データセットビルダーでルックアップを作成する
学習の目的
この単元を完了すると、次のことができるようになります。
- データセット粒度を識別する。
- ルックアップを使用してデータセットを作成する。
- 適切な数のベースレベルのデータセットを定義する。
Cloud Kicks へようこそ
Cloud Kicks は、スポーツ選手、有名人、体形を維持してスタイリッシュに見せたい一般の人に人気のあるアスレチックとライフスタイルのブランドです。

Cloud Kicks の第一目標は、作成したリレーションシップを維持して拡張することです。CRM Analytics は、Cloud Kicks がこの目標を達成するのに役立ちます。Cloud Kicks の営業マネージャーである Jose Figueroa は、CRM Analytics のレポートと視覚化によって、セールスパイプラインの各フェーズにおける活動を常に把握できるようになったことを高く評価しています。
Candace は Cloud Kicks の業績トップの営業担当であり、CRM Analytics を使用して商談インタラクションに優先順位を付け、新しい取引先になるように育成しています。Candace は、ダッシュボードを表示し、視覚化を操作できるようにしたいと考えています。また、検索条件、グループ化、数式を追加して、簡単に商談数や金額を把握したいと考えています。多くの場合、Jose と Candace が行う探索では、取引先やユーザーなどの関連オブジェクト間のインタラクションが必要になります。Cloud Kicks の CRM Analytics 管理者であるあなたは、この 2 人の作業をより簡単にする必要があります。そうすることで、2 人はあなたやチームの他のメンバーが必要なレンズを作成するのを待たなくて済むようになります。
このモジュールでは、Jose と Candace が役立てることができるデータセットを作成する手順を見ていきます。重要なのは、データセットに重要な情報の重複や欠落がなく、正確な表現が含まれていることです。
データセットの作成方法を理解する
CRM Analytics データセットは、Salesforce オブジェクト、外部データソース、その他のデータセットなど、多くのソースから作成できる関連データのコレクションです。データセットは、分析、ダッシュボード、モデル、予測の基盤になります。想定されるビジネスニーズに従ってデータセットを作成することは、重要なステップです。データセットの作成に使用するツールには、データフローを使用してデータセットの作成手順が組み込まれたデータセットビルダー、およびレシピを使用してデータのクリーンアップと変換を行うデータプレップがあります。
このモジュールでは、データセットを作成するためのベストプラクティスを説明し、受講者がこの両方のツールを使用したデータセットの作成に慣れていることを前提としています。ステップごとの手順に従い、データインテグレーションの実践的な演習に取り組むには、Trailhead の「CRM Analytics データインテグレーションの基本」モジュールを参照してください。
何に関するデータセットであるか?
あなたとチームは、Jose と Candace をサポートするために行った作業についてミーティングを行い、その結果、取引先別、所有者別、完了予定日別の金額など、すべて商談パイプラインの分析に関することであることがわかりました。
営業のデータは、商談、ケース、取引先、キャンペーンなどを含む Salesforce オブジェクトから取得されます。

データセットを作成するためのオプションとして、データセットビルダーがあります。

または、データプレップを使用したレシピもあります。

Jose と Candace が重点を置いているのは商談パイプラインであるため、新しいデータセットに対するアプローチの構成は次のようになります。
- 新しいデータセットの内容を定義する。商談オブジェクトとその項目を粒度として選択することにします。
- Jose と Candace が顧客取引先別にインサイトを分析できるように、取引先オブジェクトを商談にリンクする。このステップでは、取引先オブジェクトおよび取引先と商談で共有する項目である AccountId に基づいて選択した項目を追加します。
- Jose と Candace が商談所有者別の活動を表示できるように、ユーザーオブジェクトを商談にリンクする。このステップでは、ユーザーオブジェクトに加え、ユーザーと商談で共有する項目である OwnerId 項目に基づいて選択した項目を追加します。また、取引先オブジェクトとユーザーオブジェクトをリンクすることで、取引先所有者を追加することもできます。
必要な結果を得るためには、データセット間で適切なリレーションシップを確立することが重要です。データセットリレーションシップは、ルックアップまたは結合のいずれかとして実装することができます。ですが、両方の操作で同じ結論になるとは思わないでください。それぞれの変換で何が導き出されるのかを理解することが重要です。
データセットビルダーを使用したルックアップの作成
ここでいうルックアップとは、1 件の一致するレコードを見つけることです。この例では、商談と取引先が使用され、AccountId が両方のオブジェクト間の共通キーとなります。

