Prepare to Build Your Data Model
Learning Objectives
After completing this unit, you’ll be able to:
- Define key terms related to data ingestion and modeling.
- Identify the benefits of using Data Cloud.
Plan Ahead
It’s amazing how much data one person can generate. And how many different sources that data can come. Even a simple shopping trip can generate customer data related to sales messages, web traffic, purchases, preferences, location, and a multitude of other sources. As the data-aware specialist, you need to keep all that information organized and accessible so you can gain a more complete understanding of your customers. It’s your responsibility to make sure the data is in the right location and to create all the necessary linkage to complete your business analytics tasks.
Defining your data model can be complex. You need to understand what data is collected (and how), the existing data structure, and how that data relates to other sources. And you need to bring all of that data together into a single, actionable view of your customer. Data Cloud gives you all the tools you need to create that single view, and then engage your customers.
Before you dig into Data Cloud, do yourself a favor and grab a piece of paper, a notebook, a whiteboard, or whatever you want to doodle on. Map out a matrix of all your data sets in columns, then create rows for special considerations for each data set.
Data Sets
When establishing the columns of your matrix, consider these factors.
- Take inventory on all the data sources you might want to incorporate:
- Traditional software
- External databases
- CRM
- Ecommerce
- Data lakes
- Marketing and email databases
- Customer service
- Digital engagement data (including web and mobile)
- Analytics
- Identify all data sets required for each data source, such as ecommerce data with data sets for sales order details and sales order header data.
Special Considerations
When establishing the rows of your matrix, consider these characteristics.
- Understand the primary key (the value that uniquely identifies a row of data) of each data set.
- Identify any foreign keys in the data set. These ancillary keys in the source may link to the primary key of a different data set. (For example, the sales order details data set contains a product ID that corresponds to the item purchased. This product ID links to a whole separate table with more details about that product, such as color or size. The instance of product ID on the sales order details data set is the foreign key, and the instance of product ID on the product data set is the primary key.)
- Determine if the data is immutable (not subject to change once a record is sent) or if the data set needs to accommodate updates to existing records.
- Determine if there are any transformations you would like to apply to the data. (For example, you can use simple formulas to clean up names or perform row-based calculations.)
- Review the attributes, or fields, coming from each data source. If the same field is tracked across multiple sources, decide which data source is most trusted. You can set an ordered preference of sources later on.
- Make sure you have the authentication details handy to access each data set.
- Take note of how often the data gets updated.
From Planning Your Concepts to Building Your Model
Now that you’ve done the legwork to understand your end-to-end implementation, the rest of the work is just mechanics. As you can see in the diagram, we take a two-phased approach to bringing in data.
- Data ingestion: Bring in all fields from a data set exactly as they are without modification. That way, you can always revert back to the original shape of the data should you make a mistake or change business requirements during setup. You can also extend the data set by creating additional formula fields for the purpose of cleaning nomenclature or performing row-based calculations. Each data set is going to be represented by a data stream in Data Cloud.
- Data modeling: Map the data streams to the data model in order to create a harmonized view across sources.
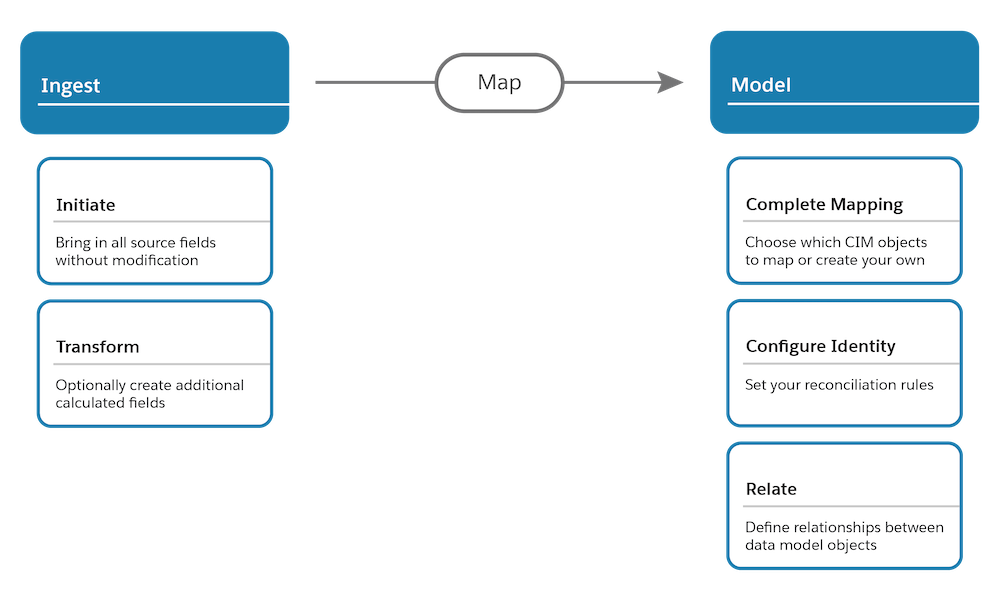
As you complete this first step of ingesting each data set, refer back to your matrix and take a look at what you determined was the source of the data set. Within Data Cloud, there is a place to write in the name of the source. Next to the source, you specify the data set that you’re bringing in from that source by filling out the Object Label and Object API Name.
Refer to the primary key of the data set in your matrix and designate that field as the primary key when defining the data source object. Did you want to enhance the data set with any additional formula fields? This is the phase where you can apply formula logic. Remember when you indicated if the data is immutable or not? Data sets with event dateTime values may be good candidates for the category of type engagement in our system. Such behavioral data sets are organized into date-based containers. When Data Cloud reads the data later on to give you segmentation counts, it knows exactly where to look in order to retrieve the information quickly.
Customer 360 Data Model
Now imagine that all your data is ingested and each data set is speaking its own language. How do we get them all to understand one another? These data sets must all conform to the same universal language in order to begin interacting with one another. That’s where the second phase, data modeling, comes in. Data Cloud utilizes a data model known as the Customer 360 Data Model.
The model consists of several objects covering a number of subject areas. Those subject areas include (but aren’t limited to) Party, Product, Sales Order, and Engagement. The model is extensible, meaning that standard objects can have custom attributes added to them and new custom objects can be created with input from you on how that new object relates to other existing objects.

You can think of the Customer 360 Data Model as a way to assign a semantic context to your source objects that everybody can understand. For example, whether you call your home a flat, a house, or a condo, you can agree that it’s a place where a person lives. Similarly, you are creating a harmonized data layer for all data sources that is abstracted away from the underlying source objects. Consider offline orders data with an order field of Salescheck_Number and online orders data with an order field of Order_ID. While these fields are distinctly named, they are both references to an Order ID. So simply tag them both in mapping as the Customer 360 Data Model reference order ID. This process removes the information from the context of the various sources and arrives at a new data layer that conforms to a single taxonomy. No matter where it comes from, your data is standardized and usable within your tasks. And that is how we make all data sets speak the same language.