モデルを評価する
学習の目的
この単元を完了すると、次のことができるようになります。
- モデルの概要とその生成方法について説明する。
- モデルメトリクスを使用してモデルの品質を理解する理由を説明する。
モデル、変数、観測
このモジュールでこれまでに学んだ内容を復習しておきましょう。モデルは、過去の結果に対する包括的かつ統計的な理解に基づくカスタムの高度な数学的構造です。Einstein Discovery でデータを基にモデルが生成 (トレーニング) されます。Einstein はこのモデルを使用して診断的インサイトと比較インサイトを生成します。モデルを本番にリリースすると、そのモデルを使用してライブデータに対する予測と改善点を導出できます (後ほど詳しく説明します)。をクリックした後に印刷できます。
変数
では、モデルの詳細を見ていきましょう。まず、モデルでは変数を使ってデータが整理されることを押さえておきます。変数とはデータのカテゴリです。CRM Analytics データセットの列や Salesforce オブジェクトの項目に似ています。モデルには入力 (予測変数) と出力 (予測) の 2 種類の変数があります。
観測
予測は観測レベルで行われます。観測とは構造化されたデータセットです。CRM Analytics データセットの入力済みの行や Salesforce オブジェクトのレコードに似ています。
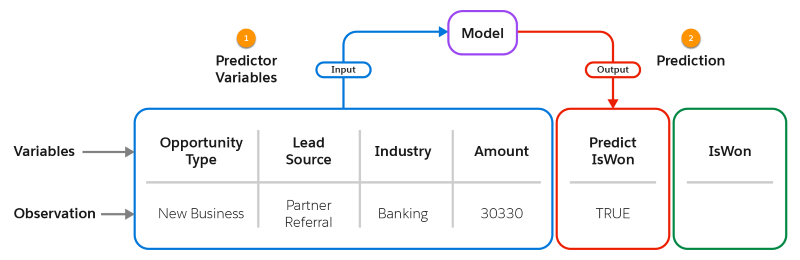
観測ごとに、モデルが 1 つの予測変数セット (1) を入力として受け入れ、対応する予測 (2) を出力として返します。要求に応じて、モデルが上位の予測因子や改善を返すこともあります。この図では、実際の結果 (IsWon) はまだ不明です。
モデルの蔓延
モデルは Einstein Discovery や Salesforce 独自のものではありません。実際、予測モデルは世界中のさまざまな業種、組織、分野で広く使用されていて、日常生活の非常に多くの側面に関わっています。優秀なデータサイエンティストやその他の専門家が、正確で有用な予測を生成する高品質なモデルの設計と構築に取り組んでいます。
ただし、多くの組織にとっての共通の課題は、精巧に作られたモデルを構築後に本番環境に実装し、対象となる業務にシームレスに統合するのが難しいということです。Einstein Discovery を使用すると、モデルを短時間で運用可能にすることができます。モデルを構築し、本番にリリースしたら、すぐにライブデータを使用して予測を取得し、より適切なビジネス判断を下すことができます。外部で構築されたモデルを Einstein Discovery にアップロードして運用可能にすることもできます。
適切なモデルとは?
モデルが生成する予測を基にビジネス判断を下すのであれば、結果の予測力が高いモデルが必要になります。最低でも、モデルが存在しないため、データではなく、臆測に頼って判断するしかない場合よりも高い確率で結果を予測するモデルが望まれます。
では、何をもって適切なモデルとされるのでしょうか? 概して適切なモデルとは、結果の改善目標の達成に向けて、ソリューションの要件を満たす十分な精度の予測を生成するものです。具体的には、モデルの予測結果が実際の結果とどのくらい一致するかで判断します。
