音声ユーザーインターフェースの設計方法の学習
学習の目的
この単元を完了すると、次のことができるようになります。
- 音声ユーザーインターフェース設計とその他のユーザーインターフェースの違いを認識する。
- 優れた会話型設計の主要な特徴を説明する。
音声ユーザーインターフェースとその他のインターフェースの比較
グラフィカルユーザーインターフェース (GUI) と比較すると、音声と会話には、エンドユーザーに選択肢が見えない場合に新たな課題があります。簡単な例として、旅行の計画があります。Web サイトを使ってオンラインで旅行を計画する場合の操作は極めてシンプルで、出発地、目的地、アクティビティ、日付を表す一連のボックスにデータを入力します。
一般的な自動電話システムでこれを行おうとすると、「国内旅行の場合は 1 を、海外旅行の場合は 2 を押してください。ハイキングをする場合は 3 を、サーフィンをする場合は 4 を押してください。」のようになります。これは現実的な方法でしょうか? いいえ。あまり現実的ではありませんね。ただし、これによって従来の自動化のいくつかの課題がよくわかります。
では、会話型インターフェースを見てみましょう。電話をかけて、人を相手にして旅行を設定する場合の会話は次のようになります。
- 旅行プランナー: 「次の旅行では何をなさいますか?」
- あなた: 「そうですね。ハワイでハイキングがしたいですね。」
- 旅行プランナー: 「面白そうですね! いつ、どこから出発しますか?」
- あなた: 「1 か月後ぐらいにシアトルから出発します。」
自然な応答が得られることと、予期しない入力に対応できることが、会話インターフェースが強力で直観的である要因です。Alexa を使用する場合、このような会話型インターフェースを作成することが、設計プロセスの一部であり、その設計と計画を明示的に行う必要があります。
では、どのようにして音声ユーザーインターフェースを作成するのでしょうか? 考慮すべき重要事項が多数あります。開始するにあたって、次のガイドラインを参考にしてください。
音声設計プロセスの理解
音声ユーザーインターフェースを設計するための最も重要な最初のステップは、スキルの目的を明確に設定することです。音声で何ができて何ができないかを知ることは、スキルの成功に不可欠です。何を行いたいかがはっきりした後に、スクリプトとフローを作成すると、インタラクションのさまざまな詳細やバリエーションを熟考するのに役立ちます。
このプロセスで重要なことは、人々が読み書きするように記述するのではなく、話すように記述することです。会話の両サイドを思い描き、声に出して読んで流れを確認します。
このトピックについての詳細は、『Alexa Design Guide (Alexa デザインガイド)』を参照してください。
ユーザーが言う可能性のある言葉の検討
会話型 UI はターンで構成されています。始めにユーザーが何かを言って、次に Alexa が応答します。多くの人にとってこれは新しい形式のインタラクションであるため、ユーザーが会話にどのように参加するかを認識して、それに合わせた設計を行う必要があります。優れた音声エクスペリエンスでは、ユーザーがさまざまな方法で意味やインテントを表現できます。
話を進める前に、ユーザーが Alexa と対話を行う際の重要な用語と概念を簡単に紹介しておきましょう。
設計プロセスで作成したスクリプトを使用して、予想される発話をインテントに分解できます。

この例の主要部分を簡単にまとめてみましょう。
- ウェイクワード — これは、Alexa が聞き始めるためのキーワードです。
- 起動フレーズ — ウェイクワードと呼び出し名をつなぐ言葉。サポートされているフレーズには、聞いて、教えて、開いて、起動して、実行して、開始して、などがあります。
- 呼び出し名 — これは、顧客がスキルを呼び出すために言うカスタムフレーズです。通常は 2 ~ 3 語の長さで、スキルの機能への関連性が高いものにします。
- 発話 — これは、ユーザーがスキルによってアクションを実行したいことを示す特定のフレーズです。
- ワンショット発話 — 上の例はワンショット発話です。ワンショット発話では一度にすべての情報が与えられ、インテントの実行に必要な条件が完全に満たされます。
- スロット値 — 発話の変数部分。この旅行計画シナリオでは、出発地、目的地、アクティビティ、日付がすべてスロット値です。
- インテント — スキルで処理できるアクション。1 つのインテントには、ユーザーが言う可能性があることに対応して、スロットありまたはなしの多くの異なる発話を設定できます。
ユーザーが言った内容を適切なインテントに対応付けるには、ユーザーが言う可能性のある発話のさまざまな種類の例を提供することが重要です。たとえば、部分的な情報、シノニム、ユーザーからの追加情報などを含めます。
- 来週の金曜日に旅行に行きたい。
- 来週の金曜日に行こうかと思う。
- 来週の金曜日にハイキングに行きたい。注意: この例では、ユーザーは日付に加えて、行いたいアクティビティの追加スロット値を提供しています。
これは、Alexa からの質問の答えにも当てはまります。たとえば、Alexa が確認のために「来週の金曜日にシアトルからハワイに行きたいのですね?」と言った場合、ユーザーは次のように答える可能性があり、それぞれ処理が異なります。
- いいえ、出発するのは 2 か月後です。
- いいえ、出発地はポートランドです。
- はい、その通りです。
プロのヒント: 適切なインテントを取得するために、可能性のある発話をすべてリストする必要はありませんが、多くの例をリストするほどスキルのパフォーマンスは向上します。
Alexa のレスポンスの計画
顧客に対する Alexa のレスポンスを設計するときに考慮すべきベストプラクティスがいくつかあります。たとえば、レスポンスは一息で言える程度の短さにする必要があります。レスポンスが長くなると、それを理解して返答するのが難しくなります。親戚の集まりで顔を合わせる、話が長い人を思い浮かべてください。こちらが言葉を挟む隙もありませんね。
また、本物の人間のように聞こえるレスポンスを作成することも大切です。言葉の短縮を使うのも OK ですよ。ただし、専門用語はロボットらしく聞こえるので使いすぎないようにしましょう。
オープンエンド型にしすぎないようにします。次に何をすればよいかがわからないと、ユーザーはスムーズにスキルを使用できません。ユーザーが次に何を言うべきかがわかるようなガイダンスを示して促します。
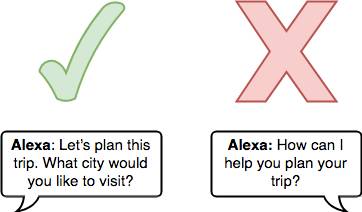
レスポンスにバラエティやちょっとしたユーモアを加えることを検討します。音声合成マークアップ言語 (SSML) を使用して、さまざまな休止、強調語、ささやきなどを追加する方法がいくつかあります。
また Alexa は、必要に応じてユーザーを促したり、まず、次に、最後にといった会話マーカーを提供する必要もあります。さらに、予期しない状況 (ユーザーが言った内容が聞こえなかったり理解できなかった場合など) に対するレスポンスも必要です。
音声設計が自然に聞こえるかを確認するための楽しいアクティビティは、Alexa としてロールプレイングを行うことです。これを行うには他に 2 人の人が必要です。1 人はユーザー役で、Alexa (あなた) と対話します。あなたの仕事は、スクリプトを使用して Alexa として返答することです。もう 1 人は書記役で、不自然に聞こえるレスポンスや予期されていなかったユーザーからの発話をメモします。
これは、音声ユーザーインターフェースの設計のほんの一角ですが、自然に聞こえるスキルを作成するための指針として役立てることができます。次は、スキル作成の実際の方法について説明します。