AI のテクニックと用途を調べる
学習の目的
この単元を完了すると、次のことができるようになります。
- AI の実践的なユースケースを特定する。
- AI モデルや ChatGPT の制限を挙げる。
- AI のデータライフサイクルと AI アプリケーションにおけるデータのプライバシーおよびセキュリティの重要性について理解する。
人工知能テクノロジー
人工知能は、機械が学習して人間のように思考できるようにするための広範囲な学術分野です。AI には多くのテクノロジーがあります。
-
機械学習は、さまざまな数学アルゴリズムを駆使して、データからインサイトを取得し、予測を行います。
-
深層学習は、ニューラルネットワークと呼ばれる特別なアルゴリズムを使用して、入力と出力のセットの間で関連性を見つけ出します。データ量の増加に伴って深層学習の有効性と効率性が向上します。
-
自然言語処理は、機械が人間の言葉を入力として受け入れて適切なアクションを実行できるようにするテクノロジーです。
-
大規模言語モデルはテキストを人間のように理解したり生成したりするように設計された高度なコンピューターモデルです。
-
コンピュータービジョンは、機械が視覚情報を解釈できるようにします。
-
ロボティクスは、機械が物理的タスクを実行できるようにするテクノロジーです。
詳細は、Trailhead の「人工知能の基礎」モジュールを参照してください。
機械学習 (ML) は、学習アプローチや解決する問題の本質に基づいていくつかの種類に分類されます。
-
教師あり学習: この機械学習アプローチでは、モデルはラベル付けされたデータから学習し、見つけ出したパターンに基づいて予測を行います。そして、トレーニングで学習したパターンに基づいて予測を行ったり、新しい見えないデータを分類したりできるようになります。
-
教師なし学習: モデルは、ラベル付けされていないデータから学習し、事前定義された出力なしでパターンや関係を見つけ出します。モデルは、学習を通してデータセットに含まれる類似性を特定したり、類似データポイントをグループ化したり、基礎となる隠れたパターンを見つけ出したりできるようになります。
-
強化学習: このアプローチでは、エージェントが試行錯誤による学習を繰り返すことで、環境から与えられる報酬が最大限になるようなアクションを突き止めます。強化学習は、ロボティクス、ゲームプレイング、自律システムなど、試行錯誤を通して最適な意思決定戦略を学習する必要があるシナリオで多く利用されます。エージェントはいろいろなアクションを試行錯誤し、それぞれのアクションの結果から学習して、意思決定プロセスを最適化します。
この数年で、最小限の人の介入で機械学習パイプライン全体の構築プロセスを自動化するために、OneNine AI や Salesforce AI といった AutoML およびノーコード AI ツールが登場しています。
機械学習の役割
機械学習は、人工知能の一種であり、統計的アルゴリズムを使用することで、明示的にプログラミングしなくてもコンピューターがデータから学習できるようにします。機械学習ではアルゴリズムを使用してモデルを構築し、入力に基づいて予測や意思決定を行います。
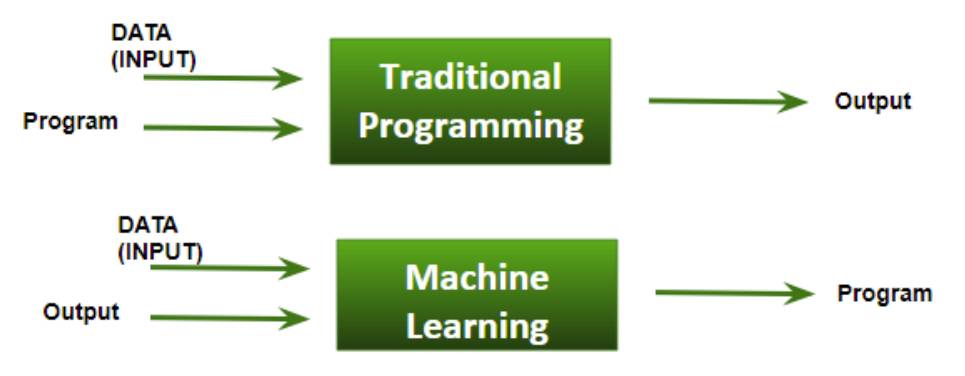
機械学習とプログラミングの違い
従来のプログラミングでは、問題の詳細と実現すべき解決策をプログラマーが明確に理解している必要があります。機械学習では、アルゴリズムがデータから学習して、問題を解決するための独自のルール、つまりモデルを生成します。
機械学習におけるデータの重要性
データは、機械学習を駆動するための燃料です。機械学習の精度と効果は、モデルのトレーニング使用するデータの質と量によって大きく影響されます。使用するデータの関連性、精度、完全性質、そして公正さを保証することは不可欠です。
データの品質と機械学習の制限
