세분화 살펴보기
학습 목표
이 유닛을 완료하면 다음을 수행할 수 있습니다.
- 세분화를 정의할 수 있습니다.
- 집계 및 세분화가 데이터에 미치는 영향을 파악할 수 있습니다.
세분화란 무엇인가요?
세분화는 데이터의 세밀한 정도를 의미합니다. 이전 유닛에서는 Age(연령) 변수의 모든 값이 합계로 집계된 다음 바 차트를 살펴봤습니다. 데이터는 매우 높은 수준으로 상세하지는 않으므로 세분화는 낮습니다.
바 차트에서는 전체 데이터 세트에 대한 하나의 숫자로 완전히 집계된 데이터를 보여주고 있습니다. 지터 플롯은 각 값에 대한 표식으로 완전히 분배된 데이터를 나타냅니다. 지터 플롯은 더 상세하므로 바 차트보다 세분화가 더 높습니다. 바 차트는 집계가 높고 세분화는 낮습니다. 지터 플롯은 집계가 낮고 세분화가 높습니다.
|
|
|---|


이 분배된 데이터는 모든 시각화에서 가장 높은 세분화를 제공하는 가장 높은 수준의 세부 사항을 보여 줍니다. "최저 수준의 세부 사항"은 잘 구조화된 데이터 모듈에서 다루는 유의미한 데이터의 특성 중 하나입니다.
세분화의 예
세분화를 계속 살펴보겠습니다. 비즈니스 프랜차이즈에 대한 정보가 포함된 데이터 집합을 사용하고 세분화 수준을 사용하여 데이터를 검토합니다.
이 데이터 집합에는 50,000개 이상의 행이 포함되어 있습니다. 이러한 각 행에는 단일 트랜잭션에 대한 정보가 포함되어 있습니다. 세분화가 낮을수록(집계가 높을수록) 더 큰 패턴을 볼 수 있습니다. 더 높은 세분화(더 낮은 집계)로 확대하면 패턴 이면의 세부 정보를 확인할 수 있습니다.
산점도는 수평 및 수직 축 모두에 숫자 데이터(정량적 변수)를 플로팅하여 값 간의 상관관계 또는 관계를 확인할 수 있도록 하는 차트입니다. 이 예에서는 산점도를 사용하여 비즈니스의 매출과 수익 간의 관계를 살펴보겠습니다.
두 개의 정량적 변수가 있는 산점도 보기
다음 산점도에 제시된 정량적 변수인 Profit(수익)과 Sales(매출)부터 시작하겠습니다.
이때 하나의 숫자 (판매)는 다른 숫자 (수익)에 대해 플로팅됩니다. Sales(매출) 및 Profit(수익)은 하나의 숫자(매출 합계 및 수익 합계)로 완전히 집계되므로 두 숫자는 하나의 데이터 포인트 또는 표식으로만 비교됩니다.
이 데이터는 높은 수준으로 세분화되지 않았으므로 낮은 세분화를 가집니다. 비즈니스의 수익과 매출에 대해 알아보려면 데이터가 더욱 세분화되어야 합니다.

질적 변수를 추가한 산점도 보기
산점도에 질적 변수를 추가하면 데이터의 세분화가 높아집니다.
