Seguire il percorso delle risposte
Obiettivi di apprendimento
Al completamento di questa unità, sarai in grado di:
- Descrivere il percorso delle risposte.
- Spiegare la politica di non conservazione dei dati.
- Discutere dell'importanza del rilevamento del linguaggio tossico.

Rapido esame del percorso dei prompt
Puoi già vedere le fasi che Salesforce, con prudenza, attraversa con Einstein Trust Layer per proteggere i dati aziendali e dei clienti di Jessica. Prima di approfondire, rivedi rapidamente il percorso dei prompt.
- Un modello di prompt è stato estratto automaticamente da Risposte sul servizio per aiutare Jessica a risolvere il caso di assistenza di un suo cliente.
- Nel modello di prompt, i campi di unione sono stati precompilati con dati affidabili e protetti recuperati dall'organizzazione di Jessica.
- Per fornire maggiori informazioni di contesto per il prompt sono stati recuperati e inclusi articoli Knowledge e dettagli da altri oggetti.
- Le Informazioni personali (PII, Personally Identifiable Information) sono state mascherate.
- Sono state applicate salvaguardie aggiuntive per proteggere ulteriormente il prompt.
- Ora il prompt è pronto per attraversare il gateway sicuro per passare al Large Language Model (LLM) esterno.
Gateway LLM sicuro
Compilato con dati pertinenti e protetto da misure apposite, il prompt è pronto per attraversare il confine di Salesforce Trust, passando attraverso il gateway LLM sicuro per raggiungere gli LLM connessi. In questo caso, l'LLM a cui è connessa l'organizzazione di Jessica è OpenAI. OpenAI usa questo prompt per generare una risposta pertinente e di alta qualità che Jessica potrà utilizzare nella sua conversazione con il cliente.
Non conservazione dei dati
Se Jessica utilizzasse uno strumento LLM rivolto ai consumatori, ad esempio un chatbot bassato su IA generativa, senza un solido Trust Layer, il suo prompt, inclusi tutti i dati dei suoi clienti, e perfino la risposta dell'LLM, potrebbero essere archiviati dall'LLM per l'addestramento del modello. Tuttavia, un eventuale partenariato tra Salesforce e un LLM esterno basato su API deve essere soggetto a un accordo che tuteli la sicurezza dell'intera interazione, denominato non conservazione dei dati. La nostra politica di non conservazione dei dati prevede che nessun dato dei clienti, compresi il testo dei prompt e le risposte generate, sia archiviato all'esterno di Salesforce.

Ecco come funziona: il prompt di Jessica viene inviato a un LLM (ricorda che quel prompt è un'istruzione). L'LLM riceve il prompt e, seguendo le istruzioni che contiene e applicando le salvaguardie, genera una o più risposte.
Normalmente, OpenAI conserva i prompt e le relative risposte per un determinato periodo di tempo per verificare che non siano presenti di abusi. Gli LLM di OpenAI, che sono estremamente potenti, controllano se nei loro modelli si verifica qualcosa di inusuale, ad esempio attacchi di tipo Prompt Injection, come illustrato nell'unità precedente. Tuttavia, la nostra politica di non conservazione dei dati impedisce ai partner degli LLM di conservare qualsiasi dato incluso nell'interazione. Abbiamo stretto un accordo per cui siamo noi a gestire questo tipo di moderazione.
Non consentiamo a OpenAI di archiviare nulla. Pertanto, quando un prompt viene inviato a OpenAI, il modello dimentica sia il prompt sia le risposte non appena queste vengono restituite a Salesforce. Questo è importante perché permette a Salesforce di gestire la moderazione dei propri contenuti e degli abusi. Inoltre, gli utenti come Jessica non devono preoccuparsi del fatto che i fornitori di LLM conservino e utilizzino i dati dei loro clienti.
Percorso delle risposte
Quando abbiamo presentato Jessica, abbiamo detto che era un po' preoccupata all'idea che le risposte generate dall'IA potessero non corrispondere al suo livello di coscienziosità. Non sa bene cosa aspettarsi, ma non deve preoccuparsi perché questo aspetto è gestito da Einstein Trust Layer, che offre diverse funzionalità che contribuiscono a mantenere la conversazione personalizzata e professionale.

Finora, abbiamo visto che il modello di prompt della conversazione di Jessica con il suo cliente è stato compilato con dati rilevanti sul cliente e informazioni utili riguardo al contesto del caso. Ora, l'LLM ha assimilato quei dettagli e ha restituito una risposta inviandola all'interno del perimetro di Salesforce Trust. Tuttavia la risposta non è ancora pronta per essere utilizzata da Jessica: anche se il tono è amichevole e il contenuto accurato, deve comunque essere controllata dal Trust Layer per escludere la presenza di risultati indesiderati. Inoltre, la risposta contiene ancora blocchi di dati mascherati e Jessica la giudicherebbe troppo impersonale per poterla condividere con il suo cliente. Prima di condividere la risposta con Jessica, il Trust Layer deve ancora eseguire alcune operazioni importanti.