データの品質を保証するためには、データを事前にクリーニングして前処理することで、ノイズ (不要な情報や無意味な情報)、欠落値、外れ値などを除去する必要があります。
機械学習は幅広い問題を解決できるパワフルなツールですが、その効果には過学習、学習不足、バイアスなどの制限があります。
-
過学習は、モデルが複雑すぎてトレーニングデータを密接に適合させすぎた結果、一般化が不十分となった場合に発生します。
-
学習不足は、モデルが単純すぎてデータの基礎となるパターンを捕捉できなかった場合に発生します。
-
バイアスは、現実世界の対象を代表していないデータでモデルをトレーニングした場合に発生します。
機械学習は、使用するデータの質と量、複雑なモデルでの透明性の欠如、新しい状況に対する一般化の困難さ、欠落データの処理の課題、バイアスのかかった予測の可能性によって制限されます。
機械学習は強力なツールですが、機械学習モデルの設計や使用に際しては、これらの限界を認識して考慮することが重要です。
予測 AI と生成 AI の違い
予測 AI は、機械学習アルゴリズムを使用して、データ入力に基づいて予測や意思決定を行います。予測 AI は、詐欺行為の検出、医療診断、顧客離れの予測など、幅広く応用できます。
異なるアプローチと異なる目的
予測 AI は、モデルをトレーニングして、データに基づいて予測や意思決定を行う機械学習の一種です。モデルには入力データのセットが与えられ、モデルは学習を通してデータに含まれるパターンを認識することで、新しい入力に対して正確な予測を行えるようになります。予測 AI は画像認識、音声認識、自然言語処理などに広く応用されています。
生成 AI は、与えられた入力に基づいて画像、動画、テキストなどの新しいコンテンツを作り出します。生成 AI は、既存のデータに基づいて予測を行うのではなく、入力データに類似した新しいデータを創造します。芸術、音楽、執筆など、幅広い分野での応用が考えられます。生成 AI の一般的な例としては、ニューラルネットワークの利用による、与えられた入力セットに基づいた新しい画像の生成があります。
予測 AI と生成 AI は人工知能への異なるアプローチですが、相互に排他的な関係ではありません。実際に、多くの AI アプリケーションでは、目標を達成するために予測 AI と生成 AI の両方のテクニックを活用しています。たとえば、チャットボットは予測 AI を利用してユーザーの入力を理解し、生成 AI を利用して人間の音声に類似した応答を生成しています。概して、予測 AI と生成 AI のどちらを選ぶかは、具体的な用途やプロジェクトの目標によって決まります。
予測 AI と生成 AI の概要とこれらの違いについて理解しました。それぞれができることを簡単にまとめます。
予測 AI |
生成 AI |
|---|---|
ラベル付きデータに基づいて正確な予測を行うことができる |
新しい創造的なコンテンツを生成できる |
詐欺行為の検出、医療診断、顧客離れの予測など、幅広い問題の解決に利用できる |
芸術、音楽、執筆など、幅広い創造的な用途に利用できる |
利用できるラベル付きデータの品質と量によって制限される |
入力データによってはバイアスのかかったコンテンツや不適切なコンテンツを生成することがある |
トレーニングに使用されたラベル付きデータの範囲外の予測を行うのは困難な場合がある |
文脈を理解したり、一貫性のあるコンテンツを生成したりするのは困難な場合がある |
トレーニングとリリースには大量の計算リソースが必要な場合がある |
精度や緻密さが求められるアプリケーションなどには適さない場合がある |
生成 AI の制限
生成 AI は、与えられた入力に基づいて画像、動画、テキストなどの新しいコンテンツを作り出します。たとえば、ChatGPT は大規模な言語モデルを使用して、テキスト入力に対して人間のような応答を生成する生成 AI ツールです。ChatGPT は、大量のテキストデータでのトレーニングと学習を通して、先行する単語に基づいて次に来る単語を予測します。
