粒度
学習の目的
この単元を完了すると、次のことができるようになります。
- 粒度を定義する。
- 集計と粒度がデータにどのような影響を与えるかについて特定する。
粒度とは?
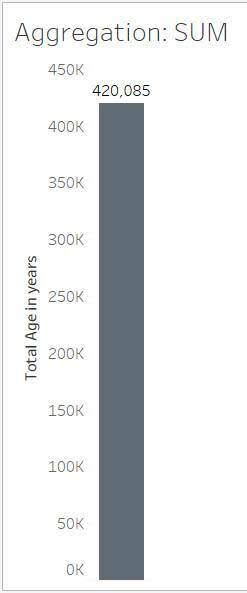
粒度とは、データの詳細度のことです。前の単元では、[年齢] 変数のすべての値が合計として集計された次の棒グラフを確認しました。この情報はあまり詳細なものではないため、粒度が低いということになります。
棒グラフは、完全に集計されたデータを表しており、データセット全体で 1 つの数値があります。ジッタープロットは、完全に集計が解除されたデータを表しており、各値をマークで示しています。ジッタープロットはより詳細であるため、棒グラフよりも粒度が高くなります。棒グラフは、集計レベルが高く、粒度が低くなります。ジッタープロットは、集計レベルが低く、粒度が高くなります。
|
|
|---|
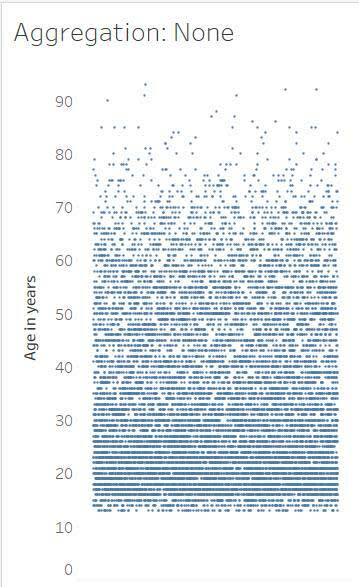
この集計を解除したデータは最も詳細なレベルを示すものであり、すべてのビジュアライゼーションの中で粒度が最も高くなります。「最も細かい詳細レベル」は、「適切に構造化されたデータ」モジュールで説明されているように、有意義なデータの特徴の 1 つです。
粒度の例
引き続き、粒度について学びましょう。フランチャイズ企業に関する情報を含むデータセットを使用して、粒度レベルを活用したデータみについて見ていきます。
このデータセットには 50,000 を超える行が含まれています。それぞれの行には、1 つの取引に関する情報が含まれています。粒度を低く (集計度を高く) すると、より大きなパターンを確認できます。粒度を高く (集計度を低く) すると、パターンの背後にある詳細を確認できます。
散布図とは、数値データ (量的変数) を縦横両方の軸にプロットして、複数の値の相関性や関係を見ることができる図のことです。この例では、散布図を使用して、ある企業の売上と利益の関係を見ていきます。
2 つの量的変数を使用した散布図を見る
まずは、次の散布図に表示されている量的変数である [Profit (利益)] と [Sales (売上)] を見てみましょう。
この時点では、1 つの数値 (売上) がもう 1 つの数値 (利益) に対してプロットされています。売上と利益は 1 つの数値 (売上の合計と利益の合計) に完全に集計されているため、この 2 つの数値は 1 つのデータポイント (マーク) のみと比較されています。
このデータはあまり詳細なものではないため、粒度が低いということになります。この企業の利益と売上を理解するには、データの粒度を高くする必要があります。

質的変数を追加した散布図を見る
質的変数を散布図に追加すると、データの粒度は高くなります。
[カテゴリ] 質的変数が色分けされたことで、データは販売された製品カテゴリごとに 3 つのマークに分割されるようになりました。1 つのマークの散布図よりも細かいですが、それでもより詳細にデータを確認したい場合があります。
次の散布図で、カテゴリ別の利益を見てみましょう。家具の利益は、他の 2 つの利益を下回っています。次のステップとしては、この傾向が地域別市場間でも当てはまるかどうかを調査し、粒度を追加するのが妥当です。

2 つ目の質的変数が追加された散布図を見る
質的変数である [Region (地域)] を次のビジュアライゼーションに追加すると、家具の収益率がすべての地域別市場において低いかどうかを確認できます。データソースにおける個々の地域の数とカテゴリの数を乗算して、散布図にマークを作成します。つまり、地域の数である 13 とカテゴリの数である 3 を乗算して、散布図に 39 のマークを作成します。
このデータでは、家具の利益の低さに関する潜在的な理由を確認するのに十分な粒度が得られており、 東南アジア地域で家具の利益がその他の地域より著しく低くなっていることがわかります。データの粒度を高め続けることで、この地域の家具の利益が赤字になっている理由についてさらに深く掘り下げることができます。