モデルの予測精度を判断するために、Einstein Discovery にはモデルのパフォーマンスの一般的な測定値を視覚化するモデルメトリクスが用意されています。(データサイエンティストの言うところの適合度統計で、モデルの予測が実際のデータとどの程度適合しているか定量化するものです。) モデルは現実世界に似せた抽象実体であるため、どのモデルも多かれ少なかれ不正確です。実際、「完璧」なモデルには疑念を抱くべきで、望ましいものではありません (この点は後ほど説明します)。
モデルについて考えるときは、George Box という統計学者の頻繁に引用される名言、「どのモデルも間違っているが、一部のモデルは役に立つ」ぐらいにとらえるとよいかもしれません。
では、各自のモデルがどのくらい有用なのか見ていきましょう。
モデルのパフォーマンスを確認する
Einstein Discovery では、モデルのパフォーマンスからモデルの品質に関する測定値と関連する詳細が明らかになります。モデルのパフォーマンスで、モデルによる結果の予測力を評価できます。モデルのパフォーマンスメトリクスは、モデルのトレーニングに用いた CRM Analytics データセットを使って計算されます。データセットの観測に既知の (観察されたまたは実際の) 結果がある場合、Einstein Discovery がその観測ごとに予測を計算し、予測結果を実際の結果と比較してその精度を判断します。
重要: Einstein Discovery には、自動的に作成されたモデルを説明するさまざまなメトリクスが用意されています。実際のところ、多すぎてこのモジュールで説明しきれないほどです。けれども心配はいりません。このすべてどころか大半は覚えておく必要がありません。ここでは、極めて重要なもののみを取り上げます。
ありとあらゆるメトリクスが揃っている Einstein Discovery では、多様な視点からさまざまな方法でパフォーマンスを評価できるため、モデルが完全に透過的なものになります。そのため、各自のソリューションに最も適したメトリクス (この単元で取り上げないものを含む) を使用してモデルの品質を評価できます。
また、Einstein Discovery では、こうした計算に伴うニュアンスや数学をすべて理解していなくても、メトリクスを解釈できるようになっています。この単元で取り上げない特定の評価指標や画面の詳細に関心がある方は、情報バブル  をクリックするか、「詳細はこちら」
をクリックするか、「詳細はこちら」 ![[詳細はこちら] リンク](https://res.cloudinary.com/hy4kyit2a/f_auto/fl_lossy/q_70/learn/modules/einstein-discovery-basics/evaluate-a-model/images/ja-JP/69ba8a9ec6db68b618a206b47ac9b1ee_kix.l7wihbim0p6u.png) を確認してください。
を確認してください。
モデルのパフォーマンスの概要
モデルのパフォーマンスは、モデルを開いたときに最初に表示されるページです。この情報からモデルの品質を評価します。
![バイナリ分類モデルのモデルメトリクスの [概要] 画面](https://res.cloudinary.com/hy4kyit2a/f_auto/fl_lossy/q_70/learn/modules/einstein-discovery-basics/evaluate-a-model/images/ja-JP/03418ffbb23a9916e602924ddd232d12_kix.2v2hfdb2l0go.png)
