データベースの基本について
学習の目的
この単元を完了すると、次のことができるようになります。
- データベースの歴史の 5 つのマイルストーンを挙げる。
- リレーショナルデータベースと非リレーショナルデータベースを区別する。
- 「ビッグデータ」を定義する。
データベースの歴史
「データはクラウドにあります」。というセリフを私たちは頻繁に耳にします。これを聞いて霧やかすみが立ち込めた場面を思い浮かべたとしたら、それはもちろん誤解です。クラウドはサーバーが立ち並ぶ物理的なデータセンターにすぎません。Salesforce では世界各地に多数のクラウドを擁しています。ところで、この膨大なデータはどのように整理され、アクセスされるのでしょうか? そのすべてはデータベースによって異なります。この単元は、データベースの主な概念の速習コースです。
タイムライン
事の発端は 1960 年代に遡ります。この頃は室内がコンピューターで埋め尽くされていました。
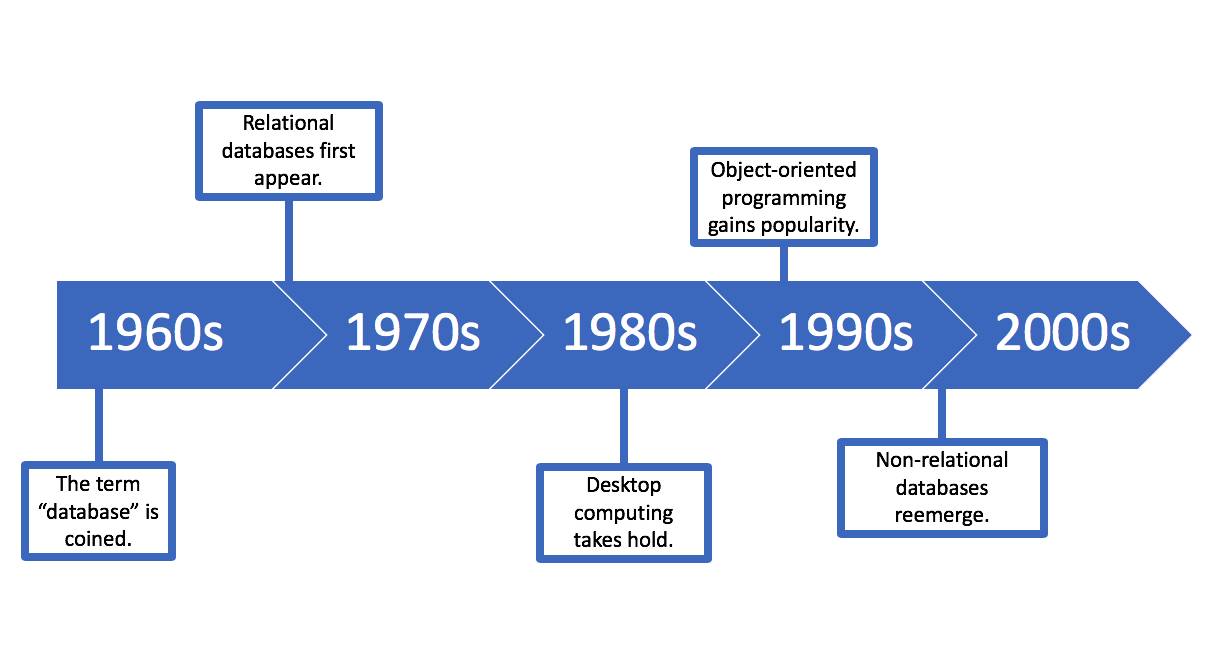
年代 |
マイルストーン |
|---|---|
1960 年代 |
「データベース」という用語が登場したのは、ディスクが磁気テープのストレージに取って代わられた 1960 年代です。最初のデータベースは非リレーショナルで、自由形式のレコードがリンクされていただけでした。この形態は 10 年もしないうちに変化します。 |
1970 年代 |
1970 年代にリレーショナルデータベースが登場し、やがてそれが標準になりました。このデータベースは以前のものとは異なり、正規化され、関連付けられ、検索可能なテーブルで構成されていました。 |
1980 年代 |
1980 年代にデスクトップコンピューティングが普及すると、基盤となるデータベースとやり取りするユーザーフレンドリーなビジネスソフトウェアも台頭してきました。 |
1990 年代 |
1990 年代にオブジェクト指向プログラミング (OOP) が開発され、データを単にテーブルや項目ではなく、クラスやプロパティで整理することが可能になりました。 |
2000 年代 |
2000 年代になると、非リレーショナルデータベースが NoSQL (Not only SQL) データベースという形で復活しました。このデータベースはシンプルながら拡張性に優れていたため、ビッグデータやリアルタイムという Web アプリケーションの要求を満たすことになりました。 |
大まかな沿革がわかったところで、データベースをこの 2 つに大別して詳しく見ていきましょう。
リレーショナルと非リレーショナル
リレーショナルデータベースは数十年にわたって主力であり続け、現在も活用されています。このデータベースでは、データが関連する複数のテーブルに分割されます。親テーブルには「主キー」という一意の識別子の行があります。子テーブルは別の識別子 (「外部キー」) を使用してこの主キーを参照します。下図では、テーブル A が親でテーブル B が子です。

リレーショナルデータベースの特徴
システム管理者や開発者は通常、SQL (構造化クエリ言語) を使用してリレーショナルデータベースのデータにアクセスして操作します。トランザクションには次の 4 つの特徴があります (この頭文字をとって ACID と覚えましょう)。リレーショナルデータベースでは、可用性よりも一貫性が重視されます。
- アトミック (Atomic): すべてのタスクを成功させる必要があります。さもなければトランザクションがロールバックされます。
- 一貫性 (Consistent): トランザクションを通してデータベースの状態が一貫している必要があります。
- 孤立 (Isolated): 各トランザクションが独立し、ほかのトランザクションに依存していません。
- デュラブル (Durable): 失敗したトランザクションのデータを復元できます。
