Data 360 のセグメンテーションを詳しく見る
学習の目的
この単元を完了すると、次のことができるようになります。
- セグメンテーションを定義する。
- セグメンテーションのユースケースを説明する。
- セグメントキャンバスインターフェースを操作する。

Data 360 セグメント
Data 360 を使用して有意義なセグメントを作成する準備はできていますか? このモジュールは皆さんのためにあります。Salesforce Data 360 を探索する準備を整え、セグメントキャンバスインターフェースの操作方法や、セグメントの作成とフィルター設定の基本を学びましょう。
始める前に
このモジュールを始める前に、推奨コンテンツである「マーケティング担当者向けの Data 360 の基本」を完了することを検討してください
Data 360 の概要
事前の説明は以上です。ここからは、データを使用してお客様向けのパーソナライズされた魅力あるコミュニケーションに役立つセグメントを作成する方法を説明します。まずは、Data 360 のホームページに移動します。Marketing Cloud Engagement ユーザーは、Salesforce Lightning ユーザーほど Data 360 の外観に馴染みがないかもしれません。一緒に見て回りましょう。

-
[Data Streams (データストリーム)]、[Data Lake Objects (データレークオブジェクト)]、[Data Model (データモデル)] (1) タブには、選択したデータモデルおよび接続されたデータソースに関するインサイトが表示されます。このインサイトは Data Cloud アーキテクト権限セットを持つユーザーによって作成されます。
-
[Data Explorer (データエクスプローラー)] と [Profile Explorer (プロファイルエクスプローラー)] (2) はデータ表示ツールで、取得されたプロファイルデータや統合されたプロファイルデータをそれぞれ表示できます。
-
[ID 解決] (3) では、チームが個々のレコードを統合するための一致ルールや調整ルールを作成します。
-
