関連ビジネスナレッジを使用したエージェントとプロンプトの拡張
学習の目的
この単元を完了すると、次のことができるようになります。
- 検索拡張生成 (RAG) によってエージェントとプロンプトテンプレートの LLM 応答の正確性と関連性が高まる理由を説明する。
- Salesforce 組織で RAG を設定して使用する方法を説明する。
検索拡張生成とは?
検索拡張生成 (RAG) は、大規模言語モデル (LLM) に対するプロンプト要求をグラウンディングする方法として人気があります。グラウンディングを行うことで、プロンプトにドメイン固有の知識や顧客情報を追加できるため、LLM はコンテキストを得て、より正確に質問やタスクに応答できます。

RAG の動作を分解すると次のようになります。
- 構造化コンテンツと非構造化コンテンツが含まれるナレッジストアから関連情報を取得します。
- この情報を元のプロンプトと組み合わせることでプロンプトを拡張します。
- 拡張されたプロンプトを使用して LLM が応答を生成します。
多くの LLM は一般公開されている静的なコンテンツを使用してインターネット上で全般的にトレーニングされています。RAG を使用すると、ドメイン固有の情報が追加され、LLM がユーザーのプロンプトに対してより適切に応答できるようになります。RAG では、サービス返信、ケース、ナレッジ記事、会話トランスクリプト、RFP (提案依頼書) 回答、メール、ミーティングメモ、よくある質問 (FAQ) など、あらゆる種類のコンテンツから有益な情報を抽出できます。
Agentforce Builder と Agentforce データライブラリを使用して Agentforce ソリューションをすばやく開始する
Agentforce Builder を使用すると、エージェントが取得できるようにするナレッジ記事の選択やファイルのアップロードを数回のクリックだけでシームレスに実行できます。これは、Agentforce データライブラリを選択または作成することで実現します。Agentforce データライブラリはエージェントが質問に答えるために使用するコンテンツのライブラリです。データライブラリの関連情報の取得元を選択します。取得元は、Salesforce 知識ベース、アップロードしたファイル (テキスト、HTML、PDF)、または Web 検索です。実行時には、エージェントはこの情報を使用して LLM プロンプトのグラウンディングを行い、より適切かつ正確で関連性の高い LLM 応答を生成します。
データライブラリを追加すると、RAG を利用した機能するソリューションに必要なすべての要素が自動的に作成されます。必要に応じて、要素をカスタマイズすることで、ユースケースに合わせて RAG ソリューションを調整できます。これについては、後で説明します。
関連するビジネス知識をエージェントに取り込む
エージェントは [Answer Questions with Knowledge (ナレッジを使用して質問に回答)] 標準アクションを使用して、関連知識をデータライブラリから取得します。このアクションは、ライブラリを作成または選択したときに指定したナレッジやファイルのコンテンツから動的に取得します。
