AI モデルを作成して評価する
学習の目的
この単元を完了すると、次のことができるようになります。
- モデルビルダーを使用してモデルを作成する方法を説明する。
- メトリクスを使用してモデルの品質を理解する理由を説明する。
- モデルのパフォーマンスを評価するために使用されるメトリクスを挙げる。
モデルを作成して評価する
AI モデルは、特定のタスクを可能にするメカニズムであることを学びました。AI モデルを使用して、ビジネスインテリジェンスを強化し、ワークフローを高速化し、ユーザーがより適切な意思決定を行えるようにすることができます。つまり、AI モデルを使用すると、データを分析して専門家になることを機械に指示し、その専門知識を新しいデータに適用することで、データの価値を引き出すことができます。
データの準備
予測モデルの構築に必要な作業の大部分は、実のところデータの準備にあります。データを深く理解しているデータスペシャリストやアナリストがモデルを構築するのに適任であるのはそのためです。最初のリリースでは、Einstein Studio モデルビルダーは Data 360 の 1 つのデータモデルオブジェクト (DMO) に基づいてモデルをトレーニングできます。
将来的にはさらに簡単にすることを目指していますが、Data 360 には、1 つの非正規化された DMO として表すことができるデータテーブルを形成するために、ユーザーがデータを準備してモデル化できるツールがすでに多数用意されています。一括データ変換でモデルのトレーニング用の DMO を作成する方法の例を次に示します。
新しいモデルを作成するステップ
モデルビルダーを使用して、コードではなくクリック操作で、7 つのステップで新しい AI 予測モデルを作成します。詳細は、Salesforce ヘルプの「モデルを作成する手順」を参照してください。
顧客離れの可能性を予測するモデルを最初から作成する次の例について考えてみましょう。[Next (次へ)] ボタンと [前へ] ボタンを使用してステップを確認していきます。
変数と観測
このモジュールの前半で学んだ内容を復習しておくと、予測モデルは機械学習を使用して将来の結果を予測します。モデルビルダーを使用してモデルを作成すると、Einstein はデータを分析して予測モデルを作成するだけでなく、モデルを評価できるようにトレーニングメトリクスも生成します。
変数
モデルでは変数によってデータが整理されます。変数とは、Salesforce 内の項目やスプレッドシートの列のようなデータのカテゴリです。予測因子または説明変数と呼ばれる入力が、予測を生成するために使用されます。
観測
予測は観測レベルで行われます。観測とは、Salesforce のレコードやスプレッドシートの行のような構造化されたデータセットです。
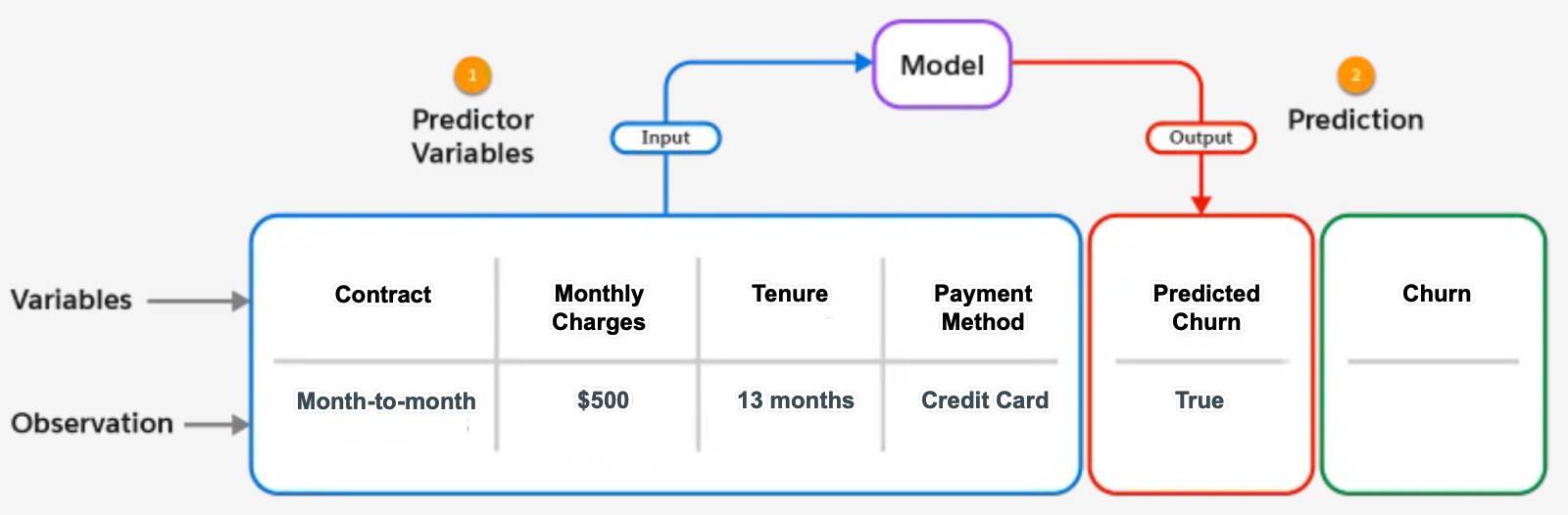
観測ごとに、モデルが 1 つの予測変数セット (1) を入力として使用し、対応する予測 (2) を出力として返します。また、予測に最も影響を与える上位の変数を返すこともできます。この図では、実際の結果 (churn) はまだ不明です。
トレーニングメトリクス
モデルビルダーで最初から作成するモデル (Einstein によって作成されるモデル) には、トレーニングメトリクスが含まれています。トレーニングメトリクスは、AI モデルがどのようにトレーニングされたかを理解し、その品質を評価するのに役立ちます。
