データの読み込み
学習の目的
この単元を完了すると、次のことができるようになります。
- Salesforce でデータを無駄なく読み込む利点について説明する。
- 大量データを読み込むときに SOAP API ではなく Bulk API を使用するメリットを理解する。
- データの検証および強化操作を一時的に停止して、大量データセットの読み込みプロセスを加速する。
無駄のない読み込み
LDV の移行操作でも大量データの継続的な同期操作でも、こうしたアクションがビジネスに不可欠な操作に与える影響を最小限に抑えることをお勧めします。これを実現する賢明な方法が無駄のない読み込みです。つまり、ビジネスに不可欠な操作に必要なデータおよび設定のみを読み込みます。
無駄のない読み込みですべきこと
- ユーザーを Salesforce に移行する前にビジネスに不可欠な操作を特定する。
- こうした操作を実行するために必要な最低限のデータセットおよび設定を特定する。
- 特定した要件に基づいてデータおよび設定戦略を定義する。
- データをできる限り迅速に読み込んで同期の範囲を狭める。
データの読み込みおよび設定戦略を決定するときは、次の設定オプションを検討して、重要ではないプロセスは先送りし、LDV の読み込みが迅速に行われるようにします。
組織の共有設定。「非公開」共有モデルを使用してデータを読み込む場合は、レコードの追加時に共有が適用されます。「公開/参照・更新可能」共有モデルを使用して読み込む場合は、この処理を稼働開始後まで先送りすることができます。
複雑なオブジェクトリレーション。オブジェクトに定義している参照数が多いほど、データの読み込み中にシステムが実行しなければならないチェックの数が増大します。ただし、これらのリレーションの一部を後から確立することが可能であれば、読み込みが加速します。
共有ルール。データを読み込む前に所有権ベースの共有ルールが設定されている場合、挿入するレコードの所有者が共有対象データを定義するロールまたはグループに属しているときは、レコードごとに共有を適用する必要があります。データを読み込む前に条件に基づく共有ルールが設定されている場合は、項目がルールの選択基準と一致するレコードごとにも共有を適用する必要があります。
ワークフロールール、入力規則、トリガー。この 3 つは、日常的な操作時に、入力されたデータがクリーンであることを確認し、レコード間に適切なリレーションを確立する強力なツールです。ただし、大量データの読み込み時に有効になっていれば、処理に時間がかかることがあります。
省き過ぎない
迅速なデータの読み込みを妨げる障害を取り除くことは適切ながら、次のようないくつかの設定はデータの読み込み時に欠かせず (あるいは極めて望ましく)、手を付けるべきではありません。
-
主従関係の子がある親レコード。親が存在しない場合、その子レコードを読み込むことはできません。
-
所有者。ほとんどの場合、レコードは個々のユーザーが所有します。データを読み込むためにはその所有者がシステムに存在している必要があります。
-
ロール階層。レコードの所有者がロール階層のメンバーでないほうが読み込みが迅速に行われると思うかもしれません。ただし、ほぼすべての場合でパフォーマンスに違いはなく、ポータル取引先を読み込んでいる場合は著しく加速します。したがって、設定のこの側面を先送りしてもメリットはありません。
Bulk API と SOAP API のデータの読み込み
LDV を読み込む場合、どの API を選ぶかによっても結果が異なります。標準の SOAP API は、一度に少数のレコードを更新するリアルタイムのクライアントアプリケーション向けに最適化されています。SOAP API では、開発者とシステム管理者はデータを小分けにしてアップロードし、結果を監視して、失敗したレコードを再試行する複雑なプロセスを実装する必要があります。これは小規模なデータの読み込みでは許容できますが、大規模なデータセットの場合は厄介で時間がかかります。
一方 Bulk API は、数千件から数百万件のレコードからのデータを簡単に処理するよう設計されています。REST の原則に基づく Bulk API は特に、大規模なデータセットを読み込んだり削除したりするプロセスの簡略化および最適化を目的に開発されています。
LDV に Bulk API を使用すると、超速処理が可能になるほか、クライアント側のプログラム言語の減少、ジョブの状況の簡便な監視、失敗したレコードの自動的な再試行、並列処理のサポート、往復回数の最小化、API コールの最小化、接続切断の制限、バッチサイズの容易な調整が可能になります。端的に言えば、レコードを最も簡単に挿入、クエリ、削除する方法です。
Bulk API のしくみ
Bulk API を使用してアップロードされたレコードはストリーミングされ、新しいジョブが作成されます。ジョブにデータが取り込まれると、一時的なストレージに保存された後、ユーザー定義のバッチに分割されます (最大レコード数は 10,000 件)。データがサーバーに送信中でも、プラットフォームがバッチを処理に送信します。
バッチは、必要に応じて並列的にも逐次的にも処理できます。Bulk API によって機能および作業がクライアントアプリケーションからサーバーに移されます。そして、各ジョブの状況をログに記録し、失敗したレコードの再処理を自動的に試行します。ジョブがタイムアウトすると、Bulk API が自動的にキューに戻し再試行します。
どのバッチも独立して処理され、バッチが終了 (正常でも失敗でも) した時点で、ジョブの結果が更新されます。適切なアクセス権があれば誰でも、Salesforce.com 管理 UI を使用してジョブを監視および管理できます。
イベントの一時停止による加速
