Étude des phases d’ingestion et de modélisation de données
Objectifs d’apprentissage
Après avoir terminé cette unité, vous pourrez :
- Examiner comment les données sont ingérées dans Data Cloud
- Configurer les qualificateurs de clé pour faciliter l’interprétation des données ingérées
- Appliquer les concepts de base de modélisation des données à votre compte
Ingestion de données
Dans la présentation, nous avons indiqué que les données sont d’abord ingérées à partir de la source et stockées dans un objet lac de données dans notre système. Cependant, nous ne sommes pas entrés dans les détails concernant la façon dont vous connectez les données et y accédez dans le système source. Les données sont récupérées à partir de la source au moyen de connecteurs qui établissent la communication entre les serveurs, afin que vos données soient accessibles en permanence. Les flux de données aident les connecteurs dans la mesure où ils déterminent le moment où les connexions doivent être établies et la fréquence à laquelle elles doivent l’être.
Les connecteurs suivants sont actuellement disponibles pour les utilisateurs de Data Cloud, et de nombreux autres connecteurs sont prévus à l’avenir.
- Connecteur de stockage sur le Cloud
- Connecteur Google Cloud Storage
- Connecteur B2C Commerce
- Connecteur Marketing Cloud Personalization
- Sources de données et connecteur Marketing Cloud Engagement
- Connecteur Salesforce CRM
- Connecteur d’applications Web et mobiles
Voyons cela de plus près.
Connecteur de stockage sur le Cloud
Cette option crée un flux de données à partir des données stockées à un emplacement Amazon Web Services S3. Le connecteur prend en charge des jeux de données personnalisés et vous avez la possibilité de récupérer des données toutes les heures, tous les jours, toutes les semaines ou tous les mois. Comme pour les jeux de données personnalisés, le connecteur effectue l’étape d’importation et vous mappez ensuite les données au modèle.
Pour n’importe lequel de ces connecteurs, l’onglet Refresh History (Historique d’actualisation) est utile pour vérifier que les données sont récupérées à la cadence attendue et sans erreurs. En cas d’erreur de récupération, la colonne Status (Statut) (visible dans l’image suivante) fournit plus d’informations sur l’erreur,

Connecteur Google Cloud Storage
Ce connecteur ingère les données de Google Cloud Storage (GCS), un service Web de stockage en ligne fondé sur des fichiers qui repose sur l’infrastructure Google Cloud Platform. Data Cloud lit les données depuis votre compartiment GCS et effectue régulièrement un transfert automatisé de données d’objets actifs vers un environnement de transfert appartenant à Data Cloud destiné à la consommation de données.
Connecteur B2C Commerce
Ce connecteur ingère les données d’une instance B2C Commerce et crée un flux de données B2C Commerce.
Connecteur Marketing Cloud Personalization
Ce connecteur vous aide à ingérer des profils utilisateur et des événements comportementaux de Marketing Cloud Personalization dans Data Cloud. Vous pouvez également utiliser Marketing Cloud Personalization comme cible d’activation. Vous devez créer un paquet de démarrage pour ce connecteur.
Sources de données et connecteur Marketing Cloud Engagement
Data Cloud fournit des paquets de données de démarrage qui comprennent des jeux de données prédéfinis pour la messagerie et les appareils mobiles (y compris les données d’engagement Einstein). Étant donné qu’il s’agit de tables système connues, ces paquets vous guident depuis l’importation du jeu de données tel quel jusqu’à son introduction automatique dans la couche de modèle de données. En quelques clics, vous êtes ainsi prêt à travailler sur vos cas d’utilisation commerciaux. Les jeux de données comportementales et orientées sur l’engagement récupérés par ces connecteurs sont actualisés toutes les heures ; les jeux de données de profil sont actualisés quotidiennement.