レシピは、AccountId を一意の識別子とする 1 つの商談行から始まります。

この行では、取引先オブジェクト (ルックアップの右側) から、1 つの (唯一の) 一致する AccountId への「ルックアップ」が開始されます。一致する取引先レコードがその特定の AccountId に対して複数ある場合、ルックアップではランダムな 1 つのレコードが返され、1 つのルックアップではそれ以上は返されません。
データセットの精度の確保は、目的を達成するオブジェクトを粒度として選択することから始まるため、ルックアップタスクにおける各オブジェクトの役割を理解することが重要です。左側のオブジェクトは粒度を定義し、ルックアップの右側から取得される関連オブジェクトやデータセットから項目がさらに追加されるにつれて、一意性が維持されます。データセットの最終的な結果の例を次に示します。最小粒度として商談オブジェクトから始めたことを思い出してください。

商談データセットのすべての行が一意の商談であるため、行数と金額合計はどちらも真の値です。
![[行数] と [金額合計] のレンズ。](https://res.cloudinary.com/hy4kyit2a/f_auto,fl_lossy,q_70/learn/modules/best-practices-for-building-datasets-with-tableau-crm/create-lookups-with-the-dataset-builder/images/ja-JP/e3190a1823074f83f75afe5fd21d5e8b_kix.80onccyxpj2k.png)
粒度が重要である理由
右のデータセットが左のデータセットと比べて粒度が低い、または粒度が異なる場合、1 つのルックアップでどうなるかを見てみましょう。
商談から取引先へのルックアップを補強する、次のシナリオについて考えてみます。ルックアップは、1 つの取引先行 (左側) から複数の一致する商談 (右側) へと開始されます。
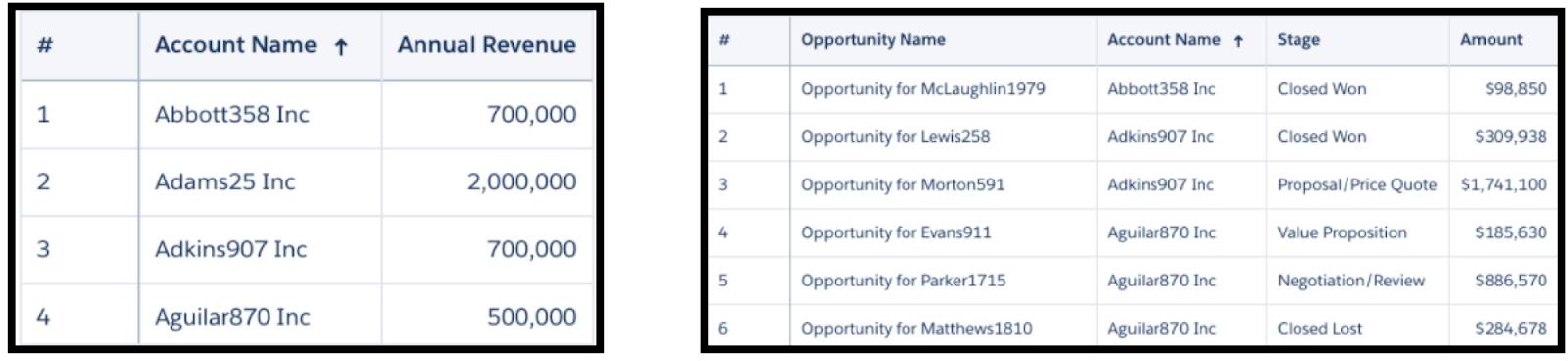
データセットを見ると、次のことがわかります。
- 商談データセットに、Abbott358 Inc に一致する商談行が 1 つある。
- 取引先 Adkins907 Inc に一致する商談行が 2 つある。
- Aguilar870 Inc に一致する商談行が 3 つある。
取引先データセットから商談データセットへの 1 つのルックアップの結果は、次のとおりです。