Buongiorno, <NAME_1>! È un piacere parlare con te. Mi dispiace delle difficoltà che stai riscontrando nel tentativo di aggiornare la tua carta di credito. Diamo molta importanza ai tuoi 5 anni e più di partnership con <COMPANY_1> e faremo del nostro meglio per risolvere il problema rapidamente.
Sì, in effetti esiste un punteggio di credito minimo richiesto* per alcune delle carte di credito che offriamo. Puoi dirmi qualcosa di più sul tipo di difficoltà che stai riscontrando nella procedura di richiesta?
Fonte: Requisiti minimi per gli aggiornamenti della carta Cumulus
Rilevamento del linguaggio tossico e rimozione del mascheramento dei dati
Accadono due cose importanti quando la risposta per la conversazione di Jessica viene ritrasmessa dall'LLM all'interno del perimetro di Salesforce Trust Boundary. Innanzitutto, il rilevamento del linguaggio tossico protegge Jessica e i suoi clienti dalla tossicità. Ti chiederai: "Di cosa si tratta?". Il Trust Layer utilizza modelli di machine learning per individuare e segnalare i contenuti tossici nei prompt e nelle risposte, classificandoli in cinque categorie: violenza, sesso, blasfemia, incitamento all’odio e aspetto fisico. Il punteggio complessivo è il risultato della combinazione dei punteggi di tutte le categorie rilevate e va da 0 a 1, in cui 1 corrisponde alla massima tossicità. Il punteggio assegnato alla risposta iniziale viene restituito insieme alla risposta all'applicazione da cui è stato richiesto inizialmente (in questo caso, Risposte sul servizio).
Successivamente, prima che la risposta generata venga condivisa con Jessica, il Trust Layer deve mostrare i dati mascherati a cui abbiamo accennato prima, per far sì che la risposta sia personale e pertinente rispetto al cliente di Jessica. Per rimuovere il mascheramento dei dati, il Trust Layer utilizza gli stessi dati tokenizzati che abbiamo salvato durante l'operazione di mascheramento iniziale. Una volta rimosso il mascheramento dei dati, la risposta viene condivisa con Jessica.
Inoltre, nella risposta noterai la presenza in calce di un link alla fonte. Creazione articolo Knowledge aggiunge credibilità alle risposte includendo link ad articoli provenienti da fonti utili.