Vous pouvez également accéder à des jeux de données personnalisés à l’aide d’extensions de données Marketing Cloud Engagement. Par exemple, vous pouvez utiliser ce connecteur pour ingérer des données de commerce digital ou d’enquêtes que vous avez déjà importées dans Marketing Cloud Engagement. Provisionnez simplement votre instance Marketing Cloud Engagement dans Data Cloud, après quoi vous verrez la liste des extensions de données qui peuvent être importées. Selon la manière dont vous choisissez d’exporter votre extension de données depuis Marketing Cloud Engagement (actualisation complète ou données nouvelles/mises à jour uniquement), les données seront récupérées quotidiennement par le connecteur pour la première option ou toutes les heures pour la seconde option. Gardez à l’esprit que contrairement aux paquets de données de démarrage, qui importent et modélisent les données pour vous, avec ce connecteur, vous devez effectuer l’étape de modélisation vous-même, car le jeu de données est personnalisé.
Données Salesforce CRM
Une fois que vous avez authentifié votre instance Sales Cloud et Service Cloud, vous pouvez choisir un objet par flux de données à connecter à votre compte Data Cloud, en le sélectionnant dans une liste d’objets disponibles ou en effectuant une recherche. Les données sont actualisées toutes les heures et une actualisation complète a lieu une fois par semaine.
Connecteurs Web et mobiles
Ce connecteur capture les données en ligne des sites Web et des applications mobiles. Data Cloud propose des mappages de données canoniques pour les instances Web et mobiles afin de faciliter l’ingestion, que vous pouvez ensuite interroger et exploiter pour les appareils mobiles et la messagerie.
API Ingestion
Si vous souhaitez personnaliser la façon dont vous vous connectez à d’autres sources de données, vous pouvez utiliser l’API Ingestion pour créer un connecteur, charger votre schéma et créer des flux de données dans votre organisation. Ces flux peuvent être mis à jour de manière incrémentielle ou en masse, selon la manière dont vous configurez vos requêtes API.
Extension de vos données
Les connecteurs extraient la forme originale des données en récupérant la liste complète des champs sources, et vous pouvez créer des champs calculés supplémentaires si vous le souhaitez. Par exemple, si le connecteur récupère un champ d’âge sous forme de nombre brut et que vous souhaitez répartir les données en tranches d’âge telles que 18 à 24 ans, 25 à 34 ans, 35 à 44 ans, 45 ans et plus, vous pouvez y parvenir en ajoutant une nouvelle formule. La formule est une combinaison d’instructions IF ainsi que d’opérateurs <and, or> à l’objet lac de données dérivé du champ d’âge source.
Il existe plusieurs fonctions de formule que vous pouvez utiliser. Elles se divisent en quatre catégories.
- Manipulation de texte
- Par exemple : EXTRACT(), FIND(), LEFT(), SUBSTITUTE()
- Conversions de types
- Par exemple : ABS(), MD5(), NUMBER(), PARSEDATE()
- Calculs de dates
- Par exemple : DATE(), DATEDIFF(), DAYPRECISION()
- Expressions logiques
- Par exemple : IF(), AND(), OR(), NOT()
Configuration des qualificateurs de clé
Utilisez des clés qualifiées complètes (FQK) pour éviter les conflits de clés lorsque les données provenant de différentes sources sont ingérées et harmonisées dans le modèle de données Data Cloud. Chaque flux de données est ingéré dans Data Cloud avec ses clés et attributs spécifiques. Lorsque plusieurs flux de données sont harmonisés en un seul objet modèle de données, les différentes clés peuvent entrer en conflit et les enregistrements peuvent avoir les mêmes valeurs de clé. Les clés qualifiées complètes évitent les conflits en ajoutant des champs de qualificateurs de clé et en interprétant les données avec précision. Une clé qualifiée complète se compose d’une clé source, telle qu’un ID de contact de CRM ou une clé d’abonné de Salesforce Marketing Cloud Engagement, et d’un qualificateur de clé.

Configurez les champs de qualificateur de clé pour tous les champs d’objet lac de données qui contiennent une valeur clé. Le champ peut être destiné à une clé principale ou à une clé étrangère. Voyons, à l’aide d’un exemple, comment les données harmonisées sont interprétées avec et sans qualificateur de clé.
Supposons que vous disposiez de deux flux de données avec des objets lac de données associés pour les données de profil : objet lac de données Contacts de Salesforce CRM et objet lac de données Subscribers (Abonnés) de Salesforce Marketing Cloud Engagement. Les enregistrements de ces objets lac de données sont mappés à l’objet modèle de données Individual (Individu).