結果を確認してみましょう。
- 取引先 Abbot358 Inc については、1 つの一致する商談行が取得されました。
- 取引先 Adams25 Inc については、一致する商談行がなかったため、初期の粒度 (取引先 Adams25 Inc) が維持され、すべての商談の値が null または 0 になりました。
- 取引先 Adkins907 Inc については、(2 つのうち) 1 つの行のみが取得され、1 つの商談が失われました。
- 同様に、取引先 Aguilar870 Inc についても、(3 つのうち) 1 つの行のみが取得され、他の 2 つの商談の詳細が失われました。
そのため、粒度が異なる、または低いデータセットへのルックアップには十分注意する必要があります。このモジュールの後半では、もう 1 つの可能なアプローチとして、結合について説明します。
タスクまたは依頼に対応するデータ
ビジネスで使用する主なオブジェクトそれぞれに複数の「ベースレベル」のデータセットを使用しても、まったく問題ありません。たとえば、Cloud Kicks の場合、まず商談、ユーザー、取引先のベースデータセットが必要です。その後、データレイヤーで、またはダッシュボードレイヤーで必要に応じて、このデータセットをどのように組み合わせるかを決定します。
取引先別の商談や取引先別の商品といった問い合わせにユーザーが回答できるように、データセットを作成するよう依頼されているとしましょう。図 1 に示すように、いくつのベースオブジェクトが必要でしょうか。
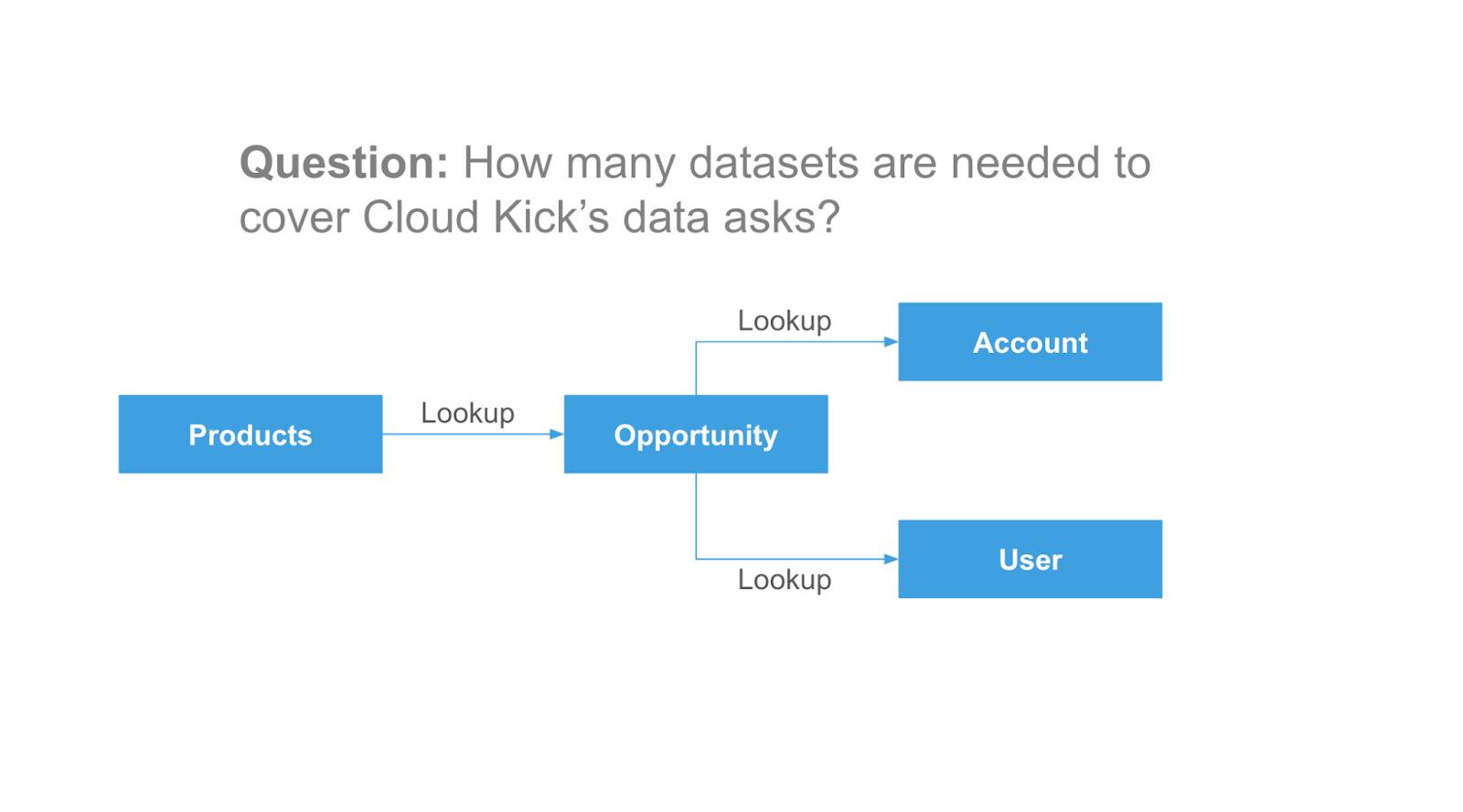 図 1: いくつのベースデータセットが必要ですか?
図 1: いくつのベースデータセットが必要ですか?
