ピボットテーブルを作成する
学習の目的
この単元を完了すると、次のことができるようになります。
- ピボットテーブルが Marketing Cloud Intelligence でどのように機能するかを説明する。
- Marketing Cloud Intelligence でピボットテーブルを作成する。
- データをピボットテーブルに追加する。
- ピボットテーブルのデータを分析して検証する。
ピボットテーブルとは?
ピボットテーブルは、データの分析に使用する効果的かつ動的なツールです。データは最も役に立つように並べられて表示されます。ピボットテーブルを使用すると、データを意味のある方法でまとめてすばやく統計値やインサイトを得ることができます。そのため、データ分析にはピボットテーブルが不可欠です。Marketing Cloud Intelligence ピボットテーブルは、他のプログラムで使用してきたピボットテーブルとよく似ています。そのため、ピボットテーブルに慣れていれば、Marketing Cloud Intelligence で使用するのも簡単です。
Marketing Cloud Intelligence では、ピボットテーブルはレポートとして保存することも、ウィジェットの作成に使用することもできます。ピボットテーブルの最も一般的な用途は、データがソースから Marketing Cloud Intelligence に正しく読み込まれているか確認することです。これにより、データの品質を簡単にチェックして、値が正しくまとめられているかどうかを確認できます。早速、ピボットテーブルを作成しましょう。
このモジュールでは、受講者が Marketing Cloud Intelligence ユーザーで、説明されるアクションを実行するための適切な権限を有しているものと想定しています。Marketing Cloud Intelligence ユーザーでなくても問題ありません。このまま読み進み、本番でこれらの手順をどう実行するのかを学習してください。Trailhead Playground で次の手順を実行しないでください。Trailhead Playground では Marketing Cloud Intelligence を使用できません。
ピボットテーブルの作成方法
ピボットテーブルには、データモデルに定義されているディメンションとメジャメントが表示されます。データを並び替え、絞り込み、比較して Marketing Cloud Intelligence で正しく対応付けられていることを確認できます。
 Pia はアウトドア用品と衣料の小売企業である Northern Trail Outfitters (NTO) のエンタープライズアーキテクトです。Total Connect を介して Marketing Cloud Intelligence にデータをアップロードしていて、データが正しく対応付けられたか確認したいと考えています。ピボットテーブルは、データが意図したとおりに対応付けられているか確認するための最初のステップです。ピボットテーブルを作成するには、[ピボットテーブル] と [データストリーム] のどちらかを使用するという 2 つの方法があります。その方法は、次のとおりです。
Pia はアウトドア用品と衣料の小売企業である Northern Trail Outfitters (NTO) のエンタープライズアーキテクトです。Total Connect を介して Marketing Cloud Intelligence にデータをアップロードしていて、データが正しく対応付けられたか確認したいと考えています。ピボットテーブルは、データが意図したとおりに対応付けられているか確認するための最初のステップです。ピボットテーブルを作成するには、[ピボットテーブル] と [データストリーム] のどちらかを使用するという 2 つの方法があります。その方法は、次のとおりです。
[ピボットテーブル] を使用してピボットテーブルを作成する
Marketing Cloud Intelligence で、[Analyze & Act (分析 & 活用)] タブ、[Pivot Tables (ピボットテーブル)] の順に移動します。[新規追加] (+) アイコンをクリックします
![[Pivot Tables (ピボットテーブル)] が表示されている Marketing Cloud Intelligence の [Analyze & Act (分析 & 活用)] タブ。](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/data-analysis-in-datorama/create-pivot-tables-/images/ja-JP/5986c94f6f3f6d655d3510ec319509df_kix.xnwom3sbef7j.png)
[データストリーム] を使用してピボットテーブルを作成する
Marketing Cloud Intelligence で、[接続 & 加工] タブ、[データストリーム一覧] の順に移動します。データストリームを選択して [ピボットテーブルで表示] をクリックします。これで [日付範囲] (1) を調整し、[ディメンション] と [メジャメント] (2) および [フィルター] (3) を [設定] テーブルから追加できます。
日付範囲は、Pia がピボットテーブルを作成するデータストリームに従って自動的に設定されます。
![[日付範囲]、[ディメンション]、[メジャメント]、[フィルター] が強調表示されたピボットテーブルの [設定] ウィンドウ。](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/data-analysis-in-datorama/create-pivot-tables-/images/ja-JP/a1cec59708215e054acdb92e46207c32_kix.qvbbn9zeb901.png)