Maintenant, vous souhaitez joindre l’objet modèle de données Individual (Individu) à l’objet modèle de données Engagement afin d’identifier les individus qui ont réalisé au moins deux clics. Après harmonisation des données, les deux flux de données sont mappés à l’objet modèle de données Individual (Individu) dans Data Cloud. L’objet lac de données Contacts a trois enregistrements et l’objet lac de données Subscribers (Abonnés) en a deux. Ainsi, l’objet modèle de données Individual (Individu), qui contient tous les enregistrements de tous les flux de données mappés, comporte cinq enregistrements.
Marketing Cloud Engagement utilise l’ID de contact de l’organisation CRM comme clé principale (clé d’abonné). Ainsi, il existe plusieurs enregistrements dans l’objet modèle de données Individual (Individu) avec la même valeur pour l’ID d’individu, c’est-à-dire le champ de clé principale.

Examinons ensuite l’objet modèle de données Email Engagement (Engagement par e-mail), qui contient des données d’engagement par e-mail ingérées à partir de Salesforce Marketing Cloud Engagement. L’objet modèle de données Individual (Individu) et l’objet modèle de données Email Engagement (Engagement par e-mail) entretiennent une relation de type 1:N par le biais de l’ID d’individu.
Lorsque vous connectez l’objet modèle de données Individual (Individu) et l’objet modèle de données Email Engagement (Engagement par e-mail), Data Cloud interprète le jeu de données combiné comme la première ligne d’Individual 2 (Individu 2) correspondant à un clic et la deuxième ligne d’Individual 2 (Individu 2) correspondant à un clic. En d’autres termes, nous supposons que Individual 2 (Individu 2) a effectué deux clics sur l’e-mail. En réalité cependant, Individual 2 (Individu 2) n’a effectué qu’une seule action de clic, bien que Data Cloud l’interprète comme deux actions de clic.
Cette interprétation erronée peut créer un problème lorsque ces données sont interrogées, notamment dans la segmentation, les connaissances calculées et l’API de requête. Si vous exécutez une requête et demandez à trouver des individus qui ont effectué au moins deux clics, Individual 2 (Individu 2) est renvoyé dans la réponse. Ce problème se produit même lorsque l’unification des profils est déployée, car les données d’engagement sont toujours jointes à l’objet modèle de données Individual (Individu).
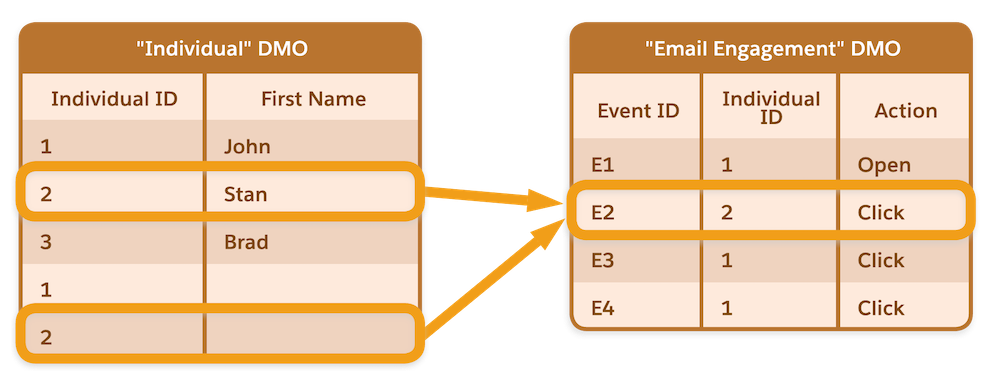
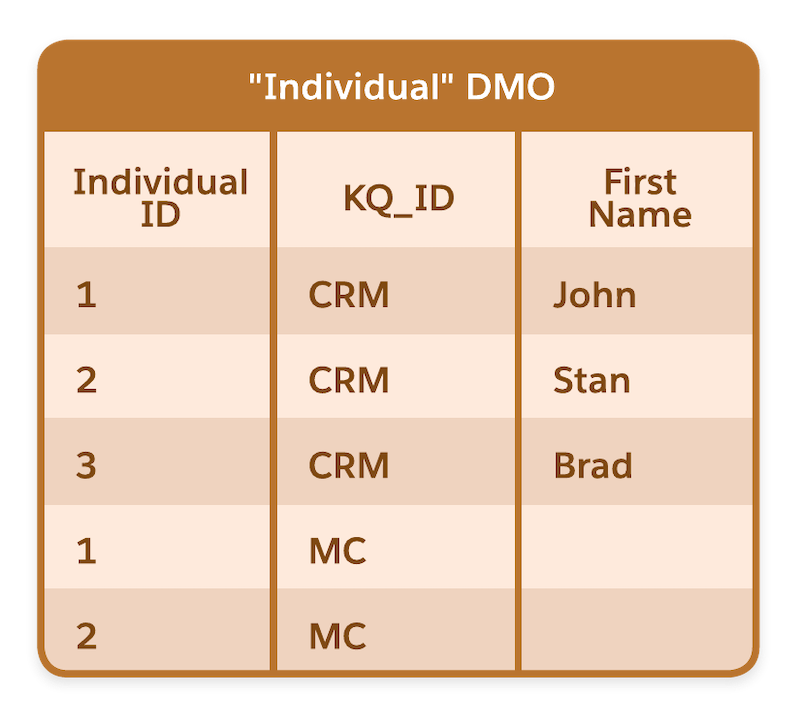
Lorsque vous ajoutez des champs de qualificateur de clé à tous vos champs objet lac de données qui contiennent une valeur de clé (clé principale ou clé étrangère), Data Cloud interprète correctement les données ingérées à partir de différentes sources de données. Dans cet exemple, des qualificateurs de clé sont ajoutés aux objets lac de données de Salesforce CRM et Marketing Cloud Engagement. L’objet modèle de données Individu comprend le champ de qualificateur de clé indiquant la provenance de l’enregistrement.