[Calculated Insights (計算済みインサイト)] (4) は、セグメントの作成に役立つ事前定義済みで計算済みのメトリクスです。
-
[セグメント] (5) タブは、マーケターがフィルター済みオーディエンスセグメントを作成する場所です。
-
[Activation Targets (有効化対象)] と [Activations (有効化)] (6) ではセグメントをどこに公開するか (Marketing Cloud Engagement など) を管理できます。
- 最後に、[設定] (7) 歯車はシステム管理者がアカウント設定を管理する場所です。
ヒント: 上記のタブの順序はカスタマイズできます。
セグメントの紹介
データを絞り込んで、お客様を理解、ターゲティング、分析するのに役立つセグメントを作成します。
セグメントキャンバスインターフェース
いくつかのユースケースを念頭に置いて、Data 360 のセグメントを作成できます。まず、セグメントキャンバスインターフェースの主要な要素を確認します。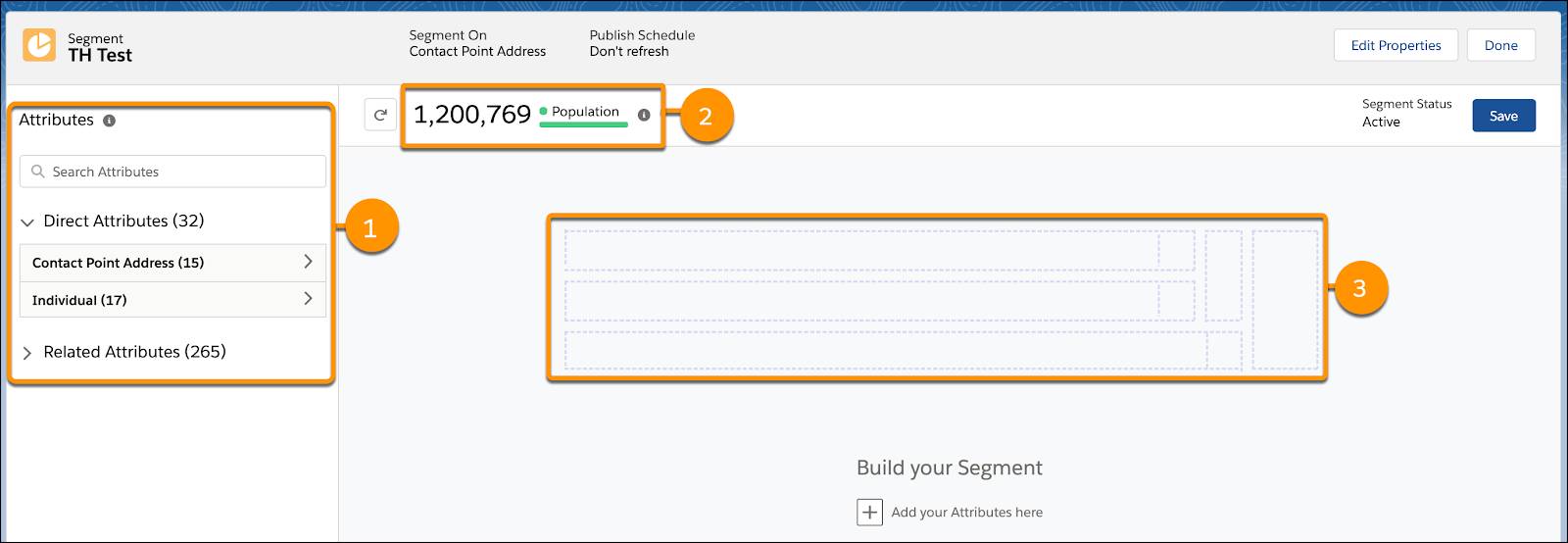
属性ライブラリ (1)
属性ライブラリには、データモデルでマッピングされ、セグメンテーションで使用するようにマークされている属性のうち、選択したセグメント対象に関連付けられたものが表示されます。属性には、Marketing Cloud Engagement のエンゲージメントデータなどの標準データソースからのものもあれば、カスタムデータオブジェクトやシステムデータからのものもあります。属性によって、セグメントが対象オーディエンスに絞り込まれます。次の 2 つの種類があります。
-
直接属性はセグメント対象と 1 対 1 のリレーションを持つ属性です。つまり、セグメント化された各オブジェクトにはプロファイル属性の 1 つのデータポイントしかないということです。顧客データの場合、郵便番号や名には 1 つしかエントリがありません。
-
関連属性は複数のデータポイント持つことができる属性です。顧客データの場合、関連属性は購入数やメール開封数など、1 人が複数持つことができるデータポイントです。