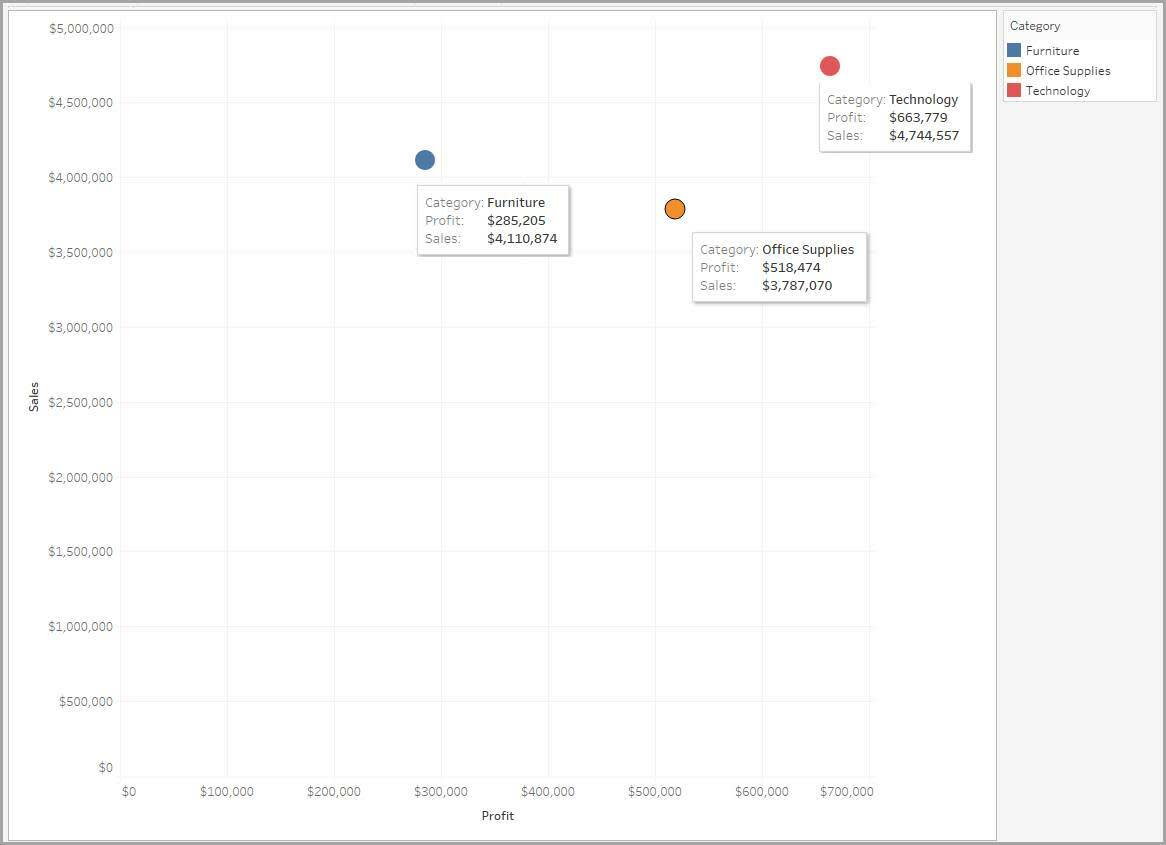
정성적 변수인 범주가 색상으로 코딩됨에 따라 데이터는 판매되는 각 제품 범주에 대해 하나씩 세 개의 표식으로 분리됩니다. 또한 단일 표식 산점도보다 더 세밀하지만 데이터를 더 자세히 보고 싶을 수 있습니다.
다음 산점도에서 범주별 수익을 살펴보세요. 가구 수익은 다른 두 기업에 비해 뒤떨어집니다. 다음 단계에서는 이러한 추세가 다양한 지리적 시장에 걸쳐 유효한지 여부를 조사하여 세분화를 추가하는 것이 합리적입니다.
두 번째 정성적 변수가 추가된 산점도 보기
다음 시각화에 Region(지역) 정성적 변수를 추가하면 모든 지리적 시장에서 가구 수익이 낮은지 여부를 알아볼 수 있습니다. 데이터 소스의 이산 지역 수에 카테고리 수를 곱하여 산점도에서 표식을 생성합니다. 따라서 13개 지역에 3개의 카테고리를 곱하여 산점도에 39개의 표식을 생성합니다.
이제 가구의 낮은 수익에 대한 잠재적 원인을 알 수 있을 정도로 데이터가 세분화되었습니다. 동남 아시아 지역은 다른 지역에 비해 가구 수익이 눈에 띄게 낮습니다. 해당 지역의 마이너스 가구 수익을 더 깊게 살펴보려면 계속해서 데이터의 세분화를 높이면 됩니다.

필터링된 데이터로 산점도 보기
동남아시아 지역의 가구 수익이 다른 지역보다 낮음을 확인할 수 있습니다. 여러분은 이러한 비수익성이 단지 한두 건의 거래 때문인지 아니면 많은 거래가 비수익적인지 알고 싶어합니다.
데이터 집합에 모든 트랜잭션에 대해 하나의 행이 포함되어 있다는 것을 알고 있습니다. 데이터가 분배되면 데이터 집합의 모든 트랜잭션에 대해 하나의 데이터 지점(또는 표식)이 표시됩니다. 그러나 이 수준으로 데이터를 분배하기 전에 데이터를 필터링하여 동남 아시아 지역의 가구에 대한 트랜잭션만 유지합니다.