メモ: 数値とバイナリ分類のユースケースではモデルメトリクスが異なります。このモジュールでは、isWon を最大にするバイナリ分類ユースケースのモデルメトリクスを中心に説明します。
左側のパネル (1) に次の要素が表示されます。
- [モデル] セクションへのナビゲーション
- データインサイトとブックマーク
- 他のアクションへのリンク
[リリースへのパス] パネル (2) には次の要素が表示されます。
-
モデルの精度を確認: バイナリ分類ソリューションの場合、モデル品質を評価するデータサイエンティストが最初に目を向けるのが曲線下面積 (AUC) です。私たちの目標は、AUC を 0.5 (偶然の確率) より大きく、1.0 (完璧な予測で、通常はデータ漏洩の問題が示唆される) より小さくすることです。このモデルの AUC 値は 0.8183 で、良好な範囲にあります。
メモ: 数値モデルの比較可能なメトリクスは R^2 です。R^2 は結果の変動を説明する回帰モデルの予測力を測定します。R^2 の範囲は 0 (偶然) から 1 (完璧なモデル) です。一般に、R^2 が大きいほど、モデルで結果を予測する精度が高くなります。
-
しきい値を設定: バイナリ分類モデルにおけるしきい値は、0 ~ 1 の予測スコアに基づいて予測が true と false のどちらに分類されるかを決定する値です。この例では、予測スコアが 0.4954 以上の場合は予測結果が true になります。しきい値についての詳しい説明はこのモジュールの範疇を超えていますが、 しきい値が、各自のソリューションの要件に応じて、モデルで結果を判別できるように調整するものということを知っておけば十分です。
-
リリース準備状況を評価する: Einstein Discovery ではモデル品質チェックを実行して、検出された問題をここに表示します。この例では、前の単元で問題を解決済みのため、データアラートはありません。
[トレーニングデータとモデル] パネル (3) には次の要素が表示されます。
-
結果変数の分布: トレーニングデータで観測された TRUE 値と FALSE 値 (実際の結果) の合計数が示されます。
-
上位の予測因子: 結果との相関関係が最も高い予測変数が表示されます。このサンプルデータでは、相関関係が最も高いのは商談種別で、業種がそれに続いています。
予測検査
[予測検査] タブをクリックします。
![モデルの [予測検査] 画面](https://res.cloudinary.com/hy4kyit2a/f_auto/fl_lossy/q_70/learn/modules/einstein-discovery-basics/evaluate-a-model/images/ja-JP/ff5aebb1791a421c407edbd60004d08d_kix.8o47zfvjtzc2.png)
右側の [Einstein 予測] パネルには、トレーニングデータの選択した行について、予測結果と実際の結果の比較と、予測結果に寄与した上位の要素が示されます。任意の行をクリックするとこのパネルが更新されます。
この画面は試運転のようなもので、リリース後のモデルが結果をどのように予測するかをプレビューできます。AUC がモデルの全般的な統計値を示すのに対し、この画面ではモデルの予測をドリルダウンしてインタラクティブに分析できます。
