Mappage des objets requis
Objectifs de formation
Une fois cette unité terminée, vous pourrez :
- Reconnaître les composants du modèle de données Customer 360
- Décrire les objets d’individu, de point de contact et de partie
- Identifier les exigences de mappage pour les jeux de règles de résolution de l’identité
Composants du modèle de données Customer 360
Pour mieux comprendre les exigences relatives aux concepts de données et d’identité, nous devons passer en revue le modèle de données Customer 360. Le modèle de données Customer 360 est le modèle de données standard de Data 360 qui assure l’interopérabilité des données. Autrement dit, il permet d’utiliser les données partout où vous en avez besoin. La compréhension des différents composants du modèle de données Customer 360 peut faciliter les tâches de mappage des données et de création de jeux de règles de résolution de l’identité. Revenons rapidement sur les différentes étapes.
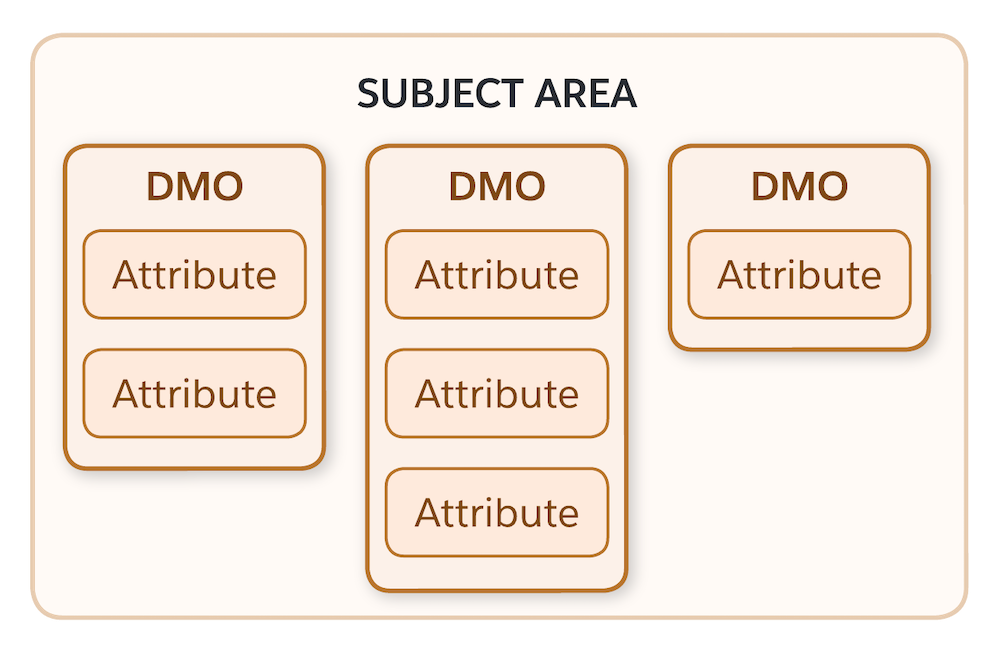
Domaine (objectif commercial)
Le modèle de données Customer 360 regroupe des domaines ou des modèles de données selon les objectifs commerciaux. Ces objectifs peuvent être de commercialiser ou de promouvoir votre produit, ou de fournir un support produit fluide à vos clients. Les domaines du modèle de données peuvent inclure un groupe d’identificateurs uniques appelé partie, ou peuvent être des données d’engagement, des commandes client ou des informations sur les produits.
Objet de modèle de données (groupe de données)
Il s’agit d’un objet dans le modèle de données qui a été créé par les flux de données et les informations ingérés. Les objets de modèle de données peuvent être de type standard ou personnalisé, en fonction des besoins de votre entreprise. Un objet de modèle de données stocke des données telles que des pistes, des informations sur les produits, des informations sur les clients, et bien d’autres.
