人工知能のバイアスの認識
学習の目的
この単元を完了すると、次のことができるようになります。
- AI システムの開発におけるデータの役割について説明する。
- 倫理的であることと合法的であることの違いを理解する。
- AI システムに入り込む可能性のあるバイアスの種類を特定する。
- AI システムへのバイアスの進入口を見つける。
人工知能を重視する
人工知能は、人間の知能を補い、人間の能力を増強し、従業員、顧客、パートナー、そしてコミュニティにより良い結果をもたらす実用的なインサイトを提供することができます。
Salesforce では、AI の制作者だけでなく、万人がその恩恵を受けるべきと考えています。私たちは、AI の技術的な性能を提供するだけでは十分ではありません。お客様が Salesforce の AI を万人にとって安全かつ受容的な方法で使用できるようにすることに対しても重要な責任を担っています。私たちはこの責任を重要視し、AI を安全で的確かつ倫理的な方法で開発し使用するために必要なツールを従業員、お客様、パートナー、コミュニティに提供することに尽力しています。
「人工知能の基礎」で学習したとおり、AI は、コンピューターに複雑なタスクを実行し、人的行為に見えるように動作するよう教示する取り組みを表す包括的な用語です。多くの場合、このようなタスクのトレーニングには大量のデータが必要です。これにより、コンピューターがデータのパターンを学習できるようになります。このパターンから複雑なシステムを表すモデルが形成されます。これは、太陽系のモデルを作成するような場合とよく似ています。優れたモデルがあれば、優れた予測 (次回の日食の予測など) やコンテンツの生成 (海賊によって書かれた詩の作成など) を行うことができます。
モデルが特定の予測やコンテンツの生成を行う理由を私たちは常に把握しているわけではありません。『The Black Box Society』 (ブラックボックス社会) の著者である Frank Pasquale 氏は、こうした透過性の欠如をブラックボックス現象と説明しています。AI を制作する企業はシステムのバックグラウンドプロセスについては説明できますが、モデルのどこにバイアスが存在する可能性があるかなど、リアルタイムで何がどのような順序で起こっているのかを伝えるのは当の企業でも至難の業です。バイアスや公平な判断について、AI には独自の課題が生じています。
倫理的であることと合法的であることの違い
どの社会にも、市民が従う必要がある法律があります。けれども時として、倫理的なテクノロジーを開発するためには、法律を超越して考える必要のあることがあります。たとえば、米国連邦法では一定の特性が保護され、雇用、昇進、居住、貸与、医療などに関する決定において通常はこうした特性を使用することができません。保護されている分類は、性別、人種、年齢、障害、肌の色、国籍、宗教や信条、遺伝情報などです。AI モデルでこれらの特性を使用すれば、法律に違反するおそれがあります。AI モデルがこれらの特性を合法的に利用できる状況で判断を下しているとしても、これらの特性に伴うバイアスを容認することが倫理に反する場合があります。保護されている分類に関する問題は、プライバシーや合法性の領域に踏み込む可能性もあるため、GDPR のトレイルを受講して詳細を確認しておくことをお勧めします。最後に、Einstein 製品が許容される使用に関するポリシーに準じた方法で使用される場合とそうではない場合を認識しておくことも重要です。
幸いにも、AI ではバイアスに体系的な方法で対処することができます。従来、会社の意思決定で、個別の判断によってバイアスがかかった結果がもたらされたことに気付いても、プロセス全体を再設計し、この内在的なバイアスを克服することは容易いことではありませんでした。AI システムを使用する現在では、設計の段階で公平性を浸透させ、既存の実務を改善することができます。
AI モデルの法的影響や倫理的影響を慎重に検証するほか、各自のモデルが人権の尊重や促進に対するビジネスの責任と合致しているかどうかも評価する必要があります。国際人権法や、国連が定める人権尊重に対するビジネスの責任を考慮します。この指導原則には、人権への影響を評価し、その評価に基づいて行動し、影響にどのように対処しているかを報告するデューデリジェンスプロセスが記載されています。
注意すべきバイアスの種類
バイアスはさまざまな形で現れます。体系的な過誤の結果であることもあれば、社会的な偏見の結果であることもあります。この区別が曖昧な場合もあります。バイアスのこうした 2 つの根源を念頭に、バイアスが AI システムに入り込む可能性があるパターンを見ていきましょう。
測定バイアスまたはデータセットバイアス
データのラベル付けや分類が間違っていたり、データの処理がずさんだったりした場合は、測定バイアスが生じます。測定バイアスは、人がデータに間違ったラベルを付けたことで生じることもあれば、マシンの誤作動によって生じることもあります。データセット内のある特性、要因、集団が過多あるいは過少になることがあります。
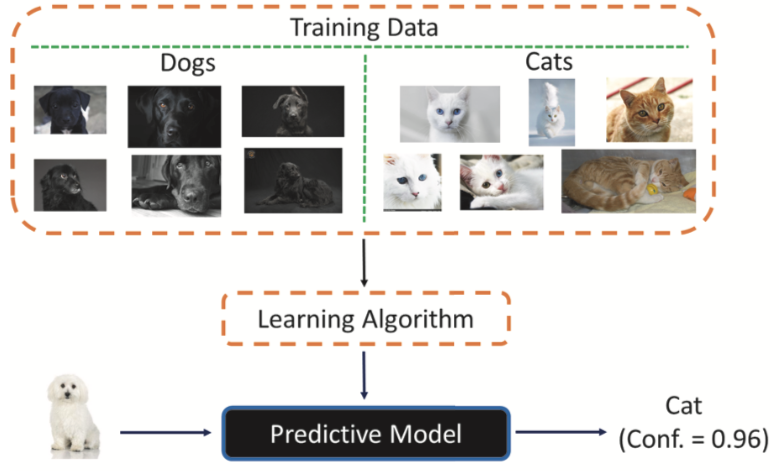