LDV をすばやく読み込む必要がある場合の重要な点は、各挿入をできる限り効率的に行うことです。事前準備と後処理を適切に行えば、読み込み中のデータの検証操作や強化操作を無効にしても、データの整合性が損われたり、ビジネスルールから外れたりすることがありません。
プラットフォームはユーザーが入力したデータがクリーンであることを確認するツールを備え、レコード間に適切なリレーションを確立します。入力規則は、ユーザーが新規および既存のレコードに入力したデータが、ビジネスで指定されている標準を満たしていることを確認します。ワークフロールールを使用すると、ワークフロー、承認、マイルストーンに関連付けられている項目自動更新、メールアラート、アウトバウンドメッセージ、ToDo を自動化できます。トリガーを使用すると、レコードの挿入時にデータを操作したり、ほかのアクションを実行したりすることができます。
通常の操作時はこれらのツールを使用してデータの整合性を確保しますが、大量データの読み込み中に有効にすれば、挿入に著しく時間がかかることがあります。ただし、検証、ワークフロー、トリガーを無効にしたら、読み込みが完了した時点で、入手したデータが正確で、オブジェクト間に適切なリレーションが確立されていることをどのように確認するのでしょうか? この作業は主として、データの分析および準備、読み込みのためのイベントの無効化、後処理という 3 つのフェーズで構成されます。
データの分析および準備
トリガー、入力規則、ワークフロールールを使用せずに安全な読み込みを実施するには、普段はこれらの操作を使って満たしているビジネス要件を検証して、次の数点を自問します。
1 つ目は、「データの読み込み前のデータの整理によって、あるいはオブジェクト間に重要な連動関係が存在する読み込み操作のシーケンス処理によって満たすことができるビジネス要件はどれか?」です。たとえば、普段は入力規則を使用してユーザー入力が有効な範囲内であることを確認している場合、読み込む前にデータセットを照会して、規則に適合していないレコードを見つけて修正することができます。
2 つ目は、「データの読み込み後のレコードの後処理で満たすことができる要件はどれか?」です。この場合の一般的な使用事例はデータ強化に関連し、オブジェクト間の参照関係、親レコードへの積み上げ集計項目、レコード間のその他のデータリレーションの追加を含むことが考えられます。
読み込みのためのイベントの無効化
データの検証および強化の要件をすべて分析し、データの読み込み前または後に実施するアクションを計画したら、読み込みを加速するためにルールやトリガーを一時的に無効にできます。各ルールを編集して、「無効」状態に設定するだけです。入力規則、リードやケースの割り当てルール、テリトリーの割り当てルールも同じ要領で無効にできます。
トリガーを一時的に無効にする方法はやや複雑で、一定の準備が必要です。最初に、トリガーを実行すべき時点を制御するカスタム設定と対応するチェックボックス項目を作成します。次に、以下の例で強調表示されているようなステートメントをトリガーコードに追加します。
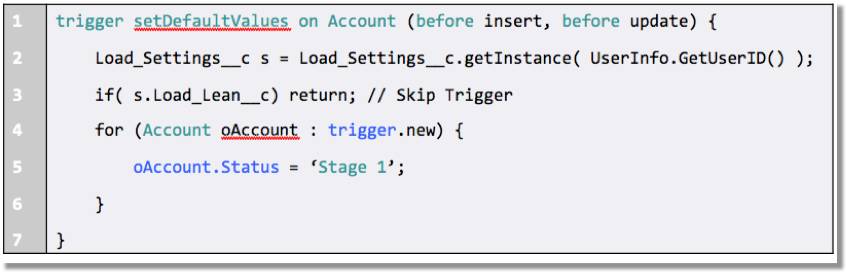
ここまで済んだら、トリガーを無効または有効にしますが、これはチェックボックス項目の編集と同じぐらい簡単に行えます。
後処理
データの読み込みが終了したら、この時点まで先送りしていたデータ強化および設定の作業を行います。
- Apex の一括処理または Bulk API を使用して、オブジェクト間の参照関係、親レコードへの積み上げ集計項目、レコード間のその他のデータリレーションを追加します。
- Apex の一括処理または Bulk API を使用して、Salesforce 内のレコードを外部キーまたはその他のデータで強化し、ほかのシステムとのインテグレーションを促進します。
- トリガー用に作成したカスタム設定の項目をリセットして、レコードの作成時および更新時に適切に実行されるようにします。
- 入力規則、ワークフロールール、割り当てルールを有効にして、ユーザーがレコードを入力および編集したときに適切なアクションがトリガーされるようにします。
つまり、無駄なく読み込みし、Bulk API を使用して、イベントを一時的に停止すれば、データの読み込みを効率的でできる限り迅速なものにする一方で、整合性も保つことができます。データの読み込みの説明が終わったところで、データの削除および抽出に関する次の単元に進みましょう。

リソース
- Salesforce 開発者: Bulk API 開発者ガイド
- Salesforce 開発者: Extreme Force.com Data Loading, Part 2: Loading into a Lean Salesforce Configuration (Force.com の極端なデータの読み込み、パート 2: Salesforce の無駄のない設定への読み込み)
- Salesforce 開発者: Extreme Force.com Data Loading, Part 3: Suspending Events that Fire on Insert (Force.com の極端なデータの読み込み、パート 3: 挿入時に実行されるイベントの一時停止)
- Salesforce 開発者: Extreme Force.com Data Loading, Part 4: Sequencing Load Operations (Force.com の極端なデータの読み込み、パート 4: 読み込み操作のシーケンス処理)
- Salesforce 開発者: Extreme Force.com Data Loading, Part 5: Loading and Extracting Data (Force.com の極端なデータの読み込み、パート 5: データの読み込みおよび抽出)