データ処理エンジンを知る
学習の目的
この単元を完了すると、次のことができるようになります。
- 販売予測に使用できる定義済みデータ処理エンジンテンプレートとその用途を挙げる。
- 販売予測のためにデータ処理エンジンによって組織のデータがどのように変換されるかを説明する。
- データ処理エンジンテンプレートをコピーする。
- DPE ビルダーとそのさまざまな要素を知る。
- DPE 定義をカスタマイズするための 2 つの方法を比較する。
テンプレートについて
Cindy は提供される DPE テンプレートについて復習します。高度な取引先販売予測には 4 つの DPE テンプレートが付属しており、それぞれが販売予測ライフサイクルの異なるタイミングで使用されます。
データ処理エンジンテンプレート |
機能 |
|---|---|
取引先販売予測を生成 |
販売予測セットに基づいて取引先の最初の販売予測を生成します。 販売予測セットに対して初めて販売予測を生成するときには、この定義を使用します。 |
取引先販売予測を再計算 |
期間内の最新の販売予測値を計算します。 Rayler Parts の場合、この定義は毎月実行されます。また、新しい商品が導入された場合などの臨時の計算にもトリガーできます。 |
取引先販売予測をロールオーバー |
新しい期間の販売予測を生成します。 各月の末日に、販売予測表示がロールオーバーされて最初の期間の販売予測が期限切れとなり、新たな期間が表示に追加されます。 |
取引先販売予測を再生成 |
既存の販売予測レコードを期限切れにして、新しい販売予測を作成します。 販売予測セット設定を編集した場合やディメンションと期間グループを変更した場合には、この定義を実行して、更新後のパラメーターに基づいて販売予測を生成します。 |
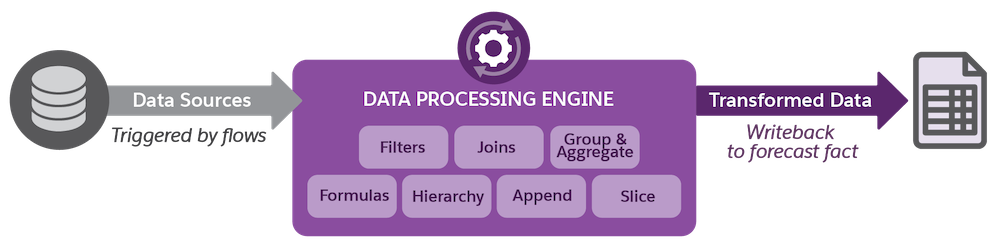
DPE を使用してデータを変換する
Cindy は Rayler Parts のビジネス要件に固有の定義を作成したいと考えているため、DPE テンプレートをコピーして、コピーをカスタマイズします。その後、スケジュール済みフローを使用して定期的に定義を実行できます。定義によって、定義のノードで指定されたロジックに基づいて販売予測値が計算されます。計算後の値は高度な取引先販売予測結果の新規レコードまたは更新レコードとして書き戻されます。最後に、各取引先の販売予測値を表示するために、販売予測セット設定が適用されます。
例を使ってわかりやすく説明します。Cindy が販売予測セット内で販売予測頻度とロールオーバー頻度を毎月と定義したとします。次に彼女は [Recalculate Account Forecast (取引先販売予測を再計算)] DPE 定義を毎月実行するジョブをスケジュールするためにフローを作成します。このフローによって DPE ジョブがトリガーされ、販売予測定義が作成されます。DPE ジョブの実行時に何が起きるかを詳しく見てみましょう。
[Recalculate Account Forecast (取引先販売予測を再計算)] DPE ジョブでは、注文、商談、販売計画、その他のデータソースのすべての新しいデータが入力として扱われます。次に、変換 (ディメンション別のグループ化や集計など) が適用され、最後にデータが高度な取引先販売予測オブジェクトに書き戻されます。DPE 定義が参照される販売予測セットの表示仕様によって、販売予測で取引先マネージャーに何が表示されるかが決まります。実際の販売予測データは高度な取引先販売予測セットパートナーレコードで参照できます。
前述のとおり、高度な取引先販売予測パートナーセットは高度な取引先販売予測セットと取引先の連結を表します。そこには販売予測グリッドに表示される販売予測データが保持されます。そのため、たとえば販売予測セット X で取引先 1、2、3 の販売予測設定が指定されている場合、パートナーセットレコードは X1、X2、X3 などの一意の組み合わせになります。
DPE テンプレートのコピー