![エージェントの詳細な RAG ランタイムフロー: [Answer Questions with Knowledge (ナレッジを使用して質問に回答)] アクション、クエリ要求と応答、拡張されたプロンプト、エージェントへの LLM 応答の転送。](https://res.cloudinary.com/hy4kyit2a/f_auto/fl_lossy/q_70/learn/modules/retrieval-augmented-generation-quick-look/augment-prompts-with-relevant-knowledge/images/ja-JP/d32a8f7490bb0fc5fbbf5ab09e38dd98_kix.xq4j81jzpuo1.png)
[Answer Questions with Knowledge (ナレッジを使用して質問に回答)] アクションが実行されるたびに次のことが行われます。
- アクションによって、関連付けられたプロンプトテンプレートが実行されます。動的なクエリを使用してレトリーバーが起動されます。
- クエリがデータライブラリを検索します。
- クエリが関連コンテンツを取得します。
- 元のプロンプトにデータライブラリから取得された情報が入力され、LLM に送信されます。
- LLM によって生成された応答がエージェントに転送されます。
関連するビジネス知識をプロンプトに取り込む
実行時に、プロンプトテンプレートがデータライブラリから関連情報を取得して LLM プロンプトのグラウンディングを行うことで、LLM 応答の正確性が向上します。カスタムプロンプトテンプレートを使用している場合、プロンプトビルダーで、リソースの追加時に選択したレトリーバーを組み込みます。カスタムレトリーバーを使用して特定のプロンプトに対する検索設定を微調整することもできます。
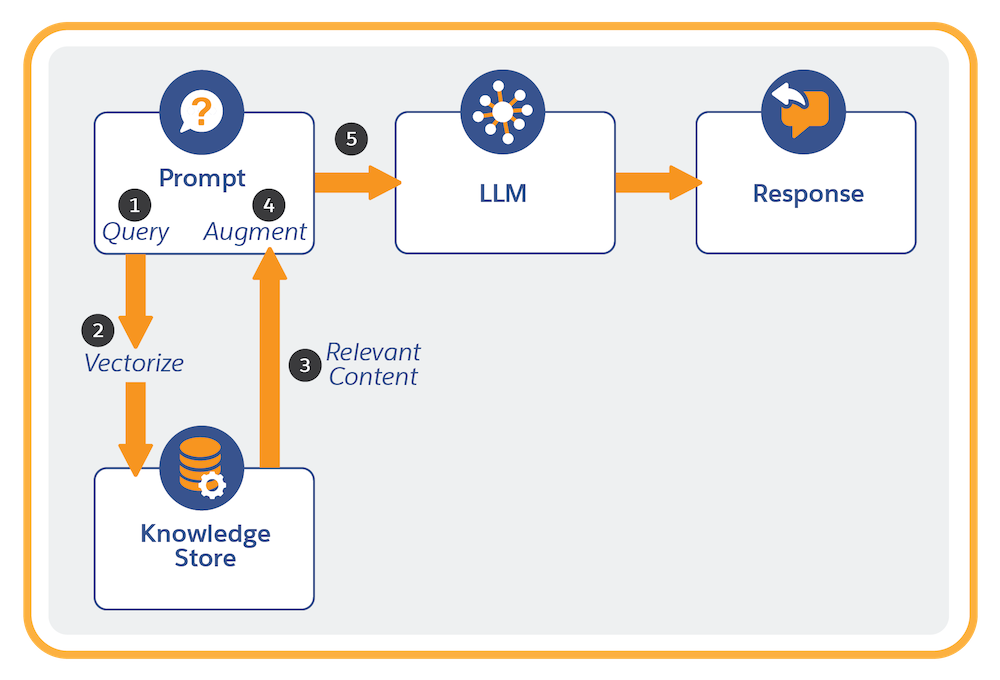
レトリーバーを含むプロンプトテンプレートが実行されるたびに次のことが行われます。
- プロンプトテンプレートから開始された動的クエリを使用してレトリーバーが起動されます。
- クエリがベクトル化されます (数値表現に変換されます)。ベクトル化を行うと、検索で検索インデックス (すでにベクトル化されています) 内の意味的な一致を見つけることができます。
- クエリが検索インデックス内のインデックス付きデータから関連コンテンツを取得します。
- 検索インデックスから取得された情報が元のプロンプトに入力されます。
- プロンプトが LLM に送信され、LLM がプロンプト応答を生成して返します。
Data 360 での高度なカスタマイズ
Agentforce Builder または [Setup (設定)] でデータライブラリを追加すると、自動的に RAG を使用したソリューションが作成されます。このソリューションではすべてのコンポーネント (ベクトルデータストア、検索インデックス、レトリーバー、プロンプトテンプレート、標準アクション) にデフォルト設定が使用されます。コンポーネントは個別に設定してカスタマイズできます。
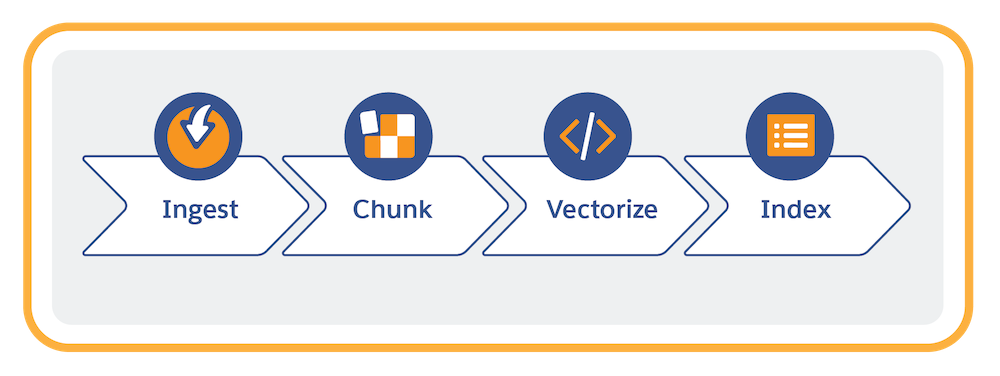
データを準備するには Data 360 で次の作業を行います。
- 非構造化データを接続 (取得) します。
- コンテンツをチャンク化してベクトル化する検索インデックス設定を作成します。Data 360 では、検索用に最適化された方法で構造化コンテンツと非構造化コンテンツを管理するために検索インデックスを使用します。検索には、ベクトル検索とハイブリッド検索という 2 つのオプションがあります。ハイブリッド検索はベクトル検索とキーワード検索を組み合わせたものです。
