Création et empaquetage d’un kit de données
Objectifs de formation
Une fois cette unité terminée, vous pourrez :
- Créer un kit de données
- Empaqueter un kit de données
Utilité des kits de données
Examinons de plus près ce que sont les kits de données et pourquoi vous les utilisez.
Un kit de données est semblable à un conteneur spécial pour vos composants Data 360 que vous pouvez ensuite placer dans un package. L’utilisation des kits de données rationalise l’expérience d’empaquetage.
Avec les kits de données, vous pouvez :
-
Réutiliser des schémas via des modèles. En plaçant votre configuration Data 360 dans un kit de données, les collaborateurs et les utilisateurs peuvent facilement la réutiliser en déployant le kit de données dans leur propre organisation.
-
Déployer le kit de données vers plusieurs espaces de données dans la même organisation. Une fois le package avec le kit de données installé dans votre organisation, vous pouvez choisir vers quel espace de données de cette organisation le déployer.
-
Améliorer la flexibilité. Au lieu de modifier les métadonnées d’exécution, les mises à niveaux de package mettent à jour le modèle, permettant aux utilisateurs du package de conserver les éléments inchangés s’ils ne sont pas requis immédiatement.
Il existe des composants Data 360 que vous n’ajouterez pas dans votre kit de données. Pour savoir quels composants peuvent être placés dans un kit de données, consultez la matrice de préparation à l’extensibilité de Data 360. À noter que les métadonnées déployées à partir d’un kit de données ne peuvent pas être modifiées ou supprimées.
Avec les kits de données, les utilisateurs peuvent développer des solutions Data 360 de bout en bout et exhaustives, et déployer de façon sélective les métadonnées dans l’organisation d’un client.
Création d’un kit de données
Get Cloudy a configuré son organisation Dev Hub, son organisation d’espace de nom et son organisation test. À présent, il est temps de créer un kit de données.
Dans son organisation test, l’équipe de Get Cloudy crée des éléments Data 360 et les ajoute à un kit de données. Ce kit de données agit en tant que conteneur pour les fonctionnalités Data 360 que l’équipe souhaite inclure dans son application.
Regardons une vidéo sur la façon de créer et de charger un kit de données.
Nous supposons que vous êtes un développeur de packages disposant des autorisations nécessaires pour créer et installer des packages dans Data 360 . Si vous ne disposez pas des autorisations, aucun problème. Lisez simplement cette section pour savoir quelles actions votre administrateur réaliserait dans une instance de production. N’essayez pas de suivre ces étapes dans votre Trailhead Playground : Data 360 n’y est pas disponible par défaut. Avant de commencer, assurez-vous que Data 360 est activé pour les organisations test, comme décrit dans l’unité deux.
- Accédez à Data Cloud Setup (Configuration de Data Cloud) dans votre organisation test.
- Dans la zone Quick Find (Recherche rapide), recherchez Data Kits (Kits de données) et cliquez dessus.
- Cliquez sur New (Nouveau).
- Nommez votre kit de données et ajoutez une description facultative, puis cliquez sur Save (Enregistrer).
- Cliquez sur Add (Ajouter) à partir de la section Data Streams Bundles (Paquets de flux de données).
- Sélectionnez ensuite le type de connecteur en fonction de la source de données prise en charge.
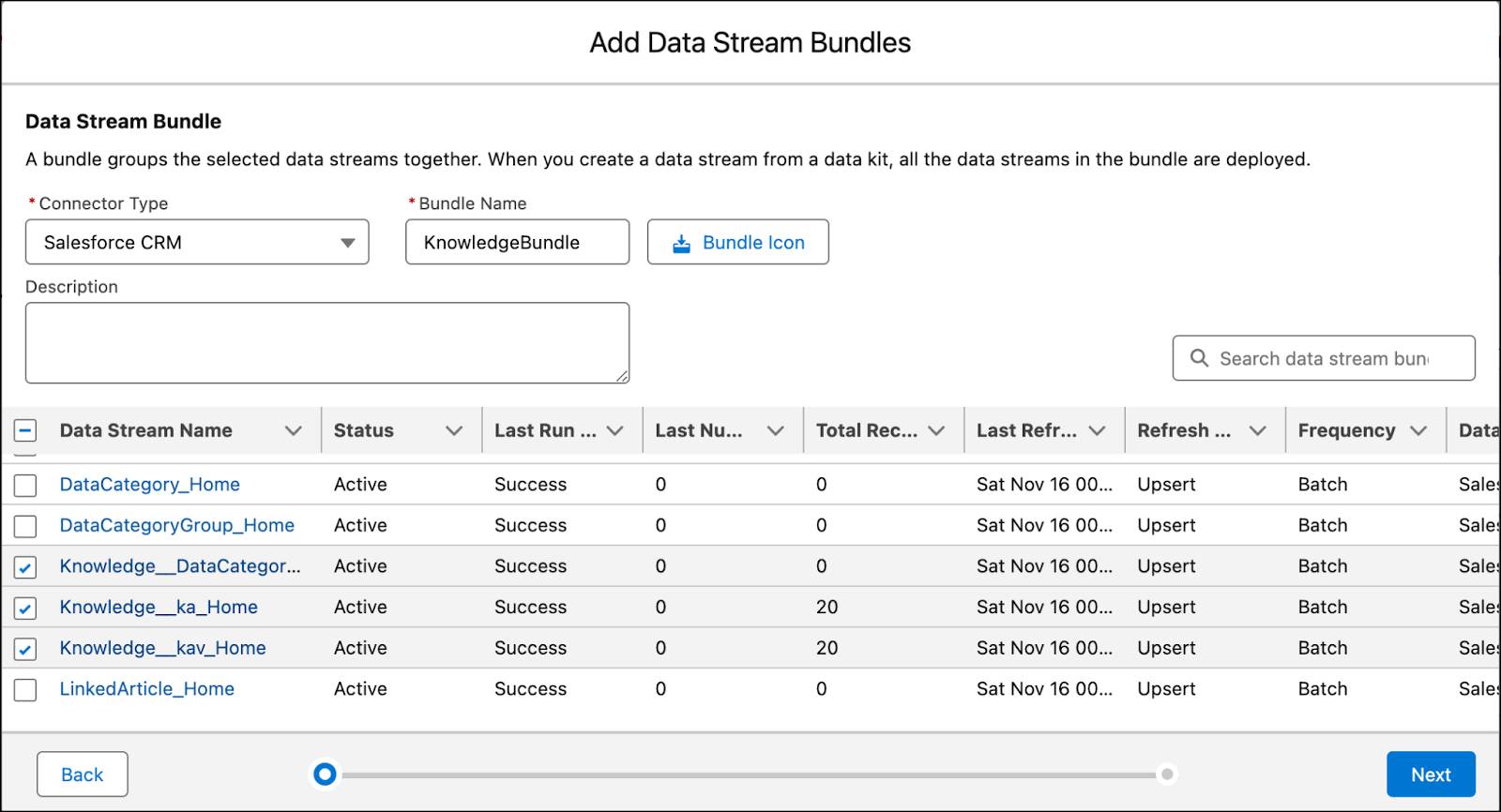
- Ajoutez un nom de paquet (sans espace) et une inscription facultative.
- Sélectionnez les flux de données que vous souhaitez empaqueter, puis cliquez sur Next (Suivant).
- Ajoutez un modèle de données si vous le souhaitez, puis cliquez sur Save (Enregistrer).