トレーニングメトリクスは、モデルのトレーニングに使用されたデータに基づいて計算されます。既知の (観察されたまたは実際の) 結果がある観測ごとに予測を計算し、実際の結果と比較してその精度を判断します。
重要: さまざまなトレーニングメトリクスが用意されています。実際のところ、多すぎてこのモジュールで説明しきれないほどです。けれども心配はいりません。このすべてどころか大半は覚えておく必要がありません。トレーニングメトリクスには情報バブル  が含まれており、こうした計算に伴うニュアンスや数学をすべて理解していなくても、メトリクスを解釈できるようになっています。包括的な一連のトレーニングメトリクスを提供することで、ニーズに基づいてモデルを評価できます。そのため、各自のソリューションに最も適したメトリクスを使用してモデルの品質を評価できます。
が含まれており、こうした計算に伴うニュアンスや数学をすべて理解していなくても、メトリクスを解釈できるようになっています。包括的な一連のトレーニングメトリクスを提供することで、ニーズに基づいてモデルを評価できます。そのため、各自のソリューションに最も適したメトリクスを使用してモデルの品質を評価できます。
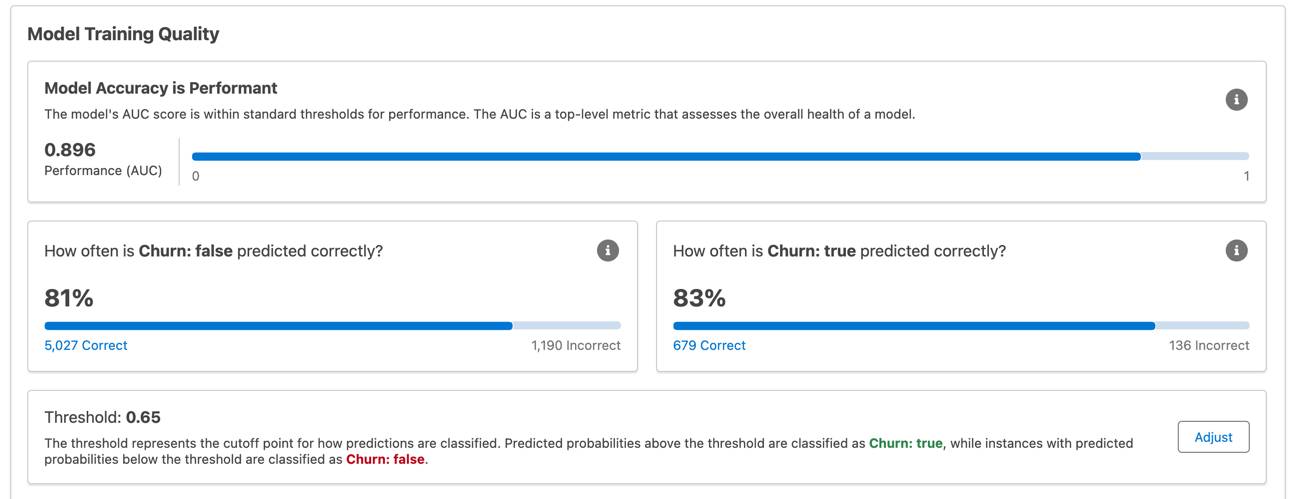
- 正解度は、データ漏洩を過剰適合させるためのランダムな推測のスケールで、予測がどれほど優れているを示します。望ましいのは、モデルの正解度が適切であることです。
- 上位の予測因子は、結果の予測に最も大きな影響を与える入力 (予測) 変数です。
- 変数の分布は、データの実際の観測値のヒストグラムを示します。
適切なモデルとは?
モデルが生成する予測を基にビジネス判断を下すのであれば、結果の予測力が高いモデルが必要になります。最低でも、モデルが存在しないため、データではなく、臆測に頼って判断するしかない場合よりも高い確率で結果を予測するモデルが望まれます。
では、何をもって適切なモデルとされるのでしょうか? 概して適切なモデルとは、結果の改善目標の達成に向けて、ソリューションの要件を満たす十分な精度の予測を生成するものです。具体的には、モデルの予測結果が実際の結果とどのくらい一致するかで判断します。
モデルの予測精度を判断するために、Einstein によって作成されたモデルにはモデルのパフォーマンスの一般的な測定値を視覚化するトレーニングメトリクスが用意されています。データサイエンティストの言うところの適合度統計で、モデルの予測が実際のデータとどの程度適合しているか定量化するものです。モデルは現実世界に似せた抽象実体であるため、どのモデルも多かれ少なかれ不正確です。実際、「完璧」なモデルには疑念を抱くべきで、望ましいものではありません。
モデルについて考えるときは、George Box という統計学者の頻繁に引用される名言、「どのモデルも間違っているが、一部のモデルは役に立つ」ぐらいにとらえるとよいかもしれません。
モデルの品質に満足したら、有効化して使用可能にできます。詳細は、Salesforce ヘルプの「モデルの有効化」を参照してください。
次のステップ
モデルを有効にしたら、実際に使ってみましょう。「モデルビルダーの予測出力」では、予測に基づいてアクションを実行する方法を学習して実践できます。