図 2 に示すように、4 つのベースレベルのデータセットがある場合、選択肢が増え、柔軟性も高まります。ユーザーが包括的な商品分析を求めている場合、赤い円は、商談、取引先、ユーザーの各データセットからのルックアップにより、関連データを使用して、どのように新しい商品データセットを作成できるかを示しています。
緑の円は、取引先とユーザーからのルックアップを使用する商談データセットに必要なデータセットを示しています。青い円はユーザーが基本的な分析をすべての取引先のみについて実行する場合の例であり、紫の円はユーザーのみについて実行する場合の例です。
 図 2: ほとんどのシナリオで使用される可能性のある 4 つのデータセット。
図 2: ほとんどのシナリオで使用される可能性のある 4 つのデータセット。
ユーザーがユーザーと取引先別のすべてのケースデータセットも要求している場合、図 3 のマゼンタの点線で示されているように、ベースデータセットの数は 5 つに増えます。
 図 3: ほとんどのシナリオに対応する 5 つのベースレベル。
図 3: ほとんどのシナリオに対応する 5 つのベースレベル。
まとめ
最小の粒度、つまりデータセットの内容から始めることで、一意の行を持つ正確な対象データセットを確保できます。ルックアップでは、最小の粒度からすべての行が返され、関連するデータセットから一致行が 1 つ返されます。粒度が異なるデータセット間でルックアップを使用する場合は、結果に歪みが生じないように、結果を評価してください。
リソース
- 動画: CRM Analytics Basic Concepts (CRM Analytics の基本概念)
- 動画: Creating Datasets (データセットの作成)
- 動画: Data Considerations and Introduction to Technical Terms (データに関する考慮事項および専門用語の紹介)
- 動画: Multi-value Lookup (複数値ルックアップ)