- Ajoutez des connaissances calculées si vous le souhaitez, puis cliquez sur Save (Enregistrer).
- Ajoutez des composants supplémentaires si vous le souhaitez.
Ensuite, l’équipe de Get Cloudy doit examiner l’ordre dans lequel les composants doivent être déployés. Cela s’appelle la séquence de publication.
Accédez à l’onglet Publishing Sequence (Séquence de publication) et examinez l’ordre de publication automatiquement généré. Cet ordre est généré en fonction de la date de création de chaque composant dans le kit de données.
Création d’un package géré avec le kit de données
L’équipe Get Cloudy a créé avec succès son kit de données. Maintenant, il est temps de l’empaqueter !
Dans le projet Salesforce DX, l’équipe Get Cloudy récupère les métadonnées des données en référençant le fichier package.xml téléchargé à partir de l’interface utilisateur. Lors de la récupération des métadonnées du kit de données, celles-ci doivent se trouver dans un dossier de projet indépendant séparé des autres types de métadonnées, telles que les ensembles d’autorisations, les objets personnalisés et Apex.
Ensuite, déterminez si une dépendance au package SSOT Data 360 est nécessaire. SSOT contient les objets modèle de données principaux qui alimentent Data 360. Si les DMO de votre package ont des relations avec Individu unifié ou d’autres DMO avec un préfixe ssot__ dans le nom d’API, votre projet a une dépendance et vous devez ajouter ce qui suit à votre sfdx-project.json.
{
"packageDirectories": [
{
"versionName": "ver 0.1",
"versionNumber": "0.1.0.NEXT",
"path": "data-app",
"default": false,
"package": "yourDCPackage",
"versionDescription": "My data kit extension package",
"dependencies": [
{
"package": "04t5Y0000015oSB"
}
]
}
]
}Ensuite, créez un package géré Salesforce qui pointe vers le dossier de métadonnées de votre kit de données.
sf package create -n PACKAGE_NAME -t Managed -v DEVHUB_ALIAS -p PATH_TO_DATA_KIT
Lorsque le package géré est créé, il génère un identifiant 0ho. Copiez cet identifiant. Ensuite, créez une version du package géré à l’aide de cet identifiant 0ho.
sf package version create -v DEVHUB_ALIAS -k INSTALLATION_KEY -p 0ho_ID -w 45 -f config/project-scratch-def.json
Ce processus peut durer quelques minutes et renverra un identifiant 04t indiquant la version du package. La version du package sera une version bêta, ce qui signifie qu’il pourra uniquement être installé dans les organisations test. Une fois que vous avez vérifié la fonctionnalité du package bêta, vous pouvez exécuter sf package version promote -v DEVHUB_ALIAS -p 04t pour créer une version installable sur les organisations Developer Edition et de production.
Collaboration
L’équipe Get Cloudy a créé et empaqueté un kit de données. Elle a ensuite validé les modifications apportées à son système de contrôle de version et envoyé les mises à jour à GitHub, sa plate-forme d’hébergement de référentiels, pour collaborer avec d’autres développeurs.
D’autres développeurs peuvent télécharger le projet et déployer le kit de données dans une organisation test pour apporter des modifications supplémentaires. Ils répètent ensuite le processus. Les nouveaux développeurs ajoutent les nouvelles et anciennes fonctionnalités à un nouveau kit de données, récupèrent les métadonnées du kit de données dans leur propre projet, puis chargent le projet dans leur plate-forme d’hébergement de référentiels.
Ressources
- Aide Salesforce : Package et kits de données dans Data 360
- Développeur Salesforce : Empaquetage des composants de métadonnées Data 360
- Développeur Salesforce : Matrice de préparation à l’extensibilité de Data 360