- チャンク化とは、テキストを分解して、元のコンテンツのパッセージを反映した小さな単位 (文や段落など) にすることです。
- ベクトル化とはチャンクをテキストの意味的な類似性を捉えた数値表現に変換することです。
- チャンク化とは、テキストを分解して、元のコンテンツのパッセージを反映した小さな単位 (文や段落など) にすることです。
- 検索インデックスを保存して管理します。
検索インデックスが作成されたら、AI モデル (旧称 Einstein Studio) で、その検索インデックスから特定のユースケースの関連情報を取得するレトリーバーを作成します。レトリーバーとは、ナレッジストアの関連情報を検索して返すためにプロンプトテンプレートに組み込むリソースです。さまざまなユースケースをサポートするために、検索を関連性の高い情報のサブセットのみに絞り込み、プロンプトに追加する多様なレトリーバーを作成できます。実際に操作して学ぶには、「Advanced RAG with Data 360 and Agentforce (Data 360 と Agentforce による高度な RAG)」モジュールを受講してください。
RAG の動作を確認する
次の動画では、RAG を使用して簡単にプロンプトテンプレートを強化できることを説明しています。
まとめ
Data 360 の Agentforce データライブラリと RAG は Einstein 生成 AI プラットフォームに統合されています。そのため、Agentforce Builder やプロンプトビルダーなどの標準アプリケーションにネイティブに RAG を組み込むことができます。RAG を使用すれば、ハーモナイズされたデータモデルからの専有データを使用して Agentforce ソリューションのグラウンディングや改善を行うことができます。
リソース
- Salesforce ヘルプ: Data 360 の非構造化データ
- Salesforce ヘルプ: Data 360 - チャンクデータ
- Salesforce ヘルプ: Data 360 - ベクトル検索
- Salesforce ヘルプ: Data 360 - ハイブリッド検索
- Salesforce ヘルプ: 例: 高度な Data 360 設定によるエージェンティック RAG
- Trailhead: Agentforce データライブラリの基礎
- Trailhead: Data 360 の非構造化データ
- Trailhead: Data 360 の検索インデックス種別: クイックルック
- Trailhead: Hybrid Search for RAG: Quick Look (RAG を使用したハイブリッド検索: クイックルック)
- Salesforce ブログ: RAG – The Hottest 3 Letters in Generative AI Right Now (RAG - 生成 AI で今もっとも注目される 3 文字)
- Salesforce ブログ: Agentforce and RAG: Best Practices for Better Agents (Agentforce と RAG: より優れたエージェントを実現するためのベストプラクティス)