データ取得フェーズとデータモデリングフェーズを確認する
学習の目的
この単元を完了すると、次のことができるようになります。
- データが Data Cloud に取得される方法を調べる。
- 取得したデータの解釈に役立つキー修飾子を設定する。
- 基本的なデータモデリングの概念をアカウントに適用する。
データ取得
データはまずソースから取得されてシステムのデータレークオブジェクトに保存されますが、どのようにソースシステムのデータに接続してアクセスするのでしょうか? データはサーバー間の通信を確立するコネクタを使用してソースから取得され、継続的にアクセスできます。データストリームは接続をいつどの頻度で確立するかをコネクタに指示します。
現在、Data Cloud ユーザーは次のコネクタを利用できます。今後もさらに多くのコネクタが利用可能になる予定です。
- クラウドストレージコネクタ
- Google Cloud Storage コネクタ
- B2C Commerce コネクタ
- Marketing Cloud Personalization コネクタ
- Marketing Cloud Engagement データソースおよびコネクタ
- Salesforce CRM コネクタ
- Web およびモバイルアプリケーションコネクタ
では、1 つずつ確認しましょう。
クラウドストレージコネクタ
このコネクタでは Amazon Web Services S3 ロケーションに保存されたデータからデータストリームを作成します。カスタムデータセットに対応していて、データ取得頻度は毎時、毎日、毎週、毎月のいずれかを選択できます。カスタムデータセットと同様に、コネクタでインポートステップが実行され、その後でユーザーがデータをモデルにマッピングします。
上記のいずれのコネクタでも、[更新履歴] タブでデータが期待された頻度で取得され、エラーがないことを検証できます。取得エラーが発生した場合、[状況列] (次の画像を参照) にエラーに関する情報が表示されます。
![Order Header2 データストリームの [更新履歴] タブ。](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/customer-360-audiences-data-ingestion-and-modeling/review-data-ingestion-and-modeling-phases/images/ja-JP/e94a783b09ba116ebd3dc43e4bc581a6_61-f-5-cb-4-b-221-a-4183-be-40-cfd-4-aab-0-a-232.png)
Google Cloud Storage コネクタ
このコネクタは Google Cloud Storage (GCS) からデータを取得します。GCS は、Google Cloud Platform インフラストラクチャ上のオンラインファイルベースのストレージ Web サービスです。Data Cloud は、GCS バケットから読み取り、データを使用するための Data Cloud 所有のステージング環境に有効なオブジェクトのデータを自動的かつ定期的に転送します。
B2C Commerce コネクタ
このコネクタは、B2C Commerce インスタンスからデータを取得して、B2C Commerce データストリームを作成します。
Marketing Cloud Personalization コネクタ
このコネクタは Data Cloud に Marketing Cloud Personalization からユーザープロファイルと行動イベントを取得する際に役立ちます。 Marketing Cloud Personalization を有効化対象として使用することもできます。このコネクタを使用する場合、スターターバンドルを作成する必要があります。
Marketing Cloud Engagement データソースおよびコネクタ
Data Cloud で提供されるスターターデータバンドルでは、メールとモバイルの事前定義されたデータセット (Einstein エンゲージメントデータを含む) を使用できます。これらはすべて既知のシステムテーブルであるため、これらのバンドルを使用してデータセットを現状のままインポートしてから自動的にデータモデルレイヤーに追加するまですべてを行うことができます。つまり、数クリックでビジネスユースケースに取りかかる準備ができます。これらのコネクタで取得されるエンゲージメント指向の行動データセットは毎時更新され、プロファイルデータセットは毎日更新されます。