メモ: Einstein Discovery ではデータセットのデータを無作為に抽出するため、画面のデータがこのスクリーンショットと異なることがあります。
予測と改善を検証する
次に、Einstein Discovery の機能を活用して、将来を予測します。このセクションでは Einstein に働いてもらいましょう。シナリオを選択すると、Einstein によって統計的に可能性が高い将来の結果が計算され、結果を改善するための提案が表示されます。
メモ: この単元ではモデルを使用して what-if 予測と改善を調べる方法について説明します。モデルを Salesforce にリリースして現在のレコードについての予測と改善を得る方法については後で学習します。
左のナビゲーションパネルで、[予測] をクリックします。
![[予測] が強調表示されている左サイドバーのナビゲーション](https://res.cloudinary.com/hy4kyit2a/f_auto/fl_lossy/q_70/learn/modules/einstein-discovery-basics/evaluate-a-model/images/ja-JP/9c8a0012f906a7c8805bfa313fa951b2_kix.yl9cnibrutd0.png)
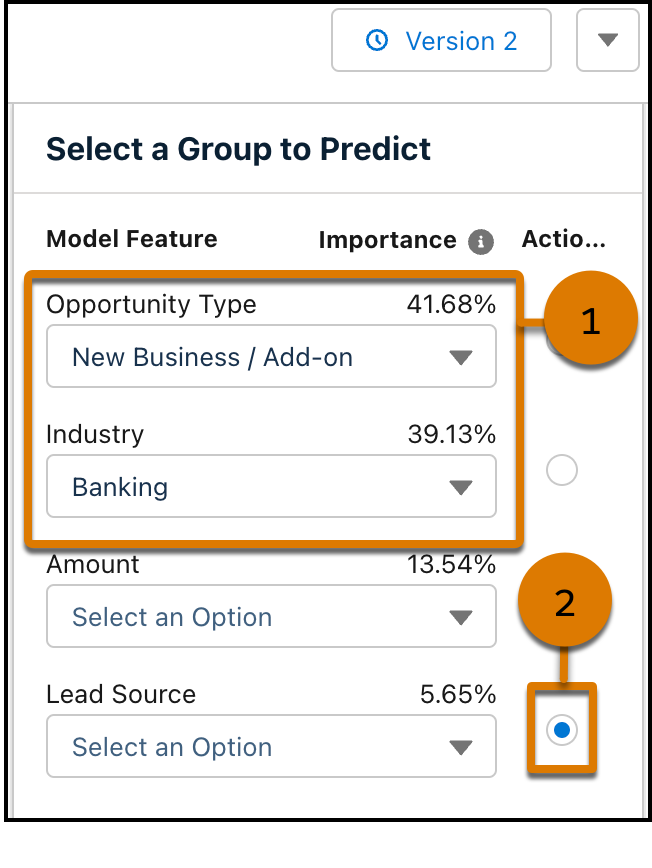
右側のパネルでモデルへの入力を選択します。
![モデルへの入力を選択する [予測するグループを選択] パネル](https://res.cloudinary.com/hy4kyit2a/f_auto/fl_lossy/q_70/learn/modules/einstein-discovery-basics/evaluate-a-model/images/ja-JP/4ef23d8411a264ae81db055b044865a6_kix.vr42tzces6bn.png)
[予測するグループを選択] で、[商談 種別] に [Business / Add On (新規商談/追加商談)] を選択し、[業種] に [銀行] (1) を選択します。[リードソース] (2) の横にある [アクション可能] ボタンを選択すると、改善点を確認できます。
メインページに以下のパネルが表示されます (すべてを表示するためにスクロールダウンしなければならないことがあります)。
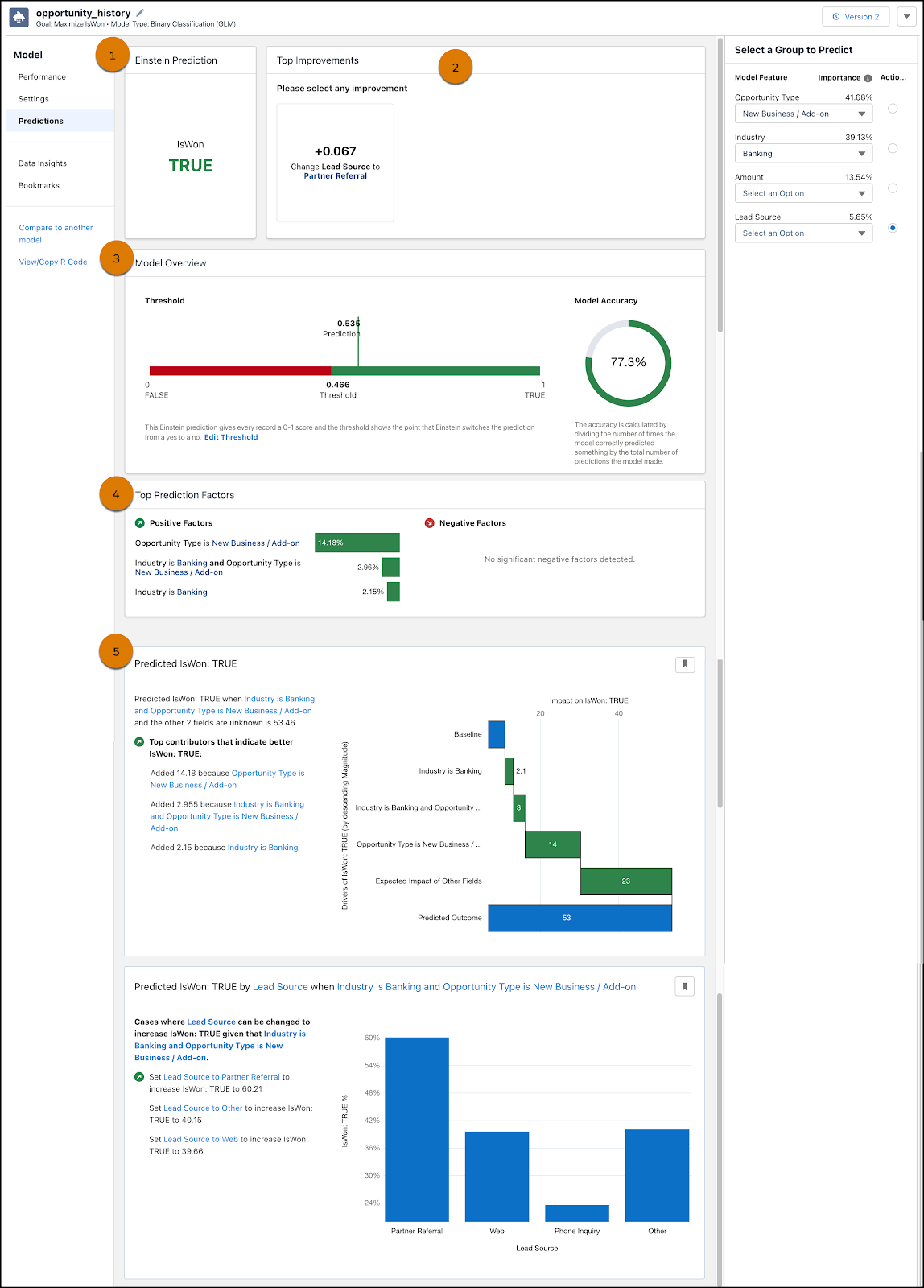
-
[Einstein 予測] (1) に、選択した内容の予測スコアが表示されます。この例の予測結果は [IsWon: TRUE] です。
-
[上位の改善点] (2) には、予測結果を改善するために実行可能な推奨アクションが示されます。この例では、商談のリードソースをパートナー紹介に変更すると予測結果が 0.067 改善します。
-
[モデルの概要] (3) には、モデルの品質のメトリクスが示されます。
-
[上位の予測要素] (4) には、予測結果と最も強く関連している説明変数 (肯定的と否定的) が示されます。この例では、商談種別が「新規商談/追加商談」の場合は予測結果が 14.18% 改善します。
-
[インサイト] (5) には、選択した内容に関連する追加のインサイトが示されます。
次のステップ
モデルの評価を終えたところで、次はデータインサイトを見ていきます。
リソース