ではここで、害悪のない例として、猫と犬の画像認識システムを見てみましょう。猫や犬の写真で構成されるこのトレーニングデータは単純明快なように思われます。けれども、この画像セットは黒い犬と、白か茶色の猫の写真のみで構成されています。白い犬の写真をこの AI に提示すると、猫に分類されます。実際のトレーニングデータがこれほど単純であることは稀ですが、思いがけない結果が生じ、深刻な事態を引き起こすおそれがあります。
第 1 種過誤と第 2 種過誤
ある銀行が AI を使用して、ローン申請者が返済するかどうかを予測する場合を考えてみます。申請者がローンを返済可能とシステムが予測したのに、申請者が返済しなかった場合を偽陽性、あるいは第 1 種過誤といいます。申請者がローンを返済不能とシステムが予測したのに、申請者が返済した場合を偽陰性、あるいは第 2 種過誤といいます。銀行は、返済可能と確信できる相手に融資をしたいと考えます。リスクを最小限に抑えるために、銀行のモデルは偽陰性よりも偽陽性を避けようとします。けれども、偽陰性のケースでは、システムに返済不能と誤って判断された申請者に害悪がもたらされます。

関連付けバイアス
ステレオタイプに基づいてラベルが付けられたデータは、関連付けバイアスの例です。大半のオンライン小売業者で「女の子向けのおもちゃ」と検索すると、おままごと、人形、お姫様、ピンクのおもちゃなどが次々と表示されます。「男の子向けのおもちゃ」を検索した場合は、スーパーヒーローのアクションフィギュア、大工セット、ビデオゲームなどが表示されます。
確証バイアス
確証バイアスとは、先入観に基づいてデータにラベルが付けられることです。オンラインショッピング時に表示されるおすすめには、各人の購買習慣が反映されていますが、こうした購入に影響を及ぼすデータ自体に、そもそも人々が表示して購入を選択したものが反映されています。つまり、おすすめによってステレオタイプが増幅されます。Web サイトの「女の子向けのおもちゃ」セクションにスーパーヒーローが表示されなければ、買物客がサイトの他の場所にスーパーヒーローのおもちゃがあることを知る可能性は低く、購入する可能性はさらに低下します。
自動化バイアス
自動化バイアスは、システムの価値を他の人々に押し付けることです。2016 年に AI が審査した美人コンテストの例を見てみましょう。この目的は、客観性という概念に基づいて最も美しい女性を選び出すことでした。ところが、この AI のトレーニングには主に白人女性の画像が使用されたため、「美しい」として学習した定義には有色人種によくある特徴が含まれていませんでした。その結果、この AI が選んだ勝者のほとんどが白人となり、トレーニングデータのバイアスが実際の結果として表れることになりました。
自動化バイアスは AI だけに限りません。カラー写真の歴史を見てみましょう。1950 年代中ごろから、Kodak は写真現像室を提供していましたが、フィルムを現像する際には Shirley Page という白い肌の従業員の画像を使用して肌の色、影、光を調整していました。その後さまざまなモデルが使用されましたが、それらの画像は「Shirley カード」として知られるようになりました。Shirley が誰であっても (当初は常に白人でした)、Shirley の肌の色が標準とされました。カナダの Concordia 大学のメディア学教授である Lorna Roth はカードが最初に作成されたときについて次のように NPR に語っています。「カメラを購入する人の大半は白色人種でした。そのため、より幅広い肌の色へと市場を拡大する必要性を感じなかったのでしょう。」1970 年代には、Kodak はさまざまな肌の色でのテストを開始し、多民族の Shirley カードを作成しました。
社会的バイアス
社会的バイアスによって、歴史的にマイノリティとされてきた集団に対する過去の偏見の結果が再現されます。赤線引きについて考えてみましょう。1930 年代、連邦住宅政策では望ましさの観点で特定の地域が色分けされていました。赤でマークされた地域は危険とみなされていました。銀行では、このような赤でマークされた地域に住むマイノリティ集団への低コストの住宅融資を拒否することがよくありました。今日に至るまで、赤線引きは特定の郵便番号地域での人種や経済的な構成に影響を与えており、郵便番号と人種の相関関係が高い場合があります。モデルのデータポイントに郵便番号を含めれば、ユースケースによってはアルゴリズムの判断要因に意図せず人種を含めてしまう可能性があります。米国では、金融業務のさまざまな判断において、年齢、人種、性別など保護対象のカテゴリを使用することが違法であることを忘れないようにします。
勝ち抜きバイアス
時として、アルゴリズムが選抜された人々や、特定のプロセスを勝ち抜いた人々のみに着目し、除外された人々には目を向けないことがあります。採用の実務を見てみましょう。たとえば、あなたが会社の採用責任者で、特定の大学の卒業生の中から採用すべきかどうか判断したいとします。そこで、その大学出身の現在の従業員の業績を検討します。けれども、その大学の出身者で採用されなかった人々や、採用後に解雇された人々の業績は検討されません。「勝ち残った」人々の業績のみに目を向けることになります。

操作バイアス
人間が AI システムを操作するときや、AI システムに意図的に影響を及ぼそうとするときに、操作バイアスが生み出され、バイアスのかかった結果が生成されます。この一例が、人々がチャットボットに意図的に下品な言葉を覚えさせようとする場合です。
どのようにしてシステムにバイアスが入り込むのか?