Marketing Cloud Engagement データエクステンションを介してカスタムデータセットにアクセスすることもできます。たとえば、このコネクタを使用して、すでに Marketing Cloud Engagement にインポートされている e コマースまたはアンケートデータを取得できます。Marketing Cloud Engagement インスタンスを Data Cloud にプロビジョニングするだけで、それ以降、取得可能なデータエクステンションのリストが表示されます。Marketing Cloud Engagement からデータエクステンションをエクスポートする方法 (フル更新、新規/更新されたデータのみ) を選択すると、それに応じてコネクタで毎日 (フル更新) または毎時 (新規/更新されたデータのみ) データが取得されます。データのインポートとモデリングの両方が自動的に行われるスターターデータバンドルとは異なり、このコネクタではデータセットがカスタムであるため、モデリングステップをユーザーが行う必要があります。
Salesforce CRM データ
Sales Cloud および Service Cloud インスタンスで認証したら、選択可能なオブジェクトリストからいずれかを選択するか、オブジェクトを検索し、データストリームにつき 1 オブジェクトを選択して Data Cloud アカウントに接続できます。データは毎時更新され、週に 1 回データのフル更新も行われます。
Web およびモバイルコネクタ
このコネクタでは Web サイトまたはモバイルアプリケーションからオンラインデータを取得します。Data Cloud では Web とモバイルの両方に正規データマッピングを提供してデータの取得を促進します。そのデータを照会してモバイルとメールの両方で有効化できます。
取得 API
他のデータソースへの接続方法をカスタマイズする場合、取得 API を使用してコネクタを作成し、スキーマをアップロードして、組織へのデータストリームを作成できます。このストリームでは、API 要求の設定に応じて増分更新または一括更新ができます。
データを拡張する
コネクタでは全ソース項目リストを取得して元の状態のデータが取得されます。また、必要に応じて追加の計算済み項目を作成できます。たとえば、新しい数式を追加することで、コネクタで年齢項目を未加工の数値として取得し、そのデータを 18 ~ 24 才、25 ~ 34 才、35 ~ 44 才、45 才以上のグループにまとめることができます。数式では、IF ステートメントと <AND または OR> 演算子の組み合わせを、年齢ソース項目から派生したデータレークオブジェクトに対して使用します。
複数の数式関数を使用できます。それらは 4 つのカテゴリに分けられます。
- テキスト操作
- 例: EXTRACT()、FIND()、LEFT()、SUBSTITUTE()
- 型変換
- 例: ABS()、MD5()、NUMBER()、PARSEDATE()
- 日付計算
- 例: DATE()、DATEDIFF()、DAYPRECISION()
- 論理式
- 例: IF()、AND()、OR()、NOT()
キー修飾子を設定する
さまざまなソースからデータを取得し、Data Cloud データモデルでハーモナイズするときに、完全修飾キー (FQK) を使用してキーの競合を回避します。各データストリームは特定のキーと属性を使用して Data Cloud に取得されます。複数のデータストリームが 1 つのデータモデルオブジェクト (DMO) にハーモナイズされると、さまざまなキーが競合し、複数のレコードが同じキー値を持つ状態になる可能性があります。完全修飾キーを使用すると、キー修飾子項目を追加してデータを正確に解釈できるため、競合を回避できます。完全修飾キーは、ソースキー (CRM の取引先責任者 ID や Salesforce Marketing Cloud Engagement の購読者キーなど) とキー修飾子で構成されます。

キー値が含まれるすべてのデータレークオブジェクト (DLO) のキー修飾子項目を設定します。この項目はプライマリキー項目または外部キー項目にできます。ハーモナイズされたデータがどのように解釈されるか、キー修飾子なしとありの例を見てみましょう。
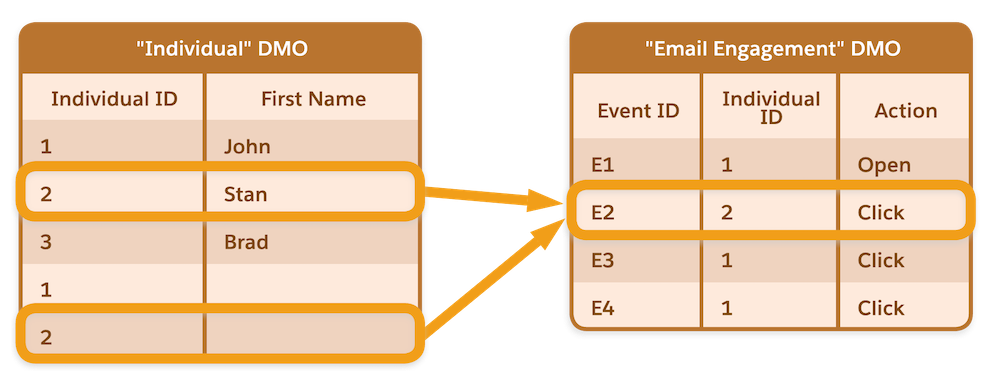
2 つのデータストリームがあり、プロファイルデータの関連データレークオブジェクト (DLO) として、それぞれ Salesforce CRM からの取引先責任者 DLO と Marketing Cloud Engagement からの購読者 DLO があるとします。この DLO のレコードが個人 DMO にマッピングされます。
ここでは、個人 DMO をエンゲージメント DMO と結合して 2 クリック以上の個人を特定しようとしています。データのハーモナイゼーション後、2 つのデータストリームは Data Cloud の個人 DMO にマッピングされます。取引先責任者 DLO には 3 件のレコード、購読者 DLO には 2 件のレコードがあります。個人 DMO にはマッピングされたすべてのデータストリームからのレコードがすべて含まれるため、5 件のレコードがあります。
