推論する
学習の目的
この単元を完了すると、次のことができるようになります。
- 仮説検定の目的を説明する。
- 仮説検定における P 値の使用と制限を定義する。
概要
前の単元では、ばらつきと正規分布を使用したデータの考察、解釈、伝達に関する概念について学習しました。また、推論の例として信頼区間についても学習しました。
この単元では、引き続き推論について学習します。推論とは、データの標本 (サンプル) に基づいて、母集団に関する結論を導き出すプロセスです。これが便利なのは、ほとんどの場合、ある母集団のすべての測定値を得ることが現実的でないためです。
つまり、ある母集団の全メンバーのデータがあれば、その母集団の中のグループ間の違いについて推論する必要はありません。ですが、母集団の個々のメンバーすべてのデータを収集することができない場合には、標本 (サンプル) からデータを収集して、推論を行います。
Data Literacy, LLC の創業者兼 CEO であり、Tableau コミュニティのメンバーでもある Ben Jones 氏は、その著書『Avoiding Data Pitfalls (データの落とし穴を避けるために)』で、米国の国勢調査が 10 年に 1 度しか行われないのは、「国全体のすべての住居に住むすべての人を数えようとすると、膨大な費用と手間がかかるため」であることを指摘し、「このようなやり方は偏りや誤りの原因となりかねない」と述べています。ほとんどの組織には、米国連邦政府に匹敵するような財源や人材がないため、データサンプルを見て推論することで意思決定を行っています。
仮説検定
仮説検定はさまざまな組織で行われています。たとえば、ある製品が基準を満たしているかどうかの品質管理や新旧の販売方法の比較などに、仮説検定を利用している企業があります。
また、医学研究でもデータサンプルに基づく推論がよく行われています。バイオテクノロジー企業が、ある疾患を治療するための新薬を製造するとします。新薬の有効性を判断するには、対照実験を行う必要があります。ですが、特定の疾患を持つすべての患者を対象に実験を行うことはでできないため、一部の患者をランダムに選んで実験を行います。
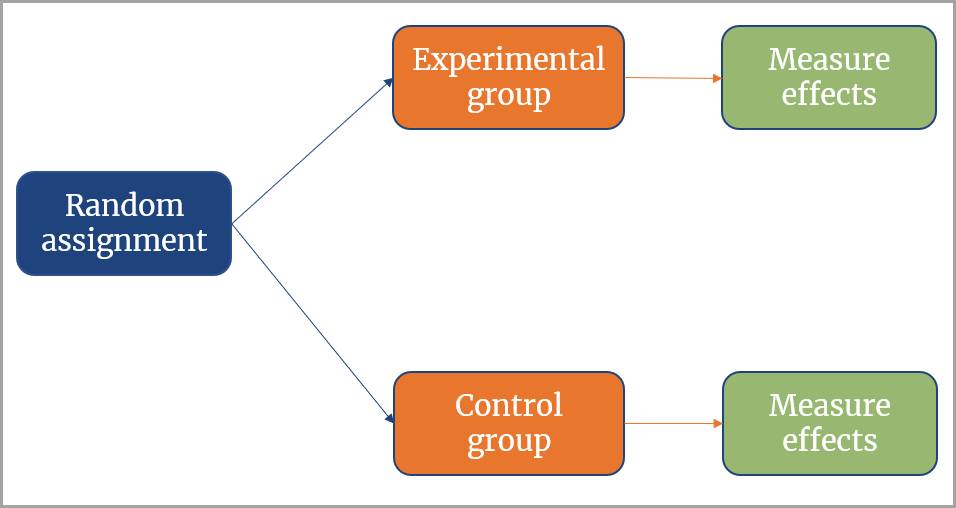
この標本 (サンプル) 内で、実験群は新薬の投与を受け、対照群は偽薬を服用します。また群はランダムに割り当てられるため、健康状態の結果の違いは研究介入に起因するものと考えることができます。
まず両方の群に対して実験が行われ、測定値を入手します。2 つの群の違いを調べる際、研究者は、実験群と対照群の結果に有意差があるかどうかを判断するために、結果がどのくらい離れているべきかを決定します。
研究者は標本 (サンプル) 群からデータを収集して、適切な統計的検定を行います。その後、このような検定結果をもとに、サンプル群間に有意差があるかどうかを判断します。データが得られたら、研究者は母集団全体、つまり、その疾患にかかっている患者全員について、推論を行う必要があります。これが仮説検定と呼ばれるものです。
仮説検定は、帰無仮説と対立仮説の設定から始まります。
- 帰無仮説は、新薬は健康上の結果に影響しない、という仮説です。投薬を受けた患者と受けていない患者の健康状態に差異は生じないと提案します。
- 対立仮説は、健康上の結果に差異が生じるという仮説です。投薬を受けた患者は、受けていない患者より健康状態に改善が見られると提案します。
仮説検定は、帰無仮説が正しいと仮定することから始まります。検定の目的は、帰無仮説が真であると仮定して、少なくとも実験と同程度の結果が観察される可能性がどれくらいあるかを判断することです。
つまり、「帰無仮説が真であれば、健康状態は改善した」という確率が低ければ、対立仮説を支持する証拠がある、ということになります。逆に、「帰無仮説が真であれば、健康状態は改善した」という確率が高ければ、対立仮説を支持する十分な証拠がないことになり、研究者は新しい式で検定をやり直す必要があります。