Lorsque les objets modèle de données Individual (Individu) et Email Engagement (Engagement par e-mail) sont joints, la jointure de tables utilise à la fois le champ de clé étrangère (ID d’individu) et le champ de qualificateur de clé (KQ_ID), ce qui permet à Data Cloud d’interpréter les données avec précision.

Lorsque vous exécutez la même requête pour des individus ayant effectué au moins deux clics, les données d’Individual 2 (Individu 2) ne répondent pas aux critères de requête et ne sont pas renvoyées dans la réponse à la requête. Utilisez des champs de qualificateur de clé dans les connaissances calculées, la segmentation et l’API de requête pour identifier, cibler et analyser les données client avec précision.
Modélisation de données
Nous avons mentionné qu’une fois tous les flux de données ingérés dans le système, il existe un système de mappage source-cible qui utilise le modèle de données Customer 360 pour normaliser les sources de données. Par exemple, vous pouvez utiliser la notion d’ID d’individu du modèle de données Customer 360 pour marquer le champ source correspondant à l’individu qui a acheté un appareil (un flux de données), appelé pour un problème de service (un autre flux de données), reçu un remplacement (encore un autre flux de données), puis pour examiner chaque événement du parcours client (oui, un autre flux de données). Le mappage des données vous aide à connecter les champs applicables dans les sources de données afin de lier l’ensemble. Portez une attention particulière aux attributs tels que les noms, les adresses e-mail et les numéros de téléphone (ou identificateurs similaires). Ces informations vous aident à lier les données d’un individu et, à terme, à créer un profil unifié du client. Chaque donnée a sa place et est liée à un autre élément : il suffit de connecter les deux.
Le modèle de données Customer 360 est conçu pour être extensible et permet d’ajouter davantage d’attributs personnalisés à un objet standard existant ou davantage d’objets personnalisés. Lorsque vous utilisez des objets standard, les relations entre ces objets sont mises automatiquement en évidence quand les champs reliant les deux objets sont tous deux mappés. Dans une unité ultérieure, nous vous présenterons un exemple de situation où vous devrez peut-être définir la relation entre les objets dans les cas où vous avez ajouté des objets personnalisés à votre modèle.
Maintenant que vous connaissez les concepts de base de l’ingestion et de la modélisation de données, vous êtes prêt à passer à des exemples concrets.