Cindy は [Generate Account Forecast (取引先販売予測を生成)] テンプレート定義をコピーし、コピーを保存します。このテンプレートを使用して、Rayler Parts の取引先マネージャーが求めていたカスタマイズを試します。詳細は「データ処理エンジンテンプレートのコピー」を参照してください。
[Generate Account Forecast (取引先販売予測を生成)] テンプレートをコピーしたことで、Cindy はすでに機能している内容を損なうことなく新しい定義を更新できます。すべてのノードとそのオブジェクトおよび項目はコピーによって引き継がれるため、Cindy がゼロから作成する必要はありません。
DPE ビルダーのツアー
Cindy はビルダーを開いて、何ができるかを確認します。
- ヘッダー (1): 定義の名前、API 参照名、説明、プロセス種別を編集できます。
- クイックアクション
-
有効化 (2): データ処理エンジン定義を実行するには、それを有効化します。有効化済みのデータ処理エンジン定義を編集するには、まず無効化します。
-
別名で保存 (3): データ処理エンジン定義のコピーを作成します。
-
保存 (4): すべてのノードを定義したら、定義を保存します。
- 左側のパネルのタブ
-
ノード (5): 定義に追加するすべてのノードが表示されます。
-
入力変数 (6): 定義するすべての入力変数が表示されます。入力変数は、検索条件および数式種別ノードで使用されます。
- 左側のパネルのアクション
-
新規ノード (7): ノードを作成し、その種別を指定します。
-
新規入力変数: 入力変数を作成します。
-
ノードを検索 (8): ノードと変数をその名前と説明で検索します。
- 空白のキャンバス: ノードまたは入力変数を作成したら、ここでその詳細を定義できます。

JSON か UI か?
データ処理エンジン定義は次の 2 つの方法で編集できます。
- JSON ファイルとして
- ビルダーでノードをトラバースする
Cindy は両方の方法を理解してから、どちらが自分の要件に適しているかを決めたいと考えています。
各 DPE 定義は JSON ファイルとして編集できます。ビルダーで使用できるアクションは次の 2 つです。
-
 既存の定義を JSON ファイルとしてローカルシステムにダウンロードする。
既存の定義を JSON ファイルとしてローカルシステムにダウンロードする。
-
 変更した JSON ファイルをローカルシステムからアップロードする。
変更した JSON ファイルをローカルシステムからアップロードする。
JSON ベースの方法は次のような状況に適しています。
- 同じ項目を複数のノードに追加する必要がある場合。
- 同じ項目が参照されている複数のノードからその項目を削除する必要がある場合。
- 同じ項目が参照されている複数のノードでその項目の別名を変更する必要がある場合。
手順についての詳細は、「JSON ファイルでのデータ処理エンジン定義の作成または編集」を参照してください。
DPE 定義はビルダーでノードをトラバースすることによっても編集できます。各ノードの詳細の下部にあるハイパーリンクを使用すると、参照構造内の次のノードに移動できます。ノードが複数の下流ノードで参照されている場合、ハイパーリンクには参照ノードの数とリストが表示されます。

つまり、特定のノードがソースノードとして使用されているノードのリストをすばやく見つけることができます。[データソース] などの最上位ノードから始めて、最後の書き戻しノードに到達するまで参照ノードの経路を辿ります。
この方法は次のような状況に適しています。
- 項目の追加時にたどるべきノードのパスが不明で、すべてのノードを更新する必要はない場合。
- 変更がごくわずかか、他のノードに影響しない程度の場合。
- 計画が記述されており、ビルダーで変更を視覚化する方が簡単である場合。
これで Cindy はデータ処理エンジンビルダーの使用方法を理解できました。彼女は Manufacturing Cloud で DPE がどのように機能するかについての知識には自信があります。次の単元では、Cindy と一緒にデータ処理エンジン定義のカスタマイズに関するその他のいくつかのベストプラクティスやガイダンスについて学習しましょう。
リソース