Marketing Cloud Engagement では CRM 組織の取引先責任者 ID をプライマリキー (購読者キー) として使用します。そのため、個人 DMO の複数のレコードでプライマリキー項目である個人 ID の値が同じになります。
![[個人 ID] 列と [名] 列がある個人 DMO の図。](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/customer-360-audiences-data-ingestion-and-modeling/review-data-ingestion-and-modeling-phases/images/ja-JP/28ea783d759f0d9d99bb1aa0659b6ca4_23867042-5-e-8-d-4-cdb-bb-18-9-c-182-c-9-efde-9.png)
次に、Salesforce Marketing Cloud Engagement から取り込まれたメールエンゲージメントデータが含まれるメールエンゲージメント DMO について考えます。個人 DMO とメールエンゲージメント DMO には個人 ID を介した 1:N リレーションがあります。
個人 DMO とメールエンゲージメント DMO を結合すると、Data Cloud では結合データセットを個人 2 の 1 行目 (1 クリック) と個人 2 の 2 行目 (1 クリック) として解釈します。つまり、個人 2 は 2 メールクリックと想定されます。Data Cloud では個人 2 は 2 クリックアクションと解釈されますが、実際には 1 クリックアクションのみです。
この誤解釈により、セグメンテーション、計算済みインサイト、クエリ API など、このデータが照会されたときに問題が発生することがあります。クエリを実行して、クリックアクションが 2 以上の個人を照会すると、応答で個人 2 が返されます。この問題は、プロファイルの統合がリリースされていても発生します。エンゲージメントデータは常に個人 DMO と結合されるからです。
プライマリキーまたは外部キーのキー値が含まれるすべての DLO 項目にキー修飾子項目を追加すると、Data Cloud でさまざまなデータソースから取得されたデータが正しく解釈されます。次の例では、キー修飾子が Salesforce CRM と Marketing Cloud Engagement からの DLO に追加されています。個人 DMO にはレコードのソースを示すキー修飾子項目が追加されています。

個人 DMO とメールエンゲージメント DMO が結合されると、テーブル結合で外部キー項目 (個人 ID) とキー修飾子項目 (KQ_ID) の両方が使用されるため、Data Cloud でデータを正確に解釈できます。

同じクエリを実行して、クリックアクションが 2 以上の個人を照会すると、個人 2 はクエリ条件を満たさないため、クエリ応答では返されません。計算済みインサイト (CI)、セグメンテーション、クエリ API でキー修飾子項目を使用して、顧客データを正確に特定し、対象にして、分析できます。
データモデリング
すべてのデータストリームがシステムに取得したら、ソースと対象をマッピングするときに Customer 360 データモデルを使用してデータソースを正規化できます。たとえば、Customer 360 データモデルの個人 ID の概念を使用して、デバイスを購入した個人 (1 つ目のデータストリーム)、サービスの問題について電話をかけた個人 (もう 1 つのデータストリーム)、交換品を受け取った個人 (さらにもう 1 つのデータストリーム) に対応するソース項目にタグ付けし、カスタマージャーニーのあらゆるイベントを確認できます (さらにもう 1 つのデータストリーム)。データマッピングによって、データソースの該当する項目間を線でつないであらゆるものを一緒に結び付けることができます。名前、メールアドレス、電話番号 (または類似の識別子) のような属性には特に注意します。この情報は個人のデータをつないでまとめ、最終的に顧客の統合プロファイルを作成するのに役立ちます。あらゆるものに場所と他のものへのつながりがあります。必要なのは線でつなぐことだけです。
Customer 360 データモデルは、既存の標準オブジェクトにカスタム属性を追加したり、カスタムオブジェクトを追加したりして拡張できるように設計されています。標準オブジェクトを利用する場合、2 つのオブジェクトを関連付ける項目がどちらにもマッピングされると、自動的にオブジェクト間のリレーションが明らかになります。後の単元では、カスタムオブジェクトをモデルに追加したときにオブジェクト間のリレーションを定義する必要が生じる例を手順に従って学習します。
データ取得とモデリングの基本的な概念に慣れたところで、具体的な例に進みましょう。