다음 산점도의 경우 필터링된 데이터에는 Southeast Asia(동남아시아) 가구에 대한 표식이 단 하나 있습니다.


분배된 데이터 보기
동남아시아의 가구만 표시할 수 있도록 필터링된 데이터를 사용하면 이제 가장 높은 세분화 수준으로 데이터를 확인할 수 있습니다.
데이터를 집계하면 선택한 데이터의 모든 행의 모든 데이터 값에 대해 별도의 표식이 표시됩니다. 다음 시각화에서는 동남 아시아의 각 가구 거래에 대해 하나의 표식을 볼 수 있습니다. 이러한 방식으로 세분화 수준을 조사해 보면 동남아시아에서는 다수의 가구 판매 거래에서 수익성이 없다는 중요한 발견을 하게 됩니다.
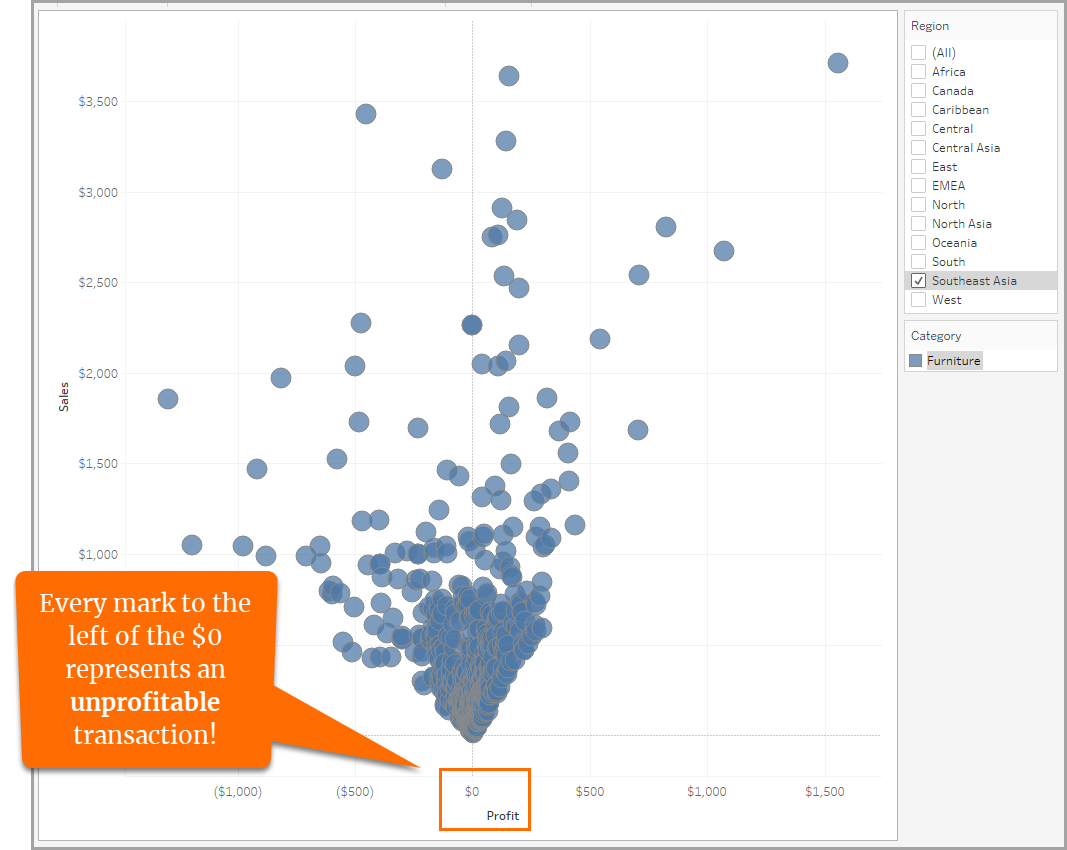
이제 사전에 정의된 집계가 데이터에 어떤 영향을 미치는지, 서로 다른 세분화 수준이 데이터 분석에 어떤 영향을 미치는지 알 수 있습니다.
리소스