Attributs (données relatives à vos contacts)
Les attributs représentent des éléments d’information uniques dont vous disposez sur un contact donné, issus de plusieurs sources. Ces informations vous aident à lier les données d’un individu et, à terme, à créer un profil unifié du client. Pour les marketeurs, ces points de données sont très précieux, car ils peuvent être utilisés afin de créer des segments plus précis. Par exemple, si vous voulez envoyer un bon de réduction à tous les contacts de moins de 25 ans qui préfèrent l’haltérophilie à la course à pied. Pour ce faire, vous avez besoin de données sur l’âge et sur les préférences d’activité dans votre instance Data 360.

Importance du mappage de données
Maintenant que nous avons revu les points importants, il est temps de passer aux choses sérieuses. Pour créer des profils unifiés, vous devez impérativement mapper correctement vos données. Data 360 est comparable à l’intelligence artificielle (IA), dans la mesure où son efficacité repose sur des données de qualité et une certaine intervention humaine.
Avec Data 360, le système ne peut unifier les profils que s’ils sont correctement mappés avec l’objet Individu et avec un autre élément : un objet point de contact ou un objet identificateur de partie.
Commençons par aborder la première option requise, l’objet Individu.
Objet Individu
L’objet Individu est le plus important, car il contient toutes les informations personnelles dont vous disposez sur votre client. Ces données peuvent provenir de tous types de sources (des données commerciales aux publications sur les réseaux sociaux). Concrètement, chaque flux de données ajouté doit disposer d’un champ connecté au champ d’ID d’individu afin de créer un profil d’individu unifié. C’est nécessaire pour la résolution de l’identité.
Répétons-le encore une fois pour insister.
Tous les flux de données contenant des informations client doivent disposer d’un champ mappé avec le champ ID d’individu de l’objet Individu afin d’utiliser la résolution de l’identité.
Relations et mappages requis
Dans notre exemple relatif à la source de données du programme de fidélité NTO, SubscriberKey est le champ mappé avec l’ID d’individu. L’ID d’individu est l’attribut le plus important pour les jeux de règles de résolution de l’identité. Il sert de clé primaire pour l’objet Individu, et est requis pour le mappage et la résolution de l’identité. Dans votre flux de données, le champ qui constitue l’identificateur unique de ce client doit être mappé avec cet ID. Voici les options et exigences spécifiques en matière de mappage pour l’objet Individu.
Objet de modèle de données |
Attributs |
Noms d’API |
Mapper avec |
|---|---|---|---|
|
Individuelle
|
|
|
|
Vous pouvez également mapper des champs supplémentaires de vos données client avec les attributs standard et personnalisés associés à l’objet Individu. Par exemple, vous pouvez mapper des informations telles que la date de naissance, le prénom, le nom de famille, etc.
Vous devez non seulement mapper toutes les données client avec le champ ID d’individu, mais vous devez également mapper vos données avec un autre objet. Passons en revue vos options.
Objets Point de contact
Les points de contact (des informations telles que l’adresse e-mail, le numéro de téléphone, l’adresse, l’appareil et le réseau social) sont tous associés à des objets qui peuvent être utilisés pour la résolution de l’identité. Ces informations représentent des données spécifiques relatives à une personne, qui peuvent changer ou varier selon les systèmes. Comme l’ID d’individu, un ID de point de contact sert de clé primaire pour l’objet Point de contact, et est requis pour le mappage et la résolution de l’identité. Dans votre flux de données, le champ qui constitue l’identificateur unique de ce client doit être mappé avec cet ID. Passons en revue ces exigences en matière d’objet.
Objet de modèle de données |
Attributs |
Noms d’API |
Mapper avec |
|---|---|---|---|
|
Adresse du point de contact
|
|
|
|
|
Application du point de contact
|
|
|
|
|
Adresse e-mail du point de contact
|
|
|
|
|
Téléphone du point de contact
|
|
|
|
Objet Identification de partie
Pour finir, voici l’objet Identification de partie. La correspondance d’identificateur de partie vous permet d’utiliser vos propres identificateurs fournis par le client. La mise en correspondance en fonction d’un identificateur de partie est particulièrement importante avec les paquets de données Marketing Engagement. Les paquets de données comprennent des sources de données contenant des données relatives aux abonnés (telles que des métriques d’engagement) qui sont associées à un ID d’abonné ET des extensions de données contenant également des informations client. Si vous décidez d’effectuer une correspondance en fonction de l’identificateur de partie, vous devez également mapper d’autres types d’attributs.
