책갈피에 저장합니다.
- 다른 모델과 비교합니다.
- R 코드를 확인 및 복사합니다.
- 모델 이름을 변경합니다.
- 모델이 저장된 앱을 변경합니다.
- 모델을 삭제합니다.
다음 단계
이 유닛에서는 모델을 만들고 데이터 경고를 해결하고 모델의 새 버전을 만들었습니다. 다음 유닛에서는 모델을 평가합니다.
리소스