仮説検定は、標本 (サンプル) 数、測定された差異の大きさ、各群で観察されたばらつきの量を考慮に入れて行われます。
仮説検定の数値結果 (帰無仮説が真である確率) を p 値と呼びます。p 値は、帰無仮説を棄却するかどうかを判断するのに役立ちます。今回のケースでは、帰無仮説を棄却することは、より大きな母集団で治療が有効であることを意味します。p 値が小さい場合、帰無仮説を棄却し、対立仮説を支持するのに十分な証拠があることを示します。
ただし、注意しなければならないのは、p 値は何かを証明したり反証したりするものではない、ということです。p 値が高くても帰無仮説が有効であることの証明にはなりませんし、p 値が低くても無効であることの証明にはなりません。そのため、p 値は慎重に検討する必要があります。
p 値の使用方法
かつて、研究者は p 値 0.05 をカットオフ値とするように教えられてきました。つまり、p 値が 0.05 以下であれば、帰無仮説を棄却するのに十分だと考えられていたのです。0.05 のカットオフ値は、正規分布の裾部分に相当します。95% の信頼区間は、平均から -2/+2 標準偏差以内に収まる正規分布の領域と一致することを思い出してください。0.05 (5%) のカットオフ値は、平均から -2/+2 標準偏差以内に収まらない領域に相当しているのです。
ですが、この考え方はここ数年で見直されています。投薬実験では、カットオフ値を下げた場合 (事実上、信頼区間を 95% 以上に引き上げた場合) は、帰無仮説を棄却するのが難しくなる可能性があります。
このような理由から、米国統計協会は 2016 年に、「p 値はそれ自体では、モデルや仮説に関する適切な指標ではない」という声明を発表しました。
p 値は、分析に用いるデータの種類で操作することもできます。
ここまでで、推論、仮説検定、p 値について学習しました。こういった概念を理解することで、データを測定、説明、要約、比較し、情報に基づいた結論をデータから引き出すことがきます。
リソース
- 記事: The ASA Statement on P-Values: Context, Process, And Purpose (P 値に関する ASA 声明: 背景、プロセス、および目的)。The American Statistician、2016
- 書籍: Cairo, Alberto: The Truthful Art: Data, Charts, and Maps for Communication (真実を語るアート: コミュニケーションのためのデータ、グラフ、およびマップ)。インディアナポリス州、インディアナポリス: New Riders、2016
- 記事: Those Hurricane Maps Don't Mean What You Think They Mean (ハリケーンの地図にはあなたが思っているものと違う意味がある)。The New York Times、2019。記事のリンク
- 書籍: Jones, Ben: Avoiding Data Pitfalls: How to Steer Clear of Common Blunders when Working with Data and Presenting Analysis and Visualizations (データの落とし穴を避けるために: データ操作、分析、視覚化でよくある失敗を回避する方法)。ニュージャージー州ホーボーケン: John Wiley & Sons、2019
- Web サイト: Ben Jones 氏が運営する Data Literacy
- 書籍: Lane, David M.: Introduction to Statistics (統計学入門)。Online Statistics Education: An Interactive Multimedia Course of Study, 2020 (オンライン統計学教育: 2020 年インタラクティブマルチメディア学習指導要領)