Pour obtenir la liste des paquets de données actuellement disponibles pour d’autres produits Salesforce, consultez la documentation Paquets de données de démarrage dans le guide de référence de Data 360.
-
ID d’identification de partie : comparable aux ID d’individu et de point de contact, l’ID d’identification de partie est la clé primaire ou l’identificateur principal provenant de vos données client. Il peut s’agir de n’importe quel ID unique.
-
Partie : cet ID est une clé étrangère identique à celle utilisée dans l’objet Individu.
-
Type d’identification de partie : il s’agit d’un champ obligatoire pour le mappage, mais facultatif pour la résolution de l’identité. Ce champ fournit des informations supplémentaires sur l’identificateur (sur les réseaux sociaux, par exemple). Soyez précis, car il est utilisé pour configurer vos règles de correspondance.
-
Numéro d’identification : il s’agit de l’ID utilisé pour comparer la résolution de l’identité.
-
Nom d’identification : comparable au type, ce champ obligatoire est utilisé pour indiquer le nom de l’espace d’ID, par exemple l’ID mobile ou l’ID LinkedIn. Ce nom étant également utilisé dans la configuration des règles de correspondance, soyez précis.
-
Attributs standard et personnalisés : mappez tous les champs supplémentaires de vos données client avec les attributs standard et personnalisés associés à l’identificateur de partie.
Prenons un exemple utilisant un permis de conduire comme identificateur unique.
ID d’identification de partie |
Partie |
Type d'identification de partie |
Numéro d’identification |
Nom d’identification |
|---|---|---|---|---|