リレーショナルデータベースは、特に複雑なデータ分析や操作に適しています。厳格な構造に従い、データがその構造に適合している必要があります。
けれども、データをどうしても厳格な構造に適合させられないことがあります。1990 年代にインターネットが急速に広まり、カテゴリに収まらないデータが Web アプリケーションで生成されるようになると、構造に適合しない状況が生じるようになりました。ここで非リレーショナルデータベースが盛り返します。現在は「SQL に限定されない」を意味する「Not only SQL」あるいは「NoSQL」データベースと言われることもあります。
非リレーショナルデータベースの種類

4 つの種類があります。
- キー - 値ペアは連想配列モデルを使用します。つまり、データが (キー + 値) ペアの集合体として表されます。
- 列指向ストアはテーブル構造を使用します。テーブルの行ごとに列を変えることができます。
- ドキュメント指向システムは、各ドキュメントの情報を 1 つのインスタンスとしてデータベースに保存します。ドキュメントをネストできます。
- グラフは、要素、要素間のリレーション、要素とリレーションの両方に割り当てられた属性を整理します。
非リレーショナルデータベースの特徴
非リレーショナルデータベースには次の 3 つの共通する特性があります。(頭文字をとった BASE と覚えましょう)。この場合はリレーショナルデータベースとは逆に、一貫性よりも可用性が重視されます。
- 基本的に使用可能 (Basically available): 障害が発生した場合でもシステムを使用できます。
- 状態の柔軟性 (Soft state): データの状態が変わる可能性があります。
- 最終的な一貫性 (Eventual consistency): トランザクションレベルでは一貫性が保証されませんが、最終的には全ノードのデータが同期されます。
非リレーショナルデータベースは構造をモデル化しやすいため、拡張性に優れています。すべてのクライアントが同時に同じデータを参照しているという保証がないため、一貫性が完全でない可能性があります。
両者を比較してみましょう。
リレーショナル |
非リレーショナル |
|---|---|
正規化 |
非正規化 |
SQL |
制限付き SQL または非同期 SQL |
構造化データ |
構造化または非構造化データ |
ACID トランザクション |
トランザクションなしまたは限定的なトランザクション |
それぞれ異なるビジネス要件に対処するため、どちらがよいということではありません。情報量が膨大な場合は、非リレーショナルの一択です。
ビッグデータの登場
ビッグデータと言うと何だかすごいもののようですが、一体何なのでしょうか? ビッグデータとは、データセットが大きすぎるまたは複雑すぎるため、従来のデータ処理アプリケーションソフトウェアでは処理できないデータを言います。ここでいう「大きい」とは、何億 (場合によっては何十億) もの行のことです。ストレージが安価になり、処理が高速になった現在ではビッグデータが巷に溢れています。人工知能 (AI) は機械学習を使用して、人間の限界を上回る速度でレコードを処理します。
データを安価かつスピーディに処理できるのであれば、企業はデータを葬るようなことはしません。ところで、非リレーショナルデータベース (大量かつ多様なデータを管理) とリレーショナルデータベース (複雑なビジネスロジックを処理) は、どのように選べばよいのでしょうか? 実際のところ、このすべてを行うためにはエンタープライズアーキテクチャが必要です。つまり、複数のテクノロジーを 1 つの包括的なソリューションに統合する必要があります。
データベースとビッグデータの課題について多少なりとも理解したところで、次の単元に進んで Salesforce を使用してデータを保存する方法を見ていきましょう。