Buongiorno, Dennis Maxfield! È un piacere parlare con te. Mi dispiace delle difficoltà che stai riscontrando nel tentativo di aggiornare la tua carta di credito. Diamo molta importanza ai tuoi 5 anni e più di partnership con Cumulus Financial e faremo del nostro meglio per risolvere il problema rapidamente.
Sì, in effetti esiste un punteggio di credito minimo richiesto* per alcune delle carte di credito che offriamo. Puoi dirmi qualcosa di più sul tipo di difficoltà che stai riscontrando nella procedura di richiesta?
Fonte: Requisiti minimi per gli aggiornamenti della carta Cumulus
Framework dei feedback
Ora, quando vede la risposta per la prima volta, Jessica sorride. È colpita dalla qualità e dal livello di dettaglio della risposta che ha ricevuto dall'LLM. È anche soddisfatta di quanto sia in linea con il suo personale stile di gestione dei casi. Mentre rilegge la risposta prima di inviarla al cliente, Jessica vede che può scegliere di accettarla così com'è, modificarla prima di inviarla o ignorarla.
Può anche lasciare un feedback sotto forma di “mi piace” o “non mi piace” e, se la risposta non le è stata utile, può specificare il motivo. Il feedback viene raccolto e, in futuro, potrà essere utilizzato in sicurezza per migliorare la qualità dei prompt.
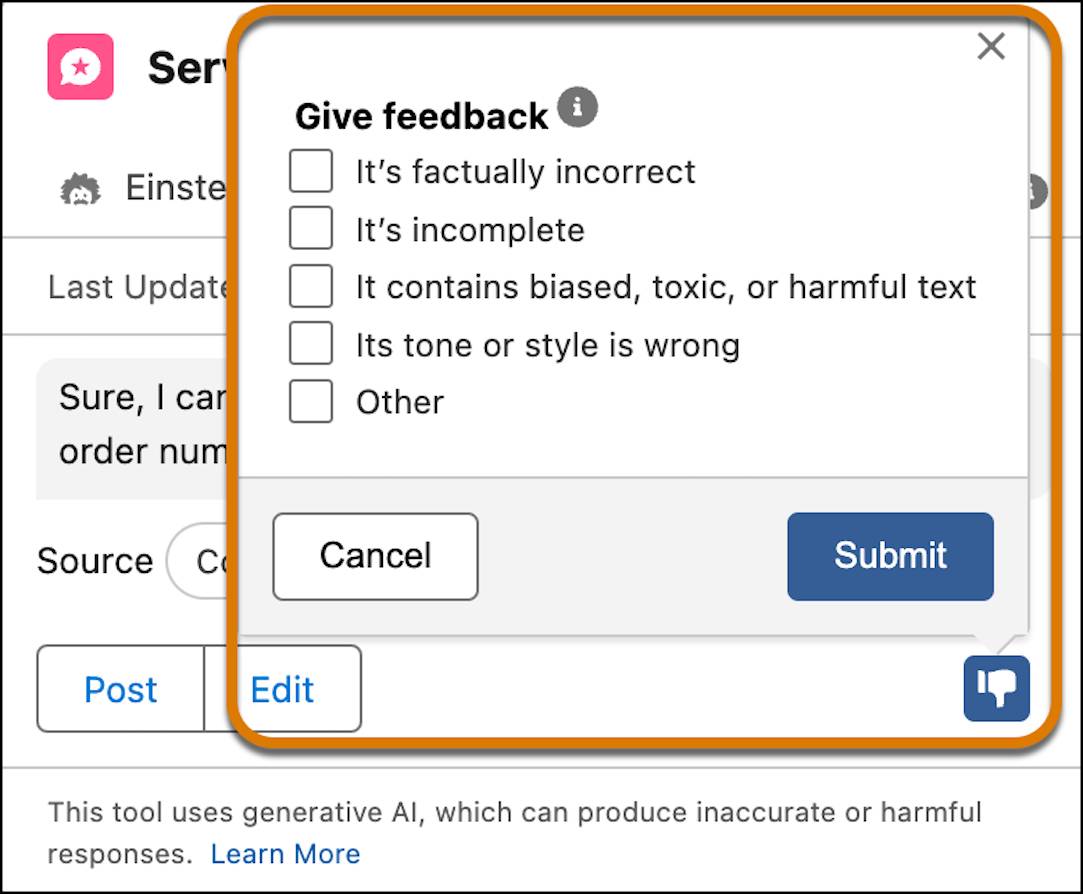
Audit Trail
C'è un ultimo aspetto del Trust Layer che devi conoscere. Ricordi la politica di non conservazione dei dati di cui abbiamo parlato all'inizio di questa unità? Dato che il Trust Layer gestisce internamente il punteggio e la moderazione del linguaggio tossico, teniamo traccia di ogni passaggio che avviene durante l'intero percorso dal prompt alla risposta.
Tutto ciò che viene alla luce nel corso dell'interazione complessiva tra Jessica e il suo cliente corrisponde a metadati con data e ora che noi raccogliamo in un audit trail, che include il prompt, la risposta originale non filtrata, eventuali punteggi relativi al linguaggio tossico e il feedback raccolto lungo il percorso. L'audit trail di Einstein Trust Layer aggiunge un livello di trasparenza per cui Jessica può essere certa che i dati del suo cliente sono protetti.

Sono successe molte cose da quando Jessica ha iniziato ad assistere il suo cliente, ma tutto è accaduto in un batter d'occhio. In pochi secondi, la sua conversazione è passata da un prompt richiamato da una chat, attraverso la sicurezza dell'intero processo del Trust Layer, fino a una risposta pertinente e professionale che può essere condivisa con il cliente.
Jessica chiude il caso sapendo che il cliente è soddisfatto della risposta ricevuta e dell'esperienza con l'Assistenza clienti. E, soprattutto, è contenta di poter continuare a usare la potenza dell'IA generativa di Risposte sul servizio, dato che sa con certezza che la aiuterà a chiudere i casi più velocemente e a soddisfare i suoi clienti.
Ciascuna delle soluzioni di IA generativa di Salesforce segue lo stesso percorso del Trust Layer. Tutte le nostre soluzioni sono sicure, quindi hai la certezza che i tuoi dati, come quelli dei tuoi clienti, sono al sicuro.
Complimenti: hai appena imparato come funziona Einstein Trust Layer! Per saperne di più su cosa fa Salesforce riguardo all'IA generativa, completa il badge Trailhead Creare intelligenza artificiale in modo responsabile.
Risorse
- Trailhead: Creare intelligenza artificiale in modo responsabile
- Guida di Salesforce: AI generativa Einstein e affidabilità