100a |
10016-00001 |
Permis de conduire |
D1469256 |
Permis du conducteur CA |
Voici un résumé des mappages requis pour l’identification de partie.
Objet de modèle de données |
Attributs |
Noms d’API
|
Mapper avec |
|---|---|---|---|
|
Identification de partie
|
|
|
|
Relations de partie
Pour permettre l’unification entre les espaces d’ID, l’objet Identification de partie dispose d’une cardinalité de relation Plusieurs à un, ce qui signifie simplement que vous pouvez mapper plusieurs champs de partie avec un seul objet Individu. Dans cet exemple, on trouve trois types d’identifications de partie : une provenant de LinkedIn, une autre intitulée Contact ID (ID de contact) et une clé d’abonné Agentforce Marketing. Les trois types d’identifications sont possibles, ce qui entraîne la cardinalité de Plusieurs à un.
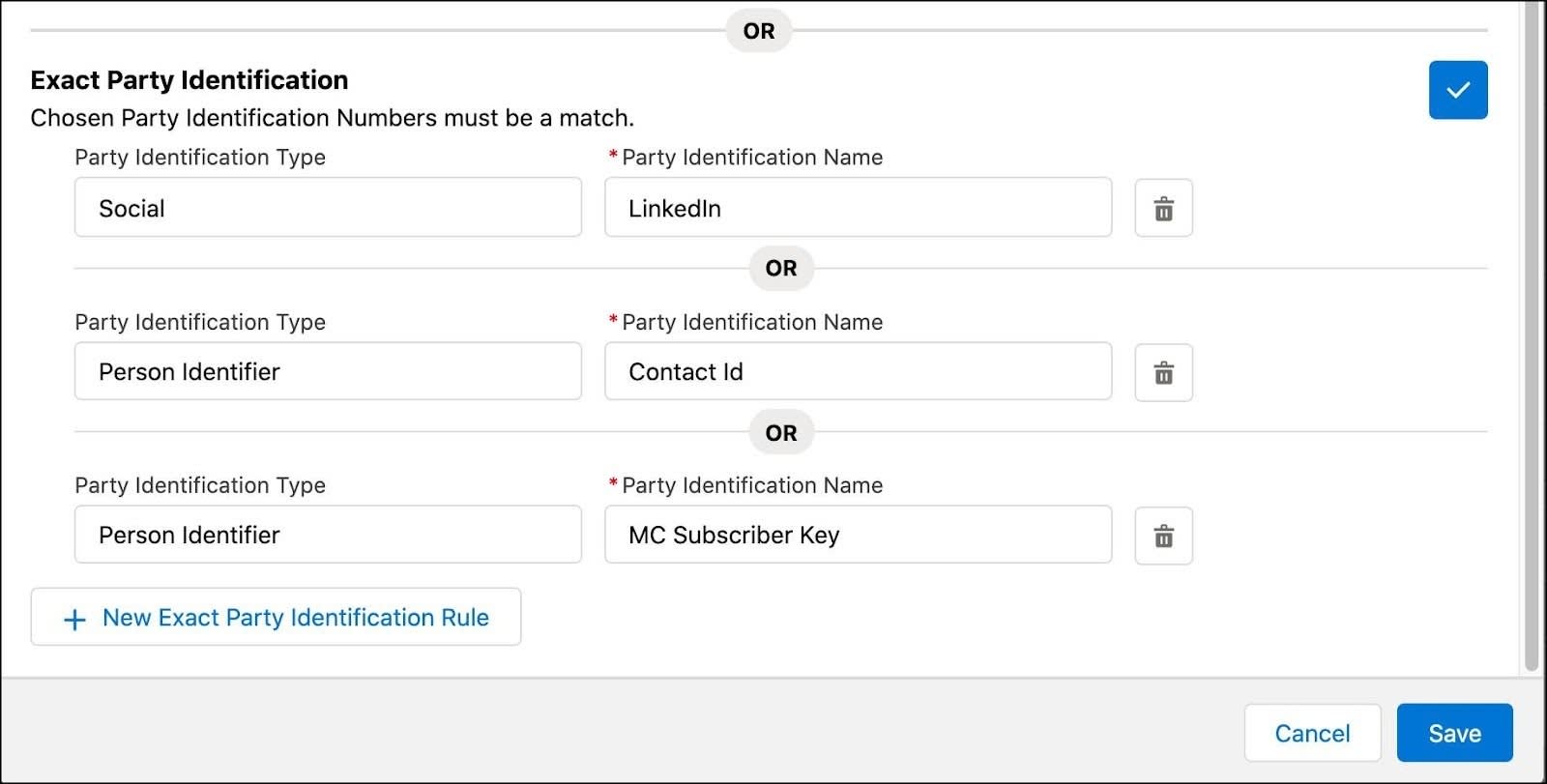
Étant donné que de nombreux systèmes utilisent des identificateurs, vous pouvez facilement les ajouter à vos règles de correspondance après le mappage et la configuration. Veillez simplement à noter les types et noms que vous choisissez pour faciliter la configuration.
Exemple de mappage de données
Pour vous aider à visualiser ce processus, prenons l’exemple du mappage des données issues du modèle de données de Northern Trail Outfitters (NTO). Dans cet exemple, le flux de données, NTO Loyalty Program (Programme de fidélité de NTO) (1), est mappé avec l’objet Individual (Individu) (2) et avec l’objet Contact Point Phone (Téléphone du point de contact) (3). NTO a créé ce mappage afin d’utiliser les numéros de téléphone comme règle de correspondance.