セグメント対象によってどの属性を選択できるかが決まるため、データモデルを理解しておくことが重要です。安心してください。セグメント対象の概念については次の単元で学習します。
母集団 (2)
母集団とは現在のセグメント内のレコード数のことです。これは、公開後または要求に応じた計数の実行後に更新されます。
コンテナ (3)
属性は個別のコンテナにドラッグすることで、属性間の AND/OR リレーションロジックを作成できます。コンテナを使用することで、関連属性間のリレーションを作成することができ、検索条件ロジックを作成するために使用されます。属性が 1 つのコンテナに入れられると、クエリエンジンによって互いにそのように関係する属性が検索されます。別々のコンテナの属性は関連付けられません。
コンテナの例
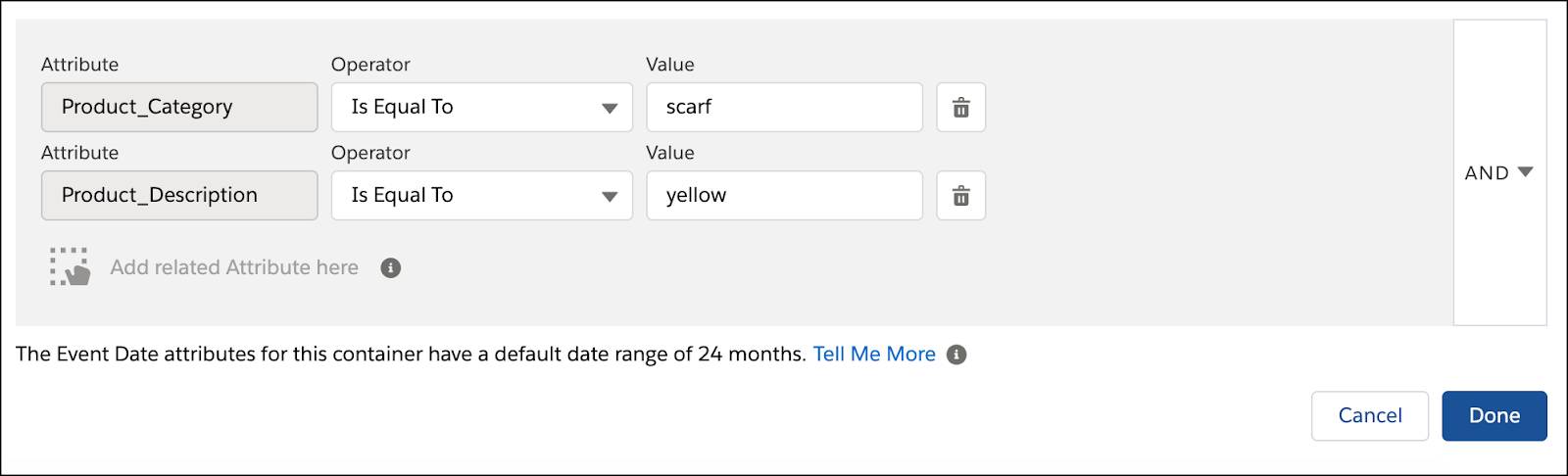
では、例を見てみましょう。アウトドアアパレル会社である Northern Trail Outfitters (NTO) は、黄色のスカーフを購入した顧客にメールを送信しようとしています。使用するコンテナは次のとおりです。
コンテナ 1=
- 関連属性:
- Product_Category が scarf (スカーフ) と等しい
- Product_Description が yellow (黄色) と等しい
- ロジック: AND
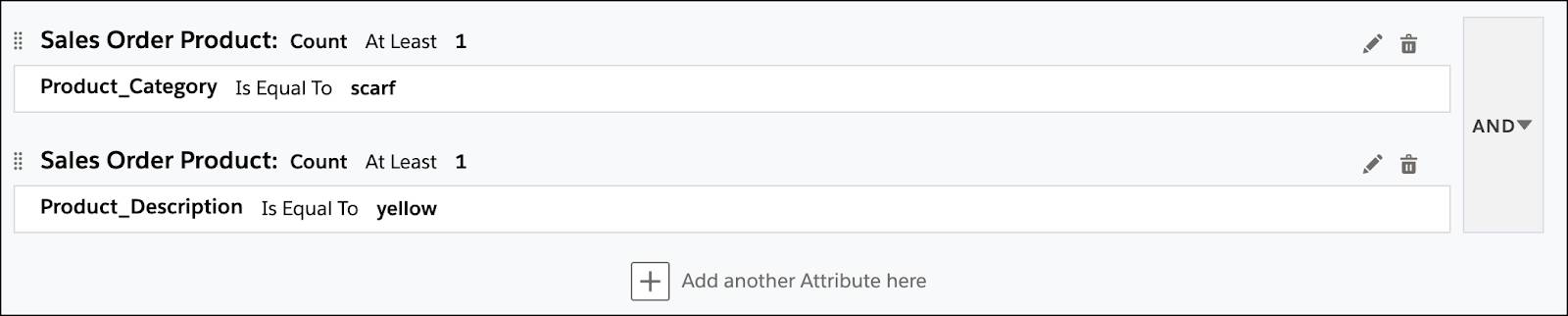
NTO チームが 2 つのコンテナを別々に作成した場合、クエリエンジンによって任意の色のスカーフと黄色の商品を購入した顧客が検索されます。
- コンテナ 1=
- 関連属性: Product_Category が scarf (スカーフ) と等しい
- コンテナ 2=
- 関連属性: Product_Description が yellow (黄色) と等しい
- ロジック: AND
どちらのオプションもマーケティングキャンペーンに使用できますが、クエリを開始するときには正確に何を求めているかを知っておくことをお勧めします。そのために、次の単元ではデータとクエリロジックをさらに詳しく学習します。
リソース