[ピボットテーブル] を使用してデータをカスタマイズして分析する
ピボットテーブルを作成できたので、次に進みましょう。ピボットテーブルでは、さまざまな視点からデータを分析できます。データを計算、要約、分析できます。たとえば、データをカテゴリでグループ化、年月で分類、カテゴリで絞り込みまたは除外することができます。
データをカスタマイズする準備ができたので、Pia はまず、日付範囲に対象の日付が反映されていることを確認します。日付範囲を変更するには、[日付範囲] フィールドをクリックし、日付を定義し、[適用] をクリックするだけです。
![12 月 25 日 ~ 1 月 1 日が選択された [日付範囲] 選択ウィンドウ。](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/data-analysis-in-datorama/create-pivot-tables-/images/ja-JP/e36b6e982a4bbf04a28e120a588936e5_kix.ne1eclwh24tm.png)
[設定] テーブル (1) を編集します。ピボットテーブルに含めるディメンションとメジャメントを選択します。次に、[行] と [値] (2) を表すディメンション/メジャメントを定義する必要があります。定義するには、選択したディメンションまたはメジャメントを、その横にあるプラス記号 (3) をクリックするか、目的のフィールドにドラッグします。[検索] (4) フィールドを使用して、特定のディメンションまたはメジャメントを見つけることもできます。
ここでは [Media Buy Name (広告グループ名)] が [行] に、[Impressions (インプレッション数)] が [値] に追加されています。
![[Media Buy Name (広告グループ名)] が行、[インプレッション数] が値として表示されているピボットテーブルの [設定] ウィンドウ](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/data-analysis-in-datorama/create-pivot-tables-/images/ja-JP/d2206dceca50c1f5a89507b991b717b6_kix.38da012okceq.png)
ピボットテーブルを絞り込む
検索条件をピボットテーブルに追加して、キャンペーン名に関連するデータなど、特定のデータに絞り込むことができます。Pia はいくつかの検索条件をピボットテーブルに追加します。[Filters (フィルター)] セクションで [Add Filter (フィルターの追加)] をクリックします。[フィルター] ウィンドウで、ディメンション名を検索し、絞り込みに使用する値を選択して [保存] をクリックします。
ここで Pia はディメンションとして [キャンペーン名]、値として 2021_Q1_COMPANYNAME_CA_RTNR_US_BRAND_SP_AUDIENCE_NYC_USA を使用します。
![[キャンペーン名] の検索値が表示されているピボットテーブルの [フィルター] ウィンドウ。](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/data-analysis-in-datorama/create-pivot-tables-/images/ja-JP/34550bf0b9a63dfa2475453c2292ebfd_kix.crw9bamv87e5.png)
データを検証するために、Pia はアップロードした元のファイルをピボットテーブルの結果と比較します。まず、ピボットテーブルとソースデータの両方に同じ日付範囲と検索条件値が適用されていることを確認します。
Pia は次の [日付] および [キャンペーン名] 検索条件を適用します。
- 日付 > 2020
-
2021_Q1_COMPANYNAME_CA_RTNR_US_BRAND_SP_AUDIENCE_NYC_USA
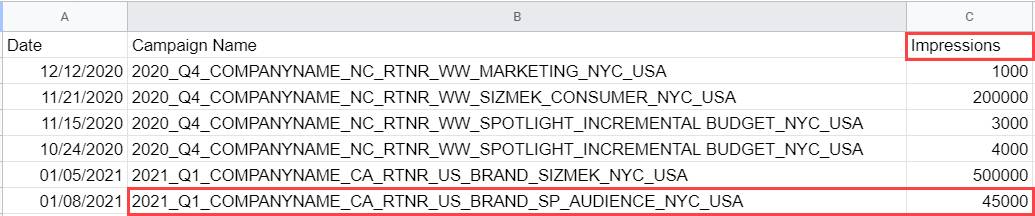
![ピボットテーブルに定義されたものと同じ [キャンペーン名] 検索条件が表示されているソースデータ。](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/data-analysis-in-datorama/create-pivot-tables-/images/ja-JP/83e995b3f6454ac8239629d1dbdb2275_kix.96lr6q52t016.png)
ソースファイルの合計をピボットテーブルの合計と比較します。一致すれば、データが正しくアップロードされたことがわかります。
次の画像で、ソースファイルとピボットテーブルのインプレッション数の合計が一致することを確認できます。
ソースファイルのインプレッション数の合計
ピボットテーブルのインプレッション数の合計

両方のクリック数の合計も一致しています。
ソースファイルのクリック数の合計

ピボットテーブルのクリック数の合計

データが正しく表示されていることを確認できたので、Pia は [PivotTable Name (ピボットテーブル名)] フィールドにピボットテーブル名を指定し、[保存] をクリックします。
ピボットテーブルの作成とカスタマイズの方法がわかったところで、次の単元に進んでピボットテーブルのエクスポートと共有の方法を学習します。