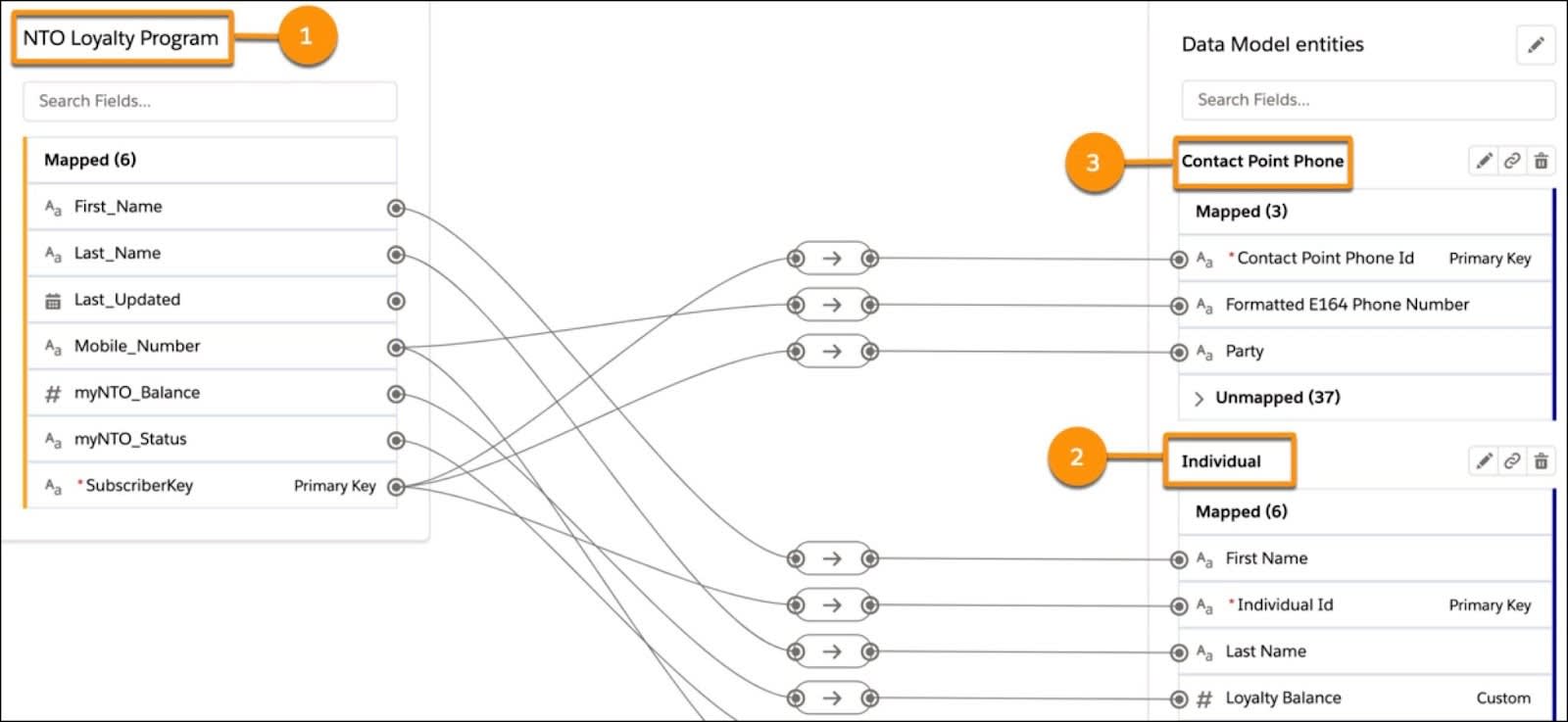
Dans ce mappage, trois mappages sont requis (identifiés comme clés primaires). Dans le cadre de notre exemple, ces clés primaires sont les suivantes :
- SubscriberKey
- Contact Point Phone ID (ID du téléphone du point de contact)
- ID d'individu
Vous remarquerez également que SubscriberKey de la source de données est mappée avec les autres clés primaires et la partie. Pourquoi la partie ? Parce que le champ de partie permet d’indiquer une relation entre les objets et les clés primaires trouvés dans les sources de données.
À suivre : Jeux de règles de résolution de l’identité
Maintenant que vous avez saisi l’importance du mappage, nous allons aborder dans l’unité suivante le concept des jeux de règles de résolution de l’identité.
Ressources
- Aide Salesforce : Domaine de partie
- Aide Salesforce : Modèle de données Customer 360 : individu et points de contact
- Aide Salesforce : Exigences en matière de modélisation de données pour la résolution de l’identité
- Salesforce Developers : Données du modèle