フィルター処理したデータを散布図で見る
東南アジア地域において、家具の利益が他の地域より著しく低くなっていることがわかりました。次は、この収益性の低さが 1 つか 2 つの取引によるものなのか、多くの取引において収益性が低くなっているのかを確認しましょう。
このデータセットには、すべての取引に対して 1 行のデータが含まれています。データの集計が解除されている場合、データセットのすべての取引に対して 1 つのデータポイント (マーク) が表示されます。ただし、データの集計を解除してこのレベルでの表示を行う前に、東南アジア地域での家具の取引だけを抽出するようにデータをフィルター処理します。
次の散布図では、フィルター処理されたデータに [Southeast Asia (東南アジア)] での家具の取引を示したマークが 1 つだけ含まれていることが示されています。


集計を解除したデータを見る
東南アジアでの家具の取引だけを表示するようにデータをフィルター処理したことで、データを最も高い粒度で確認できるようになりました。
データの集計を解除すると、選択したデータの各行の全データ値に対して、個別のマークが表示されます。次のビジュアライゼーションでは、東南アジアにおける個々の家具の取引に対して 1 つのマークが表示されています。このような形で粒度のレベルを調整することが重要な発見につながりました。それは、東南アジアにおける家具販売の取引の多くは収益性が低いということです。
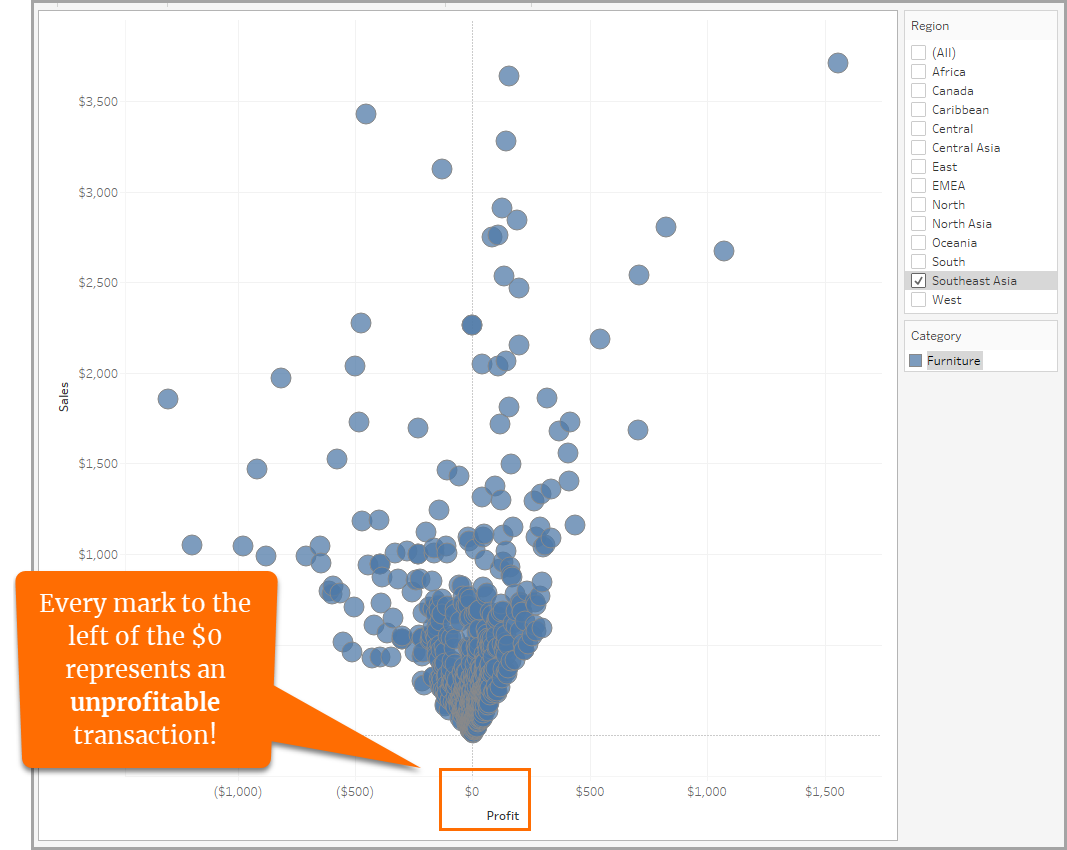
これで、事前定義された集計がデータに与える影響とさまざまなレベルの粒度がデータ分析に与える影響について学習できました。
リソース
- Tableau ヘルプ: 例: 散布図、集計、および粒度
- Tableau サイト: 無料トレーニングビデオ
- 外部サイト: Tableau Tutorials: How to Build a Jitter Plot (Tableau チュートリアル: ジッタープロットの作成方法)