バイアスが AI システムに入り込むルートには、商品の製作者経由、トレーニングデータ経由 (またはデータセットにデータを提供するすべてのソースに関する情報の欠如)、AI が導入される社会的状況などが挙げられます。
思い込み
ある人が特定のシステムの構築に着手する場合、何を構築すべきか、誰のために構築すべきか、どのように機能すべきか (誰からどのようなデータを収集すべきか) に対して思い込みがあることがあります。思い込みがあるからといって、システムの制作者に悪意があるわけではありませんが、私たち人間は、他の全員の経験を常に把握することや、そのシステムが他者にどのような影響を及ぼすかを予測することはできません。研究や設計プロセスの当初から多様な関係者や参加者を含めれば、商品に独自の思い込みが入り込む余地を制限することができます。また、AI システムには多様なチームで取り組むようにする必要があります。
トレーニングデータ
AI モデルにはトレーニングデータが必要で、データセットには簡単にバイアスがかかります。企業がこれまで同じ大学の同じ学部の出身者、あるいは同じ性別の応募者ばかり採用してきたのであれば、採用 AI システムはこれらの人々を最高の候補者として学習します。このシステムが、これらの条件を満たさない応募者を推薦することはありません。
モデル
AI モデルのトレーニングに使用する要因 (人種、性別、年齢など) によって、こうした特性で定義される特定の集団に対してバイアスのかかったおすすめや予測が行われる可能性があります。また、これらの特性を暗示する要因にも気を付けなければなりません。たとえば、相手の名から性別、人種、国籍が暗示されることがあります。このため、Einstein 製品のリードスコアリングや商談スコアリングモデルでは、名を要因に使用していません。
![Einstein のセールスリードと商談スコアリング。ダイアログボックスに、[Zip code has a high correlation to Race and may be adding bias into the predictive model from this story. (郵便番号は人種と相関が高いため、この情報から予測モデルにバイアスがかかる可能性があります。)] という警告が表示されています。](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/responsible-creation-of-artificial-intelligence/recognize-bias-in-ai/images/ja-JP/e59d66a7aa2303274add0d916223ec5b_1691008158828.png)
人為操作 (またはその欠如)
トレーニングデータを編集すると、モデルの動作に直接的な影響が及び、バイアスが付加されること、あるいはバイアスが取り除かれることがあります。質の悪いデータや過多のデータポイントを削除したり、ラベルを追加したり、カテゴリを編集したり、年齢や人種などの特定の要素を排除したりすることがあります。または、モデルをそのままにしておくことで、状況によってはバイアスの余地が残ることもあります。
AI システムの関係者がシステムのレコメンデーションについてフィードバックできるようにする必要があります。このフィードバックは、暗黙的である場合もあれば (システムが顧客の好きそうな書籍をおすすめしても、顧客が購入しなかった場合など)、明示的である場合もあります (顧客がレコメンデーションに「いいね!」と言った場合など)。こうしたフィードバックを基に、たった今行った動作に似たことを行うようにモデルがトレーニングされます。また GDPR に従って、EU 市民に対しては、企業が本人に関する誤った情報を保有している場合は修正することや、その会社に自分のデータの削除を依頼することができるようにする必要があります。法律で義務付けられていなくてもこうした対応をすることがベストプラクティスです。AI が正確なデータに基づいてレコメンデーションを行うようになり、また顧客の信頼が得られるためです。
AI によってバイアスが増幅される可能性
バイアスのかかったデータセットに基づいて AI モデルをトレーニングすることによって、こうしたバイアスが増幅されることが少なくありません。ある例で、写真データセットの時点では、料理に関する写真の人物が男性より女性のほうが 33% 多かったのに、アルゴリズムによってこのバイアスが 68% に増大されていました。詳細は、「リソース」セクションのブログ投稿を参照してください。