ChatGPT は人間のような応答を生成できますが、制限もあります。トレーニングに使用したデータによっては、バイアスのかかった応答や不適切な応答を生成してしまう可能性もあります。これは、トレーニングデータに含まれるバイアスや制限を反映してしまうという機械学習モデルに共通した問題です。もしトレーニングデータに多くの否定的な言葉や攻撃的な言葉が含まれていると、ChatGPT は同じように否定的あるいは攻撃的な応答を生成してしまうことがあります。
また、ChatGPT はユーザーが入力したテキストの文脈を理解したり、一貫した応答を生成したりすることが苦手です。ChatGPT の優秀さは、トレーニングに使用したデータの優秀さに過ぎません。トレーニングデータが不完全だったり、バイアスがかかっていたり、あるいは他の欠陥があったりすると、モデルは正確な応答や有意義な応答を生成できないことがあります。これは、精度や関連性が重要な用途では重大な制限となってしまいます。他の機械学習モデルと同様にデータが重要な役割を果たしますので、トレーニングに使用したデータの品質が低いと、ChatGPT もあまり役に立たなくなります。
ChatGPT の例は、AI 効果的に利用するためにデータが果たす重大な役割を実証しています。
AI のデータライフサイクル
データライフサイクルとは、最初のデータ収集から最終的な削除までにデータが通るフェーズを意味します。AI のデータライフサイクルは、データの収集、前処理、トレーニング、評価、リリースといった一連のステップで構成されます。使用するデータの関連性が高く、正確かつ完全で、バイアスが含まれておらず、さらには生成されたモデルが効果的かつ倫理的であることを保証することが重要です。
AI データライフサイクルは継続的なプロセスであり、モデルは常に新しいデータやフィードバックに基づいて更新して改善する必要があります。また、細部への慎重な配慮と倫理的で効果的な AI を実現するための努力を必要とする、反復プロセスでもあります。機械学習モデルの開発者とユーザーは、モデルが効果的で、正確で、倫理的であり、社会に良い影響を与えることを保証する必要があります。データが責任のある方法で倫理的に収集、保管、使用されることを保証するためには、データライフサイクルが非常に重要です。
データライフサイクルの各フェーズは次のとおりです。
-
データの収集: このフェーズでは、さまざまなソース (センサー、アンケート、オンラインソースなど) からデータを収集します。
-
データの保管: 収集したデータは、安全に保管する必要があります。
-
データの処理: このフェーズでは、データを処理してインサイトやパターンを抽出します。機械学習アルゴリズムや他のデータ分析テクニックを使用することもあります。
-
データの使用: 処理が完了したデータは、意思決定やポリシーへの情報提供といった目的に使用できます。
-
データの共有: 他の組織や個人とのデータの共有が必要な場合もあります。
-
データの保持: データの保持とは、所定の期間にわたってデータを保管しておくことを意味します。
-
データの廃棄: データが不要になったら、安全に廃棄する必要があります。デジタルデータの安全な削除や、物理メディアの破壊などが含まれます。
AI と機械学習は、どちらも多くの業界で革新を起こし、複雑な問題を解決する潜在能力を秘めていますが、制限や倫理的な考慮事項を意識することが重要です。次の単元では、データの倫理とプライバシーの重要性について学習します。
リソース
- 外部サイト: OneNine AI: AI Use Cases by Industry (OneNine AI: 業種別の AI ユースケース)
- GitHub: Types of Deep Learning Models (深層学習モデルの種類)
- Trailhead: 人工知能の基礎
- ブログ投稿: What are ChatGPT’